Už sme vám viackrát povedali, ako môžete sami zostaviť sémantické jadro stránky a dokonca napísať knihu (mimochodom, môžete si ju zadarmo stiahnuť). Predtým, ako sa pokúsite zhromaždiť kľúčové slová pomocou služieb uvedených v tomto článku, odporúčam vám prečítať si knihu, aby ste pochopili základy.
Proces zbierania sémantiky je obzvlášť pre začiatočníkov veľmi namáhavý a časovo náročný.
Existuje mnoho špecializovaných služieb a programov na zostavenie sémantického jadra. Najpopulárnejšie: Yandex.WordStat a Google KeywordPlanner, Key Collector, Slovoeb, Megaindex.com, SEMRush, Just Magic, Topvisor a ďalšie.
Mnoho z týchto produktov je platených a každý má svoje výhody a nevýhody. Ďalej sa podrobnejšie pozrieme na 2 pomocníkov na zhromažďovanie sémantiky stránok - jeden platený a druhý bezplatný.
Rush Analytics je online služba na vytváranie sémantického jadra
Umožňuje zautomatizovať všetky rutinné procesy pri zbere sémantiky: od výberu kľúčov po klastrovanie.
Klady:
- Nevyžaduje sa žiadna inštalácia softvéru.
- Intuitívne a jednoduché rozhranie.
- Dostupnosť sprievodcov pre používanie služby a tipy v každej fáze.
- V klastrových správach je veľa užitočných údajov, ktoré môžete použiť na vytváranie obsahu.
- Sémantické jadro môžete rozšíriť pomocou nástroja Search Cues.
Mínusy:
Z mínusov je možné poznamenať, že ide o úplne platenú službu. Len pri registrácii získate bonus 200 rubľov. Ak máte veľké množstvo práce, vyjde vás to draho. Napríklad zoskupenie jednej kľúčovej požiadavky stojí 50 kopejok.
Zhromažďovanie kľúčových slov
Po jednoduchej registrácii budú k dispozícii 4 nástroje na prácu s kľúčovými slovami: „Wordstat“, „Zhromažďovanie rád“, „Klastrovanie“ a „Kontrola Kľúčové slová».
Teraz môžete začať zbierať kľúčové slová, preto musíte vytvoriť nový projekt:
Na karte, ktorá sa otvorí, zadajte názov projektu a región:

Ďalším krokom sú nastavenia zbierky. Tu musíte vybrať, ako sa budú slová zhromažďovať:
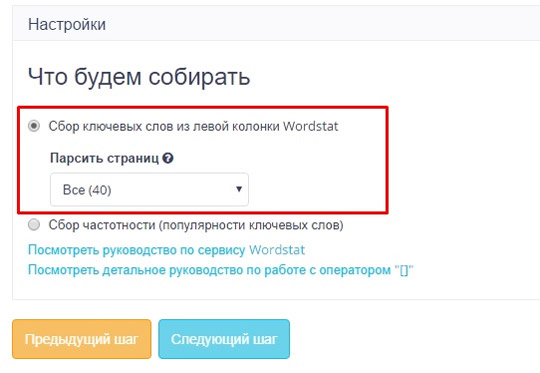
Pre prácu zvolíme prvú možnosť: zbieranie kľúčových slov z ľavého stĺpca programu Wordstat.
Tretím krokom sú Kľúčové slová a cena. Uvádzame základné kľúčové slová stránky buď v zozname, alebo nahráme súbor.
Máme napríklad stránku o prenájme špeciálneho vybavenia. Zadávame hlavné kľúče „prenájom špeciálneho zariadenia“, „prenájom žeriavu“, „servis žeriavu“. To bude stačiť na zozbieranie sémantiky.

Tiež uvádzame zastavovacie slová. Môžu vám pomôcť filtrovať zoznam a ušetriť čas i peniaze. K dispozícii je praktická funkcia „Zastaviť slová podľa témy“.
Pre náš web pridáme stop slová „zmluva“, „práca“.
Po chvíli bude náš projekt pripravený:

Teraz si môžete stiahnuť súbor vo formáte xlsx:

Získali sme pomerne veľký zoznam kľúčových slov (1084 slov). Niektoré z nich sú nadbytočné, takže je lepšie prejsť zoznamom a odstrániť nepotrebné slová.
Stanovenie frekvencie
Za týmto účelom vytvoríme nový projekt (uveďte názov a región), na druhej karte vyberte „Zhromažďovať frekvenciu“ a označte prvé tri možnosti:


Hneď ako sa zber frekvencií skončí, môžete si súbor stiahnuť. Pozrime sa, čo sa stalo. Už sme písali o tom, ako predpovedať návštevnosť podľa kľúčových slov, ak ste to ešte nečítali, prečítajte si to.
Poviem len, že neodporúčam používať atrapy žiadostí na propagáciu, t.j. slová, pre ktoré je frekvencia s operátormi „! Key“ rovná nule.
Zhlukovanie kľúčových slov
Klastrovanie je rozdelenie kľúčových slov do skupín z hľadiska logiky a na základe výsledkov vyhľadávacích nástrojov. Po distribúcii žiadostí do skupín dostanete v skutočnosti hotovú štruktúru stránok.
Ak to chcete urobiť, kliknite na „Zhlukovanie“ a vytvorte nový projekt:

Projekt nazývame „Spetstekhnika3“ (ľubovoľný názov podľa vášho výberu), vyberte vyhľadávací nástroj (vybrali sme Yandex), označte aj región:

Ďalším krokom je konfigurácia kolekcie. Najprv musíte vybrať typ algoritmu klastrovania. Tieto algoritmy fungujú na rovnakom princípe (porovnanie TOP vyhľadávacích nástrojov), ale sú navrhnuté tak, aby riešili rôzne problémy:
- Wordstat - Vhodné na vytváranie štruktúry stránok.
- Ručné značky - vhodné, ak už máte pripravenú štruktúru stránok a potrebujete kľúčové slová, pre ktoré musíte propagovať existujúce stránky.
- Kombinované (ručné značky + Wordstat) - vhodné na úlohu súčasného výberu kľúčových slov pre existujúcu štruktúru stránok a jej rozšírenia.
Tu uvádzame minimálnu frekvenciu, ktorú používame, a presnosť zoskupovania:

Čím vyššia je presnosť zoskupovania, tým viac kľúčov spadá do jednej skupiny. Pri blogoch a portáloch nie je presnosť taká dôležitá (môžete dať 3 alebo 4). Ale pre stránky s konkurenčnými témami je lepšie zvoliť vyššiu presnosť zoskupenia.
Ako vidíte na obrázku, vybrali sme všetky prijateľné presnosti zoskupenia. Náklady na klastrovanie to neovplyvní, ale budeme schopní určiť, ktorá skupina je pre nás vhodnejšia.
Pokračujeme do ďalšej fázy - stiahnutie súboru s kľúčovými slovami:

Výsledok klastrovania vo formáte xlsx vyzerá takto:

Na základe tohto súboru môžete zostaviť mapu relevancií, formulár TK pre copywriterov.
Program Slovoeb
Jeden z najlepších bezplatných programov na zostavovanie sémantického jadra. Mnohí ju nazývajú „mladším bratom zberateľa kľúčov“.
Klady:
- Program je úplne zadarmo.
- Prítomnosť tipov, popis programu a jeho nástrojov.
- Intuitívne rozhranie.
Mínusy:
- Vyžaduje inštaláciu na počítači.
- Neexistuje automatické zoskupovanie dopytov.
- Neexistujú žiadne aktualizácie programu.
Nastavenie programu
Môžete si objednať vývoj osnov a mapy (pozrite si časť „Optimalizácia a technická podpora“).
Dobré popoludnie priatelia.
Pravdepodobne ste už zabudli na chuť mojich článkov. Predchádzajúci materiál bol dosť dávno, aj keď som sľúbil publikovať články častejšie ako obvykle.
V poslednej dobe sa množstvo práce zvýšilo. Vytvoril som nový projekt (informačný web), zaoberal som sa jeho rozložením, návrhom, zozbieral sémantické jadro a začal som publikovať materiál.
Dnes bude k dispozícii veľmi objemný a dôležitý materiál pre tých, ktorí udržiavajú svoje stránky viac ako 6-7 mesiacov (v niektorých témach viac ako 1 rok), má veľký počet článkov (v priemere 100) a ešte nedosiahol latku najmenej 500-1 000 návštev za deň ... Čísla sú obmedzené na minimum.
Význam sémantického jadra
V niektorých prípadoch je zlý rast stránok spôsobený nesprávnou technickou optimalizáciou webu. Viac prípadov, keď je obsah nekvalitný. Existuje však ešte viac prípadov, keď sú texty napísané vôbec na požiadanie - nikto nepotrebuje materiály. Existuje však aj veľmi veľká časť ľudí, ktorí stránku vytvoria, všetko správne optimalizujú, píšu vysokokvalitné texty, ale po 5-6 mesiacoch stránka práve začína získavať prvých 20-30 návštevníkov z vyhľadávania. Pri malom tempe za rok je to už 100-200 návštevníkov a údaj o príjmoch je nulový.
A hoci bolo všetko urobené správne, nie sú tam žiadne chyby a texty sú niekedy dokonca niekoľkonásobne lepšie ako konkurencia, ale akosi to nefunguje, ako o život mňa. Začíname tento jamb odpisovať pre nedostatok odkazov. Odkazy samozrejme podporujú rozvoj, ale to nie je najdôležitejšie. A bez nich môžete mať stránku za 1000 mesiacov 1000 návštev.
Mnohí povedia, že je to všetko svinstvo a že také čísla len tak rýchlo nezískate. Ale ak sa pozrieme, potom sa tieto čísla nedosahujú presne na blogoch. Informačné weby (nie blogy), vytvorené s cieľom rýchleho zárobku a návratnosti investícií, za približne 3-4 mesiace celkom reálne dosiahnu dennú návštevnosť 1 000 ľudí a za rok 5 000-10 000. Čísla samozrejme závisia od konkurencieschopnosti výklenku, jeho objemu a objemu samotnej lokality za určené obdobie. Ak však vezmeme medzeru s pomerne malou konkurenciou a objemom 300-500 materiálov, potom sú tieto údaje za uvedený časový rámec celkom dosiahnuteľné.
Prečo práve blogy nedosahujú také rýchle výsledky? Hlavný dôvod je nedostatok sémantického jadra. Z tohto dôvodu sú články písané iba pre jeden druh požiadavky a takmer vždy pre veľmi konkurencieschopnú požiadavku, ktorá bráni tomu, aby sa stránka v krátkom čase dostala na TOP priečku.
Na blogoch sú články spravidla písané podľa podoby konkurencie. Máme 2 čitateľné blogy. Vidíme, že ich návštevnosť je slušná, začneme analyzovať ich mapu stránok a publikovať texty pre rovnaké otázky, ktoré už boli stokrát prepísané a sú veľmi konkurencieschopné. V dôsledku toho získavame na stránke veľmi kvalitný obsah, ale vo vyhľadávaní sa cíti zle, pretože vyžaduje veľa veku. Búchame si do hlavy, prečo je môj obsah najlepší, ale nedostane sa do TOP?
Preto som sa rozhodol napísať podrobný materiál o sémantickom jadre stránky, aby ste pre seba mohli zozbierať zoznam žiadostí a čo je veľmi dôležité, napísať texty pre také skupiny kľúčových slov, ktoré bez nákupu odkazov a iba v 2- 3 mesiace išli do TOP (samozrejme, ak kvalitného obsahu).
Materiál bude pre väčšinu náročný, ak ste sa s týmto problémom nikdy nestretli správnym spôsobom. Ale tu je hlavná vec začať. Hneď ako začnete konať, je vám všetko hneď jasné.
Urobím veľmi dôležitú vec. Týka sa tých, ktorí nie sú pripravení investovať do kvality svojimi ťažko zarobenými mincami a vždy sa pokúšajú nájsť voľné medzery. Sémantiku nemôžete zbierať zadarmo a je to dobre známy fakt. Preto v tomto článku popisujem proces zberu sémantiky maximálnej kvality. Nie bezplatné cesty alebo v tomto príspevku nebudú žiadne medzery! Určite bude nový príspevok, kde vám poviem o bezplatných a iných nástrojoch, pomocou ktorých môžete zbierať sémantiku, ale nie v úplnom rozsahu a bez náležitej kvality. Preto, ak nie ste pripravení investovať do základov svojho webu, potom je tento materiál pre vás zbytočný!
Napriek tomu, že takmer každý bloger o tom napíše článok. jadro, môžem s istotou povedať, že na internete neexistujú žiadne normálne bezplatné návody na túto tému. A ak existuje, potom neexistuje nikto, kto by na úplnom obrázku poskytol predstavu o tom, čo by malo byť výsledkom.
Situácia sa najčastejšie končí skutočnosťou, že nejaký nováčik píše materiál a hovorí o zhromažďovaní sémantického jadra, o použití služby na zhromažďovanie štatistík vyhľadávacích dotazov z Yandexu (wordstat.yandex.ru). Nakoniec musíte ísť na tento web, zadať požiadavky na svoju tému, služba vám poskytne zoznam fráz zahrnutých do vášho klepaného kľúča - to je celá technika.
V skutočnosti však sémantické jadro nie je zostavené tak. V prípade popísanom vyššie jednoducho nebudete mať sémantické jadro. Dostanete nejaký druh odtrhnutých žiadostí a všetky budú o tom istom. Zoberme si napríklad výklenok pre moju stránku.
Aké hlavné otázky môžete bez váhania pomenovať? Tu je len niekoľko:
- Ako vytvoriť webovú stránku;
- Propagácia webových stránok;
- Vývoj webových stránok;
- Propagácia webových stránok atď.
Žiadosti sa prijímajú o tej istej veci. Ich význam je redukovaný iba na 2 koncepty: vytvorenie a propagácia webu.
Po takejto kontrole služba wordstat rozdá veľa vyhľadávacích dopytov, ktoré sú zahrnuté v hlavných dotazoch, a budú tiež zhruba rovnaké. Ich jediný rozdiel bude v zmenených slovných formách (pridanie niektorých slov a zmena usporiadania slov v dotaze s meniacimi sa koncovkami).
Samozrejme, budete môcť napísať určitý počet textov, pretože požiadavky sa môžu líšiť aj v tejto verzii. Napríklad:
- Ako vytvoriť webovú stránku WordPress;
- Ako vytvoriť webovú stránku joomla;
- Ako vytvoriť webovú stránku na bezplatnom hostingu;
- Ako propagovať stránku zadarmo;
- Ako propagovať webovú stránku, službu atď.
Pre každú požiadavku je zrejmé, že môže byť pridelený samostatný materiál. Ale taká kompilácia sémantického jadra stránky nebude korunovaná úspechom, tk. vo vybranom výklenku nebude na webe úplnosť zverejnenia informácií. Celý obsah bude obsahovať iba 2 témy.
Začínajúci blogeri niekedy popisujú proces zostavovania sémantického jadra ako analýzu jednotlivých dotazov v službe na analýzu dotazov Yandex Wordstat. Prejdeme v nejakej samostatnej požiadavke, ktorá sa netýka témy ako celku, ale iba konkrétneho článku (napríklad ako optimalizovať článok), dostaneme k nemu frekvenciu a tu to je - sémantické jadro je zostavený. Ukazuje sa, že týmto spôsobom musíme mentálne identifikovať všetky druhy tém článkov a analyzovať ich.
Obe vyššie uvedené možnosti sú nesprávne, pretože nedávajte úplné sémantické jadro a ste nútení sa neustále vracať k jeho kompilácii (druhá možnosť). Navyše nebudete mať v rukách vektor vývoja stránok a nebudete môcť publikovať materiály na prvom mieste, ktoré by malo byť umiestnené medzi prvými.
Pokiaľ ide o prvú možnosť, pri nákupe kurzov na propagáciu webových stránok som neustále videl presne také vysvetlenie pre zhromažďovanie jadra požiadaviek na web (zadajte hlavný kľúč a skopírujte všetky požiadavky zo služby na Textový dokument). Výsledkom bolo, že ma neustále mučila otázka „Čo robiť s takýmito požiadavkami?“ Napadlo ma nasledujúce:
- Napíšte veľa článkov o tej istej veci, ale pomocou rôznych kľúčových slov;
- Všetky tieto kľúče by ste mali zadať do popisného poľa pre každý materiál;
- Z tohto zadajte všetky kľúče. jadrá v poli všeobecného popisu pre celý zdroj.
Žiadny z týchto predpokladov nebol pravdivý, pretože vo všeobecnosti ide o veľmi zostavené sémantické jadro stránky.
O konečnej verzii zbierky sémantického jadra by sme nemali dostať napríklad iba zoznam žiadostí vo výške 10 000, ale mať k dispozícii aj zoznam skupín požiadaviek, z ktorých sa každá používa na samostatný článok. .
Skupina môže obsahovať 1 až 20-30 žiadostí (niekedy 50 alebo dokonca viac). V tomto prípade v texte používame všetky tieto dopyty a stránka z dlhodobého hľadiska privedie návštevnosť na všetky dopyty každý deň, ak sa vo vyhľadávaní dostane na 1-3 pozície. Okrem toho každá skupina musí mať svoju vlastnú súťaž, aby vedela, či má zmysel text na nej teraz publikovať alebo nie. Ak je veľká konkurencia, potom môžeme účinok stránky očakávať až po 1-1,5 roku a pravidelnej práci na jej propagácii (odkazy, odkazy atď.). Preto je lepšie zamerať sa na také texty ako na poslednú vec, aj keď sú najnavštevovanejšie.
Odpovede na možné otázky
Otázka číslo 1. Je zrejmé, že na výstupe dostaneme skupinu požiadaviek na písanie textu, a nie iba jeden kľúč. V takom prípade nebudú kľúče navzájom podobné a prečo pre každú požiadavku nenapíšete samostatný text?
Otázka číslo 2. Je známe, že každá stránka by mala byť zaostrená iba na jedno kľúčové slovo, ale tu dostaneme celú skupinu a dokonca v niektorých prípadoch aj s pomerne veľkým obsahom požiadaviek. Ako je v tomto prípade optimalizácia samotného textu, pretože ak napríklad klávesy 20, potom použitie každého aspoň raz v texte (dokonca veľká veľkosť) už vyzerá ako text pre vyhľadávací nástroj, nie pre ľudí.
Odpoveď. Ak vezmeme príklad žiadostí z predchádzajúcej otázky, potom prvá vec na zaostrenie materiálu bude presne pre najčastejšiu (1.) požiadavku, pretože nás najviac zaujíma, aby dosiahol najvyššie pozície. Tento kľúč považujeme za hlavný v tejto skupine.
Optimalizácia hlavnej kľúčovej frázy prebieha rovnakým spôsobom ako pri písaní textu iba jedným kľúčom (kľúč v názve názvu, použitie správne množstvo znakov v texte a požadovaný počet opakovaní samotného kľúča, ak je to potrebné).
Pokiaľ ide o ostatné kľúče, zadávame ich tiež, ale nie slepo, ale na základe rozboru konkurencie, ktorý môže v textoch od TOP ukazovať priemernú hodnotu počtu týchto kľúčov. Môže sa stať, že pre väčšinu kľúčových slov získate nulové hodnoty, čo znamená, že ich netreba používať v presnom zadaní.
Text je teda napísaný iba pomocou hlavného dopytu v texte v priamom. Samozrejme, môžu byť použité aj ďalšie otázky, ak analýza konkurencie ukazuje ich prítomnosť v textoch od TOP. Nie je to však 20 kľúčových slov v texte v ich presnom výskyte.
Najnovšie som publikoval materiál pre skupinu 11 kľúčov. Zdá sa, že existuje veľa dopytov, ale na obrázku nižšie vidíte, že presný výskyt má iba hlavný najčastejší kľúč - 6 -krát. Ostatné kľúčové frázy nemajú presný výskyt, ale ani zriedený výskyt (na obrázku nie je viditeľný, ale ukazuje sa to pri analýze konkurencie). Títo. vôbec sa nepoužívajú.
(1. stĺpec - frekvencia, 2. - súťaž, 3. - počet zobrazení)
Vo väčšine prípadov dôjde k podobnej situácii, keď pri presnom výskyte bude potrebné použiť iba niekoľko kľúčov a všetky ostatné častice budú buď silne zriedené, alebo sa vôbec nepoužijú, dokonca ani pri zriedenom výskyte. Článok sa ukazuje ako čitateľný a neexistujú žiadne náznaky doostrenia iba pre vyhľadávanie.
Otázka číslo 3. Vyplýva to z odpovede na otázku č. 2. Ak ostatné kľúče v skupine nie je potrebné použiť vôbec, ako potom budú prijímať návštevnosť?
Odpoveď. Faktom je, že podľa prítomnosti určitých slov v texte môže vyhľadávací nástroj určiť, o čom text je. Pretože v kľúčových slovách sú určité samostatné slová, ktoré sa týkajú iba tohto kľúča, je potrebné ich v texte použiť niekoľkokrát, na základe rovnakej analýzy konkurencie.
Kľúč teda nebude použitý v presnom výskyte, ale slová z kľúča oddelene v texte budú prítomné a tiež sa zúčastnia hodnotenia. V dôsledku toho bude pre tieto dotazy vo vyhľadávaní aj text. Ale počet jednotlivých slov v tomto prípade v ideálnom prípade treba dodržať. Súťažiaci pomôžu.
Odpovedal som na hlavné otázky, ktoré vás môžu priviesť do strnulosti. Podrobnejšie informácie o tom, ako optimalizovať text pre skupiny požiadaviek, napíšem v jednom z nasledujúcich materiálov. Bude to o analýze konkurencie a o samotnom napísaní textu pre skupinu kľúčov.
Ak máte ďalšie otázky, opýtajte sa ich. Na všetko odpoviem.
Teraz začneme zostavovať sémantické jadro webu.
Veľmi dôležité. Celý proces, ako v skutočnosti je, nemôžem v tomto článku nijako popísať (budem musieť urobiť celý webinár na 2-3 hodiny alebo minikurz), takže sa pokúsim byť stručný, ale na súčasne informatívne a dotknite sa maximálna čiastka momenty. Nebudem napríklad podrobne popisovať konfiguráciu softvéru KeyCollector. Všetko bude obmedzené, ale čo najjasnejšie.
Teraz si prejdeme každú položku. Začnime. Príprava ako prvá.
Čo je potrebné na zhromaždenie sémantického jadra?

Pred zostavením sémantického jadra webu nakonfigurujeme kolektor kľúčov pre správny zber štatistík a analýzu požiadaviek.
Nastavenie programu KeyCollector
Nastavenia môžete zadať kliknutím na ikonu v hornom menu softvéru.

Najprv o analýze.
Chcel by som poznamenať nastavenia „Počet streamov“ a „Použiť primárnu adresu IP“. Počet vlákien na zhromaždenie jedného malého jadra nepotrebuje veľa. 2-4 vlákna stačia. Čím viac streamov, tým viac serverov proxy potrebujete. Ideálne 1 proxy na vlákno. Môžete však mať aj 1 proxy server pre 2 streamy (takto som analyzoval).
Pokiaľ ide o druhé nastavenie, v prípade analýzy v 1-2 prúdoch môžete použiť svoju hlavnú adresu IP. Ale iba vtedy, ak je dynamický, pretože ak je statická adresa IP zakázaná, stratíte prístup k vyhľadávaciemu nástroju Yandex. Napriek tomu je vždy prioritou používanie servera proxy, pretože je lepšie sa chrániť.
Na karte nastavení analýzy Yandex.Direct je dôležité pridať svoje účty Yandex. Čím viac ich bude, tým lepšie. Môžete ich zaregistrovať sami alebo kúpiť, ako som už písal. Kúpil som ich, pretože je pre mňa jednoduchšie minúť 100 rubľov za 30 účtov.
Pridanie je možné z vyrovnávacej pamäte skopírovaním zoznamu účtov do požadovaný formát alebo načítajte zo súboru.
Účty musia byť zadané vo formáte „prihlásenie: heslo“, pričom samotný hostiteľ nesmie byť uvedený v prihlásení (bez @ yandex.ru). Napríklad „artem_konovalov: jk8ergvgkhtf“.
Ak používame niekoľko serverov proxy, je lepšie ich priradiť ku konkrétnym účtom. Bude podozrivé, ak najskôr žiadosť pochádza z jedného servera a z jedného účtu a pri ďalšej žiadosti z rovnakého účtu Yandex je server proxy už iný.
Vedľa účtov je stĺpec „IP proxy“. Pred každý účet zadáme konkrétny server proxy. Ak existuje 20 účtov a 2 proxy, bude existovať 10 účtov s jedným proxy a 10 s druhým. Ak existuje 30 účtov, potom 15 s jedným serverom a 15 s iným. Logika, myslím, že rozumieš.
Ak používame iba jeden server proxy, nemá zmysel ho pridávať do každého účtu.
O počte vlákien a použití hlavnej IP adresy som hovoril o niečo skôr.
Ďalšou kartou je „Sieť“, kde musíte zadať proxy servery, ktoré sa použijú na analýzu.
Server proxy musíte zadať v spodnej časti karty. Môžete ich načítať zo schránky v požadovanom formáte. Pridal som jednoduchým spôsobom. Do každého stĺpca riadka som zadal údaje o serveri, ktoré ste dostali pri kúpe.
Ďalej nakonfigurujeme parametre exportu. Pretože potrebujeme dostať všetky požiadavky s ich frekvenciami do súboru v počítači, musíme nastaviť niektoré parametre exportu, aby v tabuľke nebolo nič nadbytočné.
V spodnej časti karty (zvýraznená červenou farbou) musíte vybrať údaje, ktoré chcete exportovať do tabuľky:
- Fráza;
- Zdroj;
- Frekvencia "!" ;
- Najlepšia forma frázy (nemusíte).
Zostáva len nastaviť riešenie anti-captcha. Toto je názov karty - „Anticaptcha“. Vyberieme službu, ktorá sa má použiť, a zadáme špeciálny kľúč, ktorý sa nachádza v účte služby.
Špeciálny kľúč na prácu so službou je uvedený v liste po registrácii, ale môžete ho prevziať aj zo samotného účtu v položke „Nastavenia - nastavenia účtu“.
Tým sú nastavenia KeyCollector dokončené. Po vykonaných zmenách nezabudnite uložiť nastavenia kliknutím na veľké tlačidlo v spodnej časti „Uložiť zmeny“.
Keď je všetko hotové a sme pripravení na analýzu, môžeme začať zvažovať fázy zhromažďovania sémantického jadra a potom postupne prejsť každou fázou.
Fázy zhromažďovania sémantického jadra
Nie je možné získať vysokokvalitné a úplné sémantické jadro iba pomocou základných dopytov. Musíte tiež analyzovať požiadavky a materiály konkurencie. Celý proces zostavovania jadra preto pozostáva z niekoľkých etáp, ktoré sú tiež ďalej rozdelené na čiastkové fázy.
- Základ;
- Analýza konkurencie;
- Rozšírenie hotového zoznamu z etáp 1-2;
- Zbierka najlepších slovných foriem pre otázky z fáz 1-3.
Fáza 1 - základ
Počas zberu jadra v tejto fáze potrebujete:
- Vytvorte základný zoznam špecifických požiadaviek;
- Rozšírenie týchto dopytov;
- Čistenie.
2. fáza - súťažiaci
V zásade stupeň 1 už dáva určité množstvo jadra, ale nie v plnom rozsahu, pretože niečo nám asi chýba. A konkurenti v našom výklenku pomôžu nájsť zmeškané diery. Tu sú kroky na dokončenie:
- Zhromažďovanie konkurentov na základe požiadaviek z etapy 1;
- Analýza požiadaviek konkurencie (analýza mapy webu, otvorené štatistiky live internetu, analýza domén a konkurencie v SpyWords);
- Čistenie.
3. fáza - rozšírenie
Mnoho ľudí sa zastaví v prvej fáze. Niekto dosiahne 2. miesto, ale existuje aj množstvo ďalších dotazov, ktoré môžu tiež doplniť sémantické jadro.
- Kombinujeme požiadavky z 1-2 fáz;
- Ponecháme 10% najčastejších slov z celého zoznamu, ktoré obsahujú najmenej 2 slová. Je dôležité, aby týchto 10% nebolo viac ako 100 fráz, pretože veľké množstvo vás prinúti ponoriť sa hlboko do procesu zhromažďovania, čistenia a zoskupovania. Potrebujeme vybudovať jadro v pomere rýchlosť / kvalita (minimálna strata kvality pri maximálnej rýchlosti);
- Tieto požiadavky rozširujeme pomocou služby Rookee (všetko je v KeyCollector);
- Čistíme.
Fáza 4 - zbieranie najlepších slovných foriem
Služba Rookee môže určiť najlepšiu (správnu) formu slova pre väčšinu dotazov. Toto by sa tiež malo použiť. Cieľom nie je určiť slovo, ktoré je správnejšie, ale nájsť ďalšie otázky a ich formy. Môžete teda vytiahnuť ďalší súbor požiadaviek a použiť ich pri písaní textov.
- Kombinácia dotazov z prvých 3 etáp;
- Zhromažďovanie najlepších slovných foriem na nich;
- Pridanie najlepších slovných foriem do zoznamu pre všetky otázky, kombinované od fáz 1-3;
- Čistenie;
- Export hotového zoznamu do súboru.
Ako vidíte, všetko nie je také rýchle a ešte k tomu ani také jednoduché. Toto som načrtol iba normálny plán na kompiláciu jadra, aby ste na výstupe získali vysokokvalitný zoznam kľúčov a nič, čo by ste mohli stratiť alebo stratiť na minimum.
Teraz navrhujem prejsť každú položku zvlášť a preštudovať si všetko od A po Z. Informácií je veľa, ale stojí to za to, ak potrebujete skutočne kvalitné sémantické jadro stránky.
Fáza 1 - základ
Najprv vytvoríme zoznam hlavných vyhľadávacích dotazov. Obvykle sú to 1-3 slovné frázy, ktoré opisujú konkrétny problém. Ako príklad navrhujem vziať medzeru „Medicína“ a konkrétnejšie - znížiť srdcové choroby.
Aké hlavné požiadavky môžeme zdôrazniť? Samozrejme, nebudem písať všetko, ale dám pár.
- Ochorenie srdca
- Infarkt;
- Ischémia srdca;
- Arytmia;
- Hypertenzia;
- Ochorenie srdca;
- Angina pectoris atď.
Jednoducho povedané, toto sú bežné názvy chorôb. Takýchto požiadaviek môže byť veľa. Čím viac toho dokážete, tým lepšie. Ale nepíšte to na ukážku. Nemá zmysel písať konkrétnejšie frázy zo všeobecných, napríklad:
- Arytmia;
- Spôsobuje arytmiu;
- Liečba arytmie;
- Príznaky arytmie.
Hlavná je iba prvá veta. Zvyšok nemá zmysel, pretože objavia sa v zozname počas rozšírenia analýzou z ľavého stĺpca programu Yandex Wordstat.
Na hľadanie bežných fráz môžete použiť stránky konkurencie (mapa webu, názvy sekcií ...) a skúsenosti odborníka v tejto oblasti.

Analýza bude nejaký čas trvať, v závislosti od počtu dotazov vo výklenku. Všetky dotazy sú predvolene umiestnené do novej skupiny s názvom „Nová skupina 1“, pokiaľ sa nezmení pamäť. Skupiny väčšinou premenujem, aby som vedel, kto je za čo zodpovedný. Ponuka správy skupiny sa nachádza napravo od zoznamu požiadaviek.
Funkcia premenovania je v kontextovom menu po kliknutí pravým tlačidlom myši. Toto menu budete potrebovať na vytvorenie ďalších skupín v druhej, tretej a štvrtej fáze.
Preto môžete ihneď pridať ďalšie 3 skupiny kliknutím na prvú ikonu „+“, aby sa skupina vytvorila v zozname bezprostredne za predchádzajúcou. Zatiaľ k nim netreba nič dodávať. Nechaj to tak.
Skupiny som nazval takto:
- Konkurenti - je zrejmé, že táto skupina obsahuje zoznam požiadaviek, ktoré som zhromaždil od konkurencie;
- 1-2 je kombinovaný zoznam požiadaviek z 1. (hlavný zoznam žiadostí) a 2. (požiadavky konkurencie) fáz, aby z nich zostalo iba 10%, pozostávajúcich z najmenej 2 slov, a zhromaždili pre ne rozšírenia;
- 1-3 - kombinovaný zoznam požiadaviek z prvej, druhej a tretej (rozšírenia) etapy. Zhromažďujeme aj najlepšie slovné formy v tejto skupine, aj keď by bolo gramotnejšie ich zhromaždiť do novej skupiny (napríklad najlepšie slovné formy) a potom ich po vyčistení preniesť do skupiny 1-3.
Po dokončení analýzy z yandex.wordstat získate veľký zoznam kľúčových fráz, ktoré sa spravidla (ak je medzera malá) budú nachádzať v rozmedzí niekoľkých tisíc. Veľa z toho sú odpadky a atrapy požiadaviek a budú musieť byť vyčistené. Niečo automaticky odfiltrujeme pomocou funkcionality KeyCollector, ale budeme musieť niečo pohnúť rukami a chvíľu si sadnúť.
Keď sú zhromaždené všetky žiadosti, musíte zhromaždiť ich presnú frekvenciu. Celková frekvencia sa zhromažďuje počas analýzy, ale presnú frekvenciu je potrebné zhromaždiť oddelene.
Na zhromažďovanie štatistík o počte zobrazení môžete použiť dve funkcie:
- S pomocou Yandex Direct - štatistiky sa rýchlo zbierajú v dávkach, ale existujú obmedzenia (napríklad frázy viac ako 7 slov nebudú zavedené ani so symbolmi);
- Pomocou analýzy v Yandex Wordstat - veľmi pomaly sa frázy analyzujú jednotlivo, ale neexistujú žiadne obmedzenia.
Najprv zbierajte štatistiky pomocou Yandex.Direct, aby bola čo najrýchlejšia, a pre tie frázy, pre ktoré nebolo možné určiť štatistiku pomocou Direct, už používame Wordstat. Spravidla bude takýchto fráz málo a budú sa rýchlo zbierať.
Zhromažďovanie štatistík zobrazovania pomocou Yandex.Direct sa vykonáva kliknutím na zodpovedajúce tlačidlo a priradením požadovaných parametrov.
Po kliknutí na tlačidlo „Získať údaje“ sa môže zobraziť upozornenie, že Yandex Direct nie je v nastaveniach povolený. Ak chcete začať určovať štatistiku frekvencie, budete musieť súhlasiť s aktiváciou analýzy pomocou Yandex.Direct.
V dávkach v stĺpci „Frekvencia! »Začnú sa presné ukazovatele zobrazení pre každú frázu.
Priebeh úlohy je možné vidieť na karte „Štatistiky“ v spodnej časti programu. Po dokončení úlohy sa na karte „Denník udalostí“ zobrazí upozornenie na dokončenie a indikátor priebehu na karte „Štatistiky“ zmizne.
Po zhromaždení počtu zobrazení pomocou Yandex Direct skontrolujeme, či existujú frázy, pre ktoré nebola zhromaždená frekvencia. Aby sme to urobili, zoradíme stĺpček „Frekvencia!“ (kliknite naň) tak, aby najnižšie alebo najvyššie hodnoty boli hore.
Ak sú hore všetky nuly, potom sa zhromaždia všetky frekvencie. Ak existujú prázdne bunky, potom neboli pre tieto frázy dojmy určené. To isté platí pre triedenie podľa zabíjania, len potom sa budete musieť pozrieť na výsledok úplne dole v zozname požiadaviek.
Môžete tiež začať zbierať pomocou Yandex Wordstat kliknutím na ikonu a výberom požadovaného parametra frekvencie.

Po zvolení typu frekvencie uvidíte, ako sa prázdne bunky začnú postupne zapĺňať.
Dôležité: Nebojte sa, ak po ukončení postupu zostanú prázdne bunky. Faktom je, že budú prázdne, ak je ich presná frekvencia menšia ako 30. Nastavili sme to v nastaveniach analýzy v Keycollector. Tieto frázy je možné bezpečne vybrať (rovnako ako bežné súbory v programe Windows Prieskumník) a odstrániť. Frázy budú zvýraznené modrou farbou, stlačte pravé tlačidlo myši a zvoľte „Odstrániť vybrané riadky“.
Keď sú zhromaždené všetky štatistiky, môžete začať s čistením, ktoré je veľmi dôležité vykonať v každej fáze zhromažďovania sémantického jadra.
Hlavnou úlohou je odstrániť frázy, ktoré s témou nesúvisia, odstrániť frázy so stopkami a zbaviť sa príliš nízkofrekvenčných dopytov.
Posledne menované v ideálnom prípade nie je potrebné vykonávať, ale ak ho zostavujeme. používajte frázy aj s minimálnou frekvenciou 5 zobrazení za mesiac, potom sa tým zvýši jadro o 50-60 percent (a možno všetkých 80%) a prinúti nás to kopať hlboko. Musíme dosiahnuť maximálnu rýchlosť s minimálnymi stratami.
Ak chceme získať čo najkompletnejšie sémantické jadro stránky, ale zároveň ho zbierať asi mesiac (nie sú žiadne skúsenosti), potom vezmite frekvencie od 4 do 5 mesačných zobrazení. Je však lepšie (ak ste začiatočník) nechať žiadosti, ktoré majú aspoň 30 zobrazení za mesiac. Áno, trochu stratíme, ale toto je cena za maximálnu rýchlosť. A už v priebehu rastu projektu bude možné tieto požiadavky prijímať znova a používať ich na písanie nových materiálov. A to všetko len za predpokladu, že toto všetko. jadro je už napísané a neexistujú žiadne témy pre články.
Filtrovanie požiadaviek podľa počtu ich zobrazení a ďalších parametrov umožňuje rovnakému zberateľovi kľúčov plne automaticky. Spočiatku odporúčam urobiť len to a nevymazávať nepotrebné frázy a frázy so zarážkami. bude to oveľa jednoduchšie, keď sa celkový objem jadra v tejto fáze stane minimálnym. Čo je jednoduchšie, lopotiť 10 000 fráz alebo 2 000?
Prístup k filtrom je na karte „Údaje“ kliknutím na tlačidlo „Upraviť filtre“.

Odporúčam vám najskôr zobraziť všetky dotazy s frekvenciou menšou ako 30 a presunúť ich do novej skupiny, aby ste ich neodstránili, pretože môžu byť v budúcnosti užitočné. Ak jednoducho použijeme filter na zobrazenie fráz s frekvenciou viac ako 30, potom po nasledujúcom spustení programu KeyCollector budeme musieť znova použiť ten istý filter, pretože všetko je resetované. Filter môžete samozrejme uložiť, ale stále ho musíte použiť a neustále sa vracať na kartu Údaje.
Aby sme sa pred týmito akciami zachránili, pridáme do editora filtrov podmienku, aby sa zobrazovali iba frázy s frekvenciou menšou ako 30.



V budúcnosti môžete vybrať filter kliknutím na šípku vedľa ikony diskety.
Po použití filtra teda v zozname dopytov zostanú iba frázy s frekvenciou nižšou ako 30, t.j. 29 a nižšie. Filtrovaný stĺpec je tiež farebne zvýraznený. V nižšie uvedenom príklade uvidíte iba frekvenciu 30, pretože Všetko to uvádzam na príklade, jadro je už pripravené a všetko je vyčistené. Tomu nevenujte pozornosť. Všetko by malo byť tak, ako popisujem v texte.

Na prenos je potrebné vybrať všetky frázy v zozname. Kliknite na prvú frázu, posuňte sa na koniec zoznamu, podržte kláves Shift a raz kliknite na poslednú frázu. Všetky frázy sú teda zvýraznené a označené modrým pozadím.
Zobrazí sa malé okno, v ktorom musíte vybrať presun.
Teraz môžete filter odstrániť zo stĺpca frekvencie, aby zostali iba dotazy s frekvenciou 30 a vyššou.

Dokončili sme určitú fázu automatického čistenia. Potom sa musíte pohrať s odstraňovaním nepotrebných fráz.
Najprv navrhujem špecifikovať zastavovacie slová, aby sa odstránili všetky frázy s ich prítomnosťou. V ideálnom prípade sa to samozrejme robí okamžite vo fáze analýzy, aby sa nedostali do zoznamu, ale to nie je kritické, pretože vymazanie zastavovacích slov prebieha automaticky pomocou Keycollector.
Hlavná ťažkosť spočíva v zostavení zoznamu zastavovacích slov, pretože pre každú tému sú iné. Preto nie je také dôležité, či by sme čistenie začiatočných slov urobili na začiatku alebo teraz, pretože stojí za to nájsť všetky zastavovacie slová, a je to výnosný biznis, a nie taký rýchly.
Na internete nájdete všeobecné zoznamy, ktoré obsahujú najbežnejšie slová ako „abstraktné, bezplatné, sťahovanie, p ... rno, online, obrázok atď.“.
Najprv navrhujem použiť všeobecný zoznam na ďalšie zníženie počtu fráz. Na karte „Zhromažďovanie údajov“ kliknite na tlačidlo „Zastaviť slová“ a pridajte ich do zoznamu.
V tom istom okne kliknutím na tlačidlo „Označiť frázy v tabuľke“ označíte všetky frázy obsahujúce zadané stop slová. Je však potrebné, aby bol celý zoznam fráz v skupine nezaškrtnutý, aby po stlačení tlačidla zostali označené iba frázy so stopkami. Odznačenie všetkých fráz je veľmi jednoduché.

Keď sú k dispozícii iba označené frázy so stopkami, buď ich odstránime, alebo ich prenesieme do novej skupiny. Vymazal som to prvýkrát, ale stále je dôležitejšie vytvoriť skupinu „So stop“ a presunúť do nej všetky nepotrebné frázy.
Po vyčistení bolo fráz ešte menej. Ale to nie je všetko, pretože každopádne nám niečo chýbalo. Stop slová samotné aj frázy, ktoré nesúvisia so zameraním nášho webu. Môžu to byť komerčné požiadavky, pre ktoré nemôžete písať texty, alebo môžete písať, ale nesplnia očakávania používateľa.
Príklady takýchto dotazov môžu súvisieť so slovom „kúpiť“. Iste, keď používateľ hľadá niečo s týmto slovom, už sa chce dostať na stránku, kde ho predáva. Na takúto frázu napíšeme text, ale návštevník ju nebude potrebovať. Preto takéto žiadosti nepotrebujeme. Hľadáme ich ručne.
Pomaly a opatrne prechádzame zvyškom zoznamu požiadaviek až na úplný koniec, hľadáme také frázy a objavujeme nové stop slová. Ak nájdete slovo, ktoré je použité mnohokrát, jednoducho ho pridajte do existujúceho zoznamu zastavovacích slov a kliknite na tlačidlo „Označiť frázy v tabuľke“. Na konci zoznamu, keď sme počas manuálnej kontroly označili všetky nepotrebné požiadavky, označené frázy odstránime a prvá etapa zostavovania sémantického jadra je na konci.
Získali sme určité sémantické jadro. Ešte nie je úplne dokončený, ale už vám umožní napísať čo najviac textu.
Zostáva len pridať k tomu malú časť požiadaviek, ktoré sme mohli zmeškať. Nasledujúce kroky vám s tým pomôžu.
Fáza 2 – konkurenti
Na úplnom začiatku sme zostavili zoznam bežných fráz súvisiacich s výklenkom. V našom prípade to boli tieto:
- Ochorenie srdca
- Infarkt;
- Ischémia srdca;
- Arytmia;
- Hypertenzia;
- Ochorenie srdca;
- Angina pectoris atď.
Všetky sa špecificky týkajú výklenku „Srdcová choroba“. Pre tieto frázy je potrebné pri vyhľadávaní nájsť stránky konkurencie na túto konkrétnu tému.
Jazdíme v každej z fráz a hľadáme konkurenciu. Je dôležité, aby tieto neboli obecné tematické (v našom prípade lekárske stránky všeobecnej orientácie, t.j. o všetkých chorobách). Potrebujeme špeciálne projekty. V našom prípade iba o srdci. No, možno aj o plavidlách, tk. srdce je spojené s cievnym systémom. Myšlienka, myslím, že rozumieš.
Ak máme výklenok „Recepty na šaláty s mäsom“, tak z dlhodobého hľadiska sa budú hľadať iba také stránky. Ak tam nie sú, skúste nájsť stránky iba o receptoch, a nie všeobecne o varení, kde je všetko o všetkom.
Ak je všeobecná tematická stránka (všeobecná lekárska, ženská, o všetkých druhoch stavieb a opráv, varenia, športu), budete musieť veľa trpieť, pokiaľ ide o zostavovanie samotného sémantického jadra, tk. budete musieť dlho a únavne orať - zozbierajte hlavný zoznam požiadaviek, dlho počkajte na proces analýzy, vyčistite a zoskupte.
Ak na 1., niekedy dokonca ani na 2. strane nie je možné nájsť úzke tematické stránky konkurentov, skúste použiť nie základné otázky, ktoré sme vytvorili pred samotnou analýzou v 1. fáze, ale dotazy z celého zoznam po analýze. Napríklad:
- Ako liečiť arytmiu ľudovými prostriedkami;
- Príznaky arytmie u žien a tak ďalej.
Faktom je, že takéto požiadavky (arytmia, srdcové choroby, srdcové choroby ...) majú najvyššiu konkurencieschopnosť a je takmer nemožné sa pre nich dostať do TOP. Preto na prvých pozíciách, a možno aj na stránkach, celkom realisticky nájdete iba obecné tematické portály o všetkom vzhľadom na ich obrovskú autoritu v očiach vyhľadávacích nástrojov, veku a hmotnosti odkazov.
Preto má zmysel používať frázy s nižšou frekvenciou s väčším počtom slov na nájdenie konkurencie.
Musíme analyzovať ich požiadavky. Môžete použiť službu SpyWords, ale funkcia analýzy dotazov je k dispozícii pre platený plán, ktorého cena je dosť vysoká. Preto pre jedno jadro nemá zmysel aktualizovať tarifu pre túto službu. Ak potrebujete v priebehu mesiaca nazbierať niekoľko jadier, napríklad 5-10, môžete si kúpiť účet. Ale opäť - iba ak máte rozpočet na tarifu PRO.
Štatistiky LiveInternet môžete tiež použiť, ak sú otvorené na zobrazenie. Majitelia to veľmi často otvoria inzerentom, ale zavrú sekciu „hľadané frázy“, čo potrebujeme. Ale stále existujú stránky, keď je táto sekcia otvorená pre všetkých. Veľmi zriedkavé, ale dostupné.
Najviac jednoduchým spôsobom je banálny rez a mapa webu. Niekedy nám môžu uniknúť nielen niektoré známe frázy, ale aj konkrétne otázky. Možno na nich nie je toľko materiálov a nemôžete pre nich vytvoriť samostatnú sekciu, ale môžu pridať niekoľko desiatok článkov.
Akonáhle nájdeme ďalší zoznam nových fráz na zhromažďovanie, spustíme rovnakú zbierku vyhľadávacích fráz z ľavého stĺpca Yandex Wordstat, ako v prvej fáze. Začíname už len tým, že sme v druhej skupine „Konkurenti“, takže sa k nej pridávajú požiadavky.
- Po analýze zhromažďujeme presné frekvencie hľadaných fráz;
- Nastavte filter a presuňte (odstráňte) dopyty s frekvenciou nižšou ako 30 do samostatnej skupiny;
- Upratujeme odpadky (zastavte slová a dotazy, ktoré nesúvisia s nikou).
Takže sme dostali ďalší malý zoznam požiadaviek a sémantické jadro sa stalo úplnejším.
3. fáza - rozšírenie
Skupinu s názvom „1-2“ už máme. V ňom kopírujeme frázy zo skupín „Hlavný zoznam požiadaviek“ a „Konkurenti“. Je dôležité kopírovať, nepohybovať sa, aby všetky frázy pre každý prípad zostali v predchádzajúcich skupinách. Takto to bude bezpečnejšie. Ak to chcete urobiť, v okne prenosu fráz vyberte možnosť „kopírovať“.
V jednej skupine sme dostali všetky žiadosti z 1-2 fáz. Teraz musíte v tejto skupine nechať iba 10% najčastejších dotazov z celkového počtu, ktoré obsahujú najmenej 2 slová. Tiež by ich nemalo byť viac ako 100. Znížime to, aby sme sa nepochovali v procese zberu jadra na mesiac.
Najprv použijeme filter, v ktorom nastavíme podmienku, aby sa zobrazili aspoň 2 slovné spojenia.

Označíme všetky frázy v zostávajúcom zozname. Kliknutím na stĺpček „Frekvencia!“ Zoradíme frázy zostupne podľa počtu zobrazení tak, aby sa najčastejšie nachádzali v hornej časti. Ďalej vyberieme prvých 10% zo zostávajúceho počtu žiadostí, zrušíme ich začiarknutie ( pravé tlačidlo myš - zrušte začiarknutie vybraných riadkov) a odstráňte označené frázy tak, aby zostalo iba týchto 10%. Nezabudnite, že ak je vašich 10% viac ako 100 slov, zastavíme sa na 100. riadku, už to nie je potrebné.
Teraz expandujeme pomocou funkcie zberača kľúčov. S tým pomôže služba Rookee.

Parametre zbierky špecifikujeme ako na obrázku nižšie.

Služba bude zhromažďovať všetky rozšírenia. Medzi novými frázami môžu byť veľmi dlhé klávesy a tiež symboly, takže nie každý bude môcť zbierať frekvenciu prostredníctvom Yandex Direct. Potom budete musieť zhromaždiť štatistiky pomocou tlačidla z wordstatu.
Po obdržaní štatistík odstránime požiadavky s mesačným zobrazením menším ako 30 a vykonáme čistenie (zarážky, odpadky, kľúče, ktoré sa nehodia do medzery).
Javisko sa skončilo. Dostali sme ďalší zoznam žiadostí.
Fáza 4 - zbieranie najlepších slovných foriem
Ako už bolo uvedené, cieľom nie je definovať formu frázy, ktorá bude správnejšia.
Vo väčšine prípadov (na základe mojej praxe) bude zbieranie najlepších tvarov slov ukazovať na rovnakú frázu ako v zozname dopytov. Ale nepochybne budú existovať také požiadavky, ktorým bude naznačený nový slovný tvar, ktorý ešte nie je v sémantickom jadre. Toto sú ďalšie kľúčové slová. V tejto fáze dokončujeme jadro k maximálnej úplnosti.
Pri zhromažďovaní jadra poskytla táto fáza 107 ďalších požiadaviek.
Najprv skopírujeme kľúče do skupiny „1-3“ zo skupín „Hlavné dotazy“, „Konkurenti“ a „1-2“. Mali by ste dostať súčet všetkých žiadostí zo všetkých predtým vykonaných fáz. Ďalej používame službu Rookee pomocou rovnakého tlačidla ako rozšírenie. Stačí si vybrať inú funkciu.

Zbierka sa začne. Frázy budú pridané do nového stĺpca „Forma najlepšej frázy“.

Najlepšia forma nebude určená pre všetky frázy, pretože Rookee jednoducho nepozná všetky najlepšie formy. Ale pre väčšinu bude výsledok pozitívny.
Po dokončení procesu musíte tieto frázy pridať do celého zoznamu tak, aby boli v rovnakom stĺpci „Fráza“. Za týmto účelom vyberte všetky frázy v stĺpci „Najlepšia forma frázy“, skopírujte (pravé tlačidlo myši - skopírujte), potom kliknite na veľké zelené tlačidlo „Pridať frázy“ a zadajte ich.
Je veľmi jednoduché zaistiť, aby sa frázy nachádzali vo všeobecnom zozname. Pretože keď sa frázy pridávajú do tabuľky takýmto spôsobom, stane sa to úplne dole, potom sa posúvame na úplný koniec zoznamu a v stĺpci „Zdroj“ by sme mali vidieť ikonu tlačidla pridať.

Frázy pridané pomocou rozšírení budú označené ikonou ruky.
Pretože frekvencia najlepších slovných foriem nebola stanovená, musíte to urobiť. Podobne ako v predchádzajúcich krokoch zhromažďujeme počet zobrazení. Nebojte sa, že zber sa vykonáva v rovnakej skupine, kde sa nachádzajú aj ostatné žiadosti. Zbierka bude jednoducho pokračovať pre tie frázy, ktoré majú prázdne bunky.
Ak je to pre vás pohodlnejšie, spočiatku môžete najlepšie slovné formy pridať nie do tej istej skupiny, kde boli nájdené, ale do novej, aby tam boli iba oni. A už v ňom zbierajte štatistiky, upratujte odpadky a podobne. A až potom pridajte zostávajúce normálne frázy do celého zoznamu.
To je všetko. Sémantické jadro stránky bolo zostavené. Ale stále zostáva veľa práce. Pokračujme.
Pred ďalšími krokmi musíte vyložiť všetky požiadavky s potrebnými údajmi do súbor excel na počítači. Nastavenia exportu sme nastavili skôr, takže to môžete urobiť ihneď. Môže za to ikona exportu v hlavnej ponuke KeyCollector.

Po otvorení súboru by ste mali dostať 4 stĺpce:
- Fráza;
- Zdroj;
- Frekvencia !;
- Najlepšia forma frázy.
Toto je naše konečné sémantické jadro, obsahujúce maximálne čistý a potrebný zoznam požiadaviek na písanie budúcich textov. V mojom prípade (úzka medzera) bolo 1848 žiadostí, čo sa rovná približne 250-300 článkom. Nemôžem to povedať s istotou - všetky požiadavky som úplne zoskupil.
Na okamžité použitie je to stále hrubá možnosť, pretože žiadosti sú v chaotickom poradí. Musíme ich tiež rozptýliť do skupín, aby každá obsahovala kľúče od jedného článku. Toto je konečný cieľ.
Zrušenie zoskupenia sémantického jadra
Táto fáza sa vykonáva pomerne rýchlo, aj keď s určitými komplikáciami. Služba nám pomôže http://kg.ppc-panel.ru/... Existujú aj ďalšie možnosti, ale použijeme to vzhľadom na to, že s tým urobíme všetko v pomere kvalita / rýchlosť. Nie je tu potrebná rýchlosť, ale predovšetkým kvalita.
Veľmi užitočnou funkciou služby je zapamätanie si všetkých akcií vo vašom prehliadači pomocou súboru cookie. Aj keď zavriete túto stránku alebo prehliadač všeobecne, všetko sa uloží. Nie je teda potrebné robiť všetko naraz a báť sa, že všetko môže v jeden moment zmiznúť. Pokračovať môžete kedykoľvek. Hlavnou vecou nie je vymazať súbory cookie prehliadača.
Ukážem vám, ako používať službu, pomocou príkladu niekoľkých fiktívnych dopytov.
Prejdite na službu a pridajte celé sémantické jadro (všetky požiadavky zo súboru programu Excel) exportované skôr. Stačí skopírovať všetky kľúče a vložiť ich do okna, ako je znázornené na obrázku nižšie.
Mali by sa objaviť v ľavom stĺpci „Kľúčové slová“.
Nevenujte pozornosť prítomnosti naplnených skupín na pravej strane. Toto sú skupiny z môjho predchádzajúceho jadra.
Pozeráme sa na ľavý stĺpček. K dispozícii je pridaný zoznam dopytov a reťazec Hľadať / Filter. Použijeme filter.
Technológia je veľmi jednoduchá. Keď zadáme časť slova alebo frázy, služba v reálnom čase nechá v zozname požiadaviek iba tie, ktoré obsahujú zadané slovo / frázu v samotnej požiadavke.
Ďalšie podrobnosti nájdete nižšie.

Chcel som nájsť všetky otázky týkajúce sa arytmie. Zadám slovo „Arytmia“ a služba automaticky nechá v zozname požiadaviek iba tie, ktoré obsahujú zadané slovo alebo jeho časť.
Frázy sa presunú do skupiny, ktorá bude pomenovaná ako jedna z kľúčových fráz tejto skupiny.
Získali sme skupinu, v ktorej sú všetky kľúčové slová pre arytmiu. Ak chcete zobraziť obsah skupiny, kliknite na ňu. O niečo neskôr rozdelíme túto skupinu na menšie skupiny, pretože existuje veľa kľúčov s arytmiou a všetky sú pod rôznymi článkami.
V počiatočnej fáze zoskupovania teda musíte vytvoriť veľké skupiny, ktoré kombinujú veľký počet kľúčových slov z jednej špecifickej otázky.
Ak vezmete ako príklad rovnakú tému srdcových chorôb, potom najskôr vytvorím skupinu „arytmia“, potom „srdcová chyba“, potom „srdcový záchvat“ a tak ďalej, až kým pre každú z chorôb neexistujú skupiny.
Takéto skupiny budú spravidla takmer rovnaké ako hlavné frázy generované v 1. fáze zberu jadra. Ale v každom prípade by ich malo byť viac, pretože existujú aj frázy z 2. až 4. etapy.
Niektoré skupiny môžu obsahovať celkom 1-2 kľúče. Príčinou môže byť napríklad veľmi zriedkavá choroba a nikto o nej nevie alebo ju nikto nehľadá. Preto neexistujú žiadne požiadavky.
Všeobecne platí, že keď sú vytvorené hlavné skupiny, je potrebné ich rozdeliť na menšie skupiny, ktoré budú slúžiť na písanie jednotlivých článkov.
V skupine je oproti každej kľúčovej fráze krížik, kliknutím na ňu sa fráza odstráni zo skupiny a vráti sa do nezoskupeného zoznamu kľúčových slov.
Dochádza teda k ďalšiemu zoskupovaniu. Ukážem vám to na príklade.
Na obrázku vidíte, že existujú kľúčové frázy súvisiace s liečbou arytmie. Ak ich chceme definovať v samostatnej skupine pre samostatný článok, potom ich zo skupiny odstránime.

Zobrazia sa v zozname v ľavom stĺpci.
Ak sú v ľavom stĺpci stále frázy, potom, aby ste našli odstránené kľúče zo skupiny, budete musieť použiť filter (použite vyhľadávanie). Ak je zoznam úplne v skupinách, budú existovať iba odstránené žiadosti. Označíme ich a klikneme na „Vytvoriť skupinu“.

V stĺpci „Skupiny“ sa zobrazí ďalší.
Distribuujeme teda všetky kľúče podľa témy a pre každú skupinu je, samozrejme, napísaný samostatný článok.
Jediným problémom v tomto procese je analyzovať potrebu zrušenia zoskupenia niektorých kľúčových slov. Faktom je, že existujú kľúče, ktoré sú vo svojej podstate odlišné, ale nevyžadujú písanie samostatných textov a o mnohých problémoch je napísaný podrobný materiál.
To je jasne vyjadrené v lekárskej oblasti. Ak si vezmeme príklad s arytmiou, potom nemá zmysel vytvárať kľúče „spôsobiť arytmiu“ a „symptómy arytmie“. Indície o liečbe arytmie sú stále otázne.
To sa zistí po analýze výsledkov vyhľadávania. Prejdeme do vyhľadávania Yandex a zadáme analyzovaný kľúč. Ak vidíme, že TOP obsahuje články venované iba symptómom arytmie, potom tento kľúč vyčleníme v samostatnej skupine. Ak však texty v TOP odhalia všetky otázky (liečba, príčiny, symptómy, diagnostika a podobne), potom zoskupenie v tomto prípade nie je potrebné. Všetky tieto témy pokrývame v jednom článku.
Ak Yandex obsahuje iba také texty v hornej časti výsledkov vyhľadávania, je to znak, že zoskupovanie sa neoplatí robiť.
To isté možno uviesť na príklade kľúčovej frázy „príčiny vypadávania vlasov“. Môžu existovať zátky v „príčinách vypadávania vlasov u mužov“ a „... u žien“. Je zrejmé, že pre každý kľúč môžete napísať samostatný text na základe logiky. Čo však povie Yandex?
Vchádzame do každého kľúča a vidíme, aké texty sú tam prítomné. Pre každý kľúč sú samostatné podrobné texty, potom sú kľúče zoskupené. Ak v TOP pre oba dotazy existujú všeobecné materiály o kľúčových „príčinách vypadávania vlasov“, v rámci ktorých sú zverejnené otázky týkajúce sa žien a mužov, potom ponecháme kľúče v rámci tej istej skupiny a uverejníme jeden materiál, kde sú témy pre všetky kľúče sú odhalené.
To je dôležité, pretože vyhľadávací nástroj vedome identifikuje texty v TOP. Ak prvá strana obsahuje mimoriadne podrobné texty o konkrétnej problematike, potom je vysoká pravdepodobnosť, že rozbitím veľkej témy na podtémy a písanie pre každý materiál sa nedostanete do TOP. A tak jeden materiál má každú šancu získať dobré pozície pre všetky otázky a zhromaždiť pre ne dobrú návštevnosť.
V lekárskych témach je potrebné tomuto bodu venovať veľkú pozornosť, čo značne komplikuje a spomaľuje proces zoskupovania.
V spodnej časti stĺpca „Skupiny“ sa nachádza tlačidlo „Odovzdať“. Kliknite na ňu a získate nový stĺpec s textovým poľom obsahujúcim všetky skupiny oddelené odsadením riadkov.
Ak nie sú všetky kľúče v skupinách, v poli „Vyložiť“ nebudú medzi nimi medzery. Zobrazujú sa iba vtedy, ak sú úplne nezoskupené.
Vyberte všetky slová (kombinácia klávesov Ctrl + A), skopírujte ich a prilepte do nového súboru programu Excel.
V žiadnom prípade neklikneme na tlačidlo „Vymazať všetko“, pretože všetko, čo ste urobili, bude odstránené.
Fáza zoskupovania sa skončila. Teraz môžete bezpečne napísať text pre každú skupinu.
Ale pre maximálnu efektivitu, ak vám to rozpočet nedovolí, to všetko napísať. jadro za pár dní, ale existuje iba prísne obmedzená príležitosť na pravidelné publikovanie malého počtu textov (napríklad 10-30 mesačne), potom stojí za to určiť konkurenciu všetkých skupín. Je to dôležité, pretože skupiny s najmenšou konkurenciou prinášajú výsledky v prvých 2 až 3 až 4 mesiacoch po napísaní bez akýchkoľvek odkazov. Stačí napísať kvalitný konkurenčný text a správne ho optimalizovať. Potom čas urobí všetko za vás.
Definovanie skupinovej súťaže
Hneď chcem poukázať na to, že nízko súbežná požiadavka alebo skupina požiadaviek neznamená, že sú vysoko mikro nízkofrekvenčné. Krása je, že existuje pomerne slušný počet požiadaviek, ktoré majú nízku konkurenciu, ale zároveň majú vysokú frekvenciu, čo okamžite dáva takýto článok TOP a priťahuje solídnu návštevnosť k jednému dokumentu.
Napríklad, veľmi reálny obraz je, keď skupina žiadostí súťaží o 2-5 a frekvencia je asi 300 zobrazení za mesiac. Keď sme napísali iba 10 takýchto textov, potom, čo sa dostanú na TOP, prijmeme najmenej 100 návštevníkov denne. A to je len 10 textov. 50 článkov - 500 návštev a tieto údaje sú prevzaté zo stropu, pretože sa v nich zohľadňuje iba návštevnosť presných dopytov v skupine. Dopravu však budú priťahovať aj ďalšie chvosty požiadaviek, a nielen tie v skupinách.
Preto je také dôležité definovať konkurenciu. Niekedy môžete vidieť situáciu, keď je na webe 20-30 textov a už 1 000 návštev. A stránka je mladá a neexistujú žiadne odkazy. Teraz už viete, s čím to súvisí.
Konkurenciu požiadaviek je možné určiť pomocou rovnakého KeyCollector úplne zadarmo. Je to veľmi výhodné, ale v ideálnom prípade táto možnosť nie je správna, pretože vzorec na stanovenie konkurencieschopnosti sa so zmenou algoritmov vyhľadávacích nástrojov neustále mení.
Je lepšie identifikovať konkurenciu so službou http://mutagen.ru/... Je platený, ale čo najviac sa približuje skutočným ukazovateľom.
100 žiadostí stojí iba 30 rubľov. Ak máte jadro na 2 000 žiadostí, celá kontrola bude stáť 600 rubľov. Denne je poskytnutých 20 bezplatných šekov (iba pre tých, ktorí doplnili zostatok na akúkoľvek sumu). Každý deň môžete vyhodnotiť 20 fráz, kým neurčíte konkurencieschopnosť celého jadra. Ale je to veľmi dlhé a hlúpe.
Preto používam mutagén a nemám naň žiadne sťažnosti. Niekedy sú problémy s rýchlosťou spracovania, ale nie je to také kritické, pretože aj po zatvorení stránky služby kontrola pokračuje na pozadí.
Samotná analýza je veľmi jednoduchá. Registrujeme sa na stránke. Zostatok doplníme akýmkoľvek pohodlným spôsobom a šek je k dispozícii na hlavnej adrese (mutagen.ru). Do poľa zadáme frázu a hneď sa začne hodnotiť.
Vidíme, že pre kontrolovaný dotaz bola konkurencieschopnosť vyššia ako 25. Toto je veľmi vysoký ukazovateľ a môže sa rovnať ľubovoľnému číslu. Služba ju nezobrazuje ako skutočnú, pretože nemá zmysel vzhľadom na skutočnosť, že je takmer nemožné propagovať takéto konkurenčné požiadavky.
Normálna úroveň konkurencie sa považuje za 5. Práve tieto požiadavky sa ľahko propagujú bez zbytočných gest. Mierne vyššie sadzby sú tiež celkom prijateľné, ale otázky s hodnotami nad 5 (napríklad 6-10) by ste mali použiť až potom, čo ste už napísali texty pre minimálnu konkurenciu. Dôležitý je čo najrýchlejší text v TOP.
Počas hodnotenia sa určujú aj náklady na kliknutie v službe Yandex.Direct. Môže sa použiť na odhad vašich budúcich zárobkov. Berieme do úvahy garantované dojmy, ktorých hodnotu môžeme bezpečne rozdeliť na 3. V našom prípade môžeme povedať, že jedno kliknutie na reklamu Yandex Direct nám prinesie 1 rubeľ.
Služba tiež určuje počet zobrazení, ale nepozeráme sa na ne, pretože frekvencia nie je stanovená vo forme „! Žiadosť“, ale iba „žiadosť“. Indikátor nie je presný.
Táto možnosť analýzy je vhodná, ak chceme analyzovať samostatnú požiadavku. Ak potrebujete hromadnú kontrolu kľúčových fráz, potom pokračujte domovská stránka v hornej časti poľa na zadanie kľúča je špeciálny odkaz.

Na ďalšej stránke vytvoríme novú úlohu a pridáme zoznam kľúčov zo sémantického jadra. Prevezmeme ich zo súboru, kde sú kľúče už nezoskupené.
Ak je v súvahe dostatok finančných prostriedkov na analýzu, kontrola sa začne okamžite. Trvanie overenia závisí od počtu kľúčov a môže nejaký čas trvať. Asi 1 hodinu som analyzoval 2 000 fráz, pričom druhá kontrola iba 30 klávesov už trvala niekoľko hodín.
Ihneď po spustení kontroly sa vám úloha zobrazí v zozname so stĺpcom „Stav“. Z toho pochopíte, či je úloha pripravená alebo nie.
Navyše, po dokončení úlohy si môžete okamžite stiahnuť súbor so zoznamom všetkých fráz a úrovňou súťaže pre každú z nich. Frázy budú v rovnakom poradí, ako boli zoskupené. Jediná vec je, že medzery medzi skupinami budú odstránené, ale nie je to desivé, pretože všetko bude intuitívne, pretože každá skupina obsahuje kľúče na inú tému.
Okrem toho, ak úloha ešte nebola dokončená, môžete ísť do samotnej úlohy a pozrieť si výsledky súťaže o už vykonaných požiadavkách. Stačí kliknúť na názov úlohy.
Ako príklad uvediem výsledok kontroly skupiny dotazov na sémantické jadro. V skutočnosti je to skupina, pre ktorú bol tento článok napísaný.
Vidíme, že takmer všetky žiadosti majú maximálnu konkurenciu 25 alebo bližšie k nej. To znamená, že pre tieto požiadavky buď nevidím prvé pozície vôbec, alebo ich nevidím veľmi dlho. Vôbec by som na nový web nepísal taký materiál.
Teraz som to publikoval len kvôli vytvoreniu kvalitného obsahu blogu. Samozrejme, mojim cieľom je dostať to na vrchol, ale to bude neskôr. Ak príručka vyjde na prvej stránke aspoň iba na základe hlavnej požiadavky, potom už môžem počítať s nie solídnou návštevnosťou iba na túto stránku.
Posledným krokom je vytvorenie konečného súboru, na ktorý sa pozrieme v procese plnenia stránky. Sémantické jadro stránky už bolo zostavené, ale zatiaľ nie je veľmi vhodné ho spravovať.
Vytvorenie konečného súboru so všetkými údajmi
Opäť budeme potrebovať KeyCollector, ako aj posledný súbor programu Excel, ktorý sme dostali zo služby mutagénu.
Otvorte predtým získaný súbor a pozrite sa na niečo podobné nasledujúcemu.
Zo súboru potrebujeme iba 2 stĺpce:
- kľúč;
- súťaž.
Môžete jednoducho odstrániť všetok zvyšok obsahu z tohto súboru, aby zostali iba potrebné údaje, alebo vytvoriť úplne nový súbor, vytvoriť tam krásny riadok hlavičky s názvami stĺpcov a zvýrazniť ho napríklad zelenou farbou. a skopírujte zodpovedajúce údaje do každého stĺpca.
Ďalej skopírujeme celé sémantické jadro z tohto dokumentu a znova ho pridáme do zberača kľúčov. Budete musieť znova zostaviť frekvencie. Je to nevyhnutné, aby sa frekvencie zbierali v rovnakom poradí, v akom sa nachádzajú kľúčové frázy. Predtým sme ich zbierali na odstránenie odpadu a teraz na vytvorenie konečného súboru. Frázy samozrejme pridávame do novej skupiny.
Keď sú frekvencie zhromaždené, exportujeme súbor z celého stĺpca s frekvenciou a skopírujeme ho do konečného súboru, kde budú 3 stĺpce:
- kľúčová fráza;
- konkurencieschopnosť;
- frekvencia.
Teraz zostáva chvíľu sedieť a vypočítať pre každú skupinu:
- Priemerná frekvencia skupiny - nie je dôležitý ukazovateľ každého kľúča, ale priemer skupiny. Je považovaný za obvyklý aritmetický priemer (v programe Excel - funkcia „PRIEMER“);
- Rozdeľte celkovú frekvenciu skupiny o 3, aby sa prípadná návštevnosť dostala na reálne čísla.
Aby ste sa nemuseli starať o zvládnutie výpočtov v programe Excel, pripravil som pre vás súbor, kde stačí zadať údaje do potrebných stĺpcov a všetko sa automaticky vypočíta. Každá skupina sa musí vypočítať osobitne.
Vnútri bude jednoduchý príklad výpočtu.
Ako vidíte, všetko je veľmi jednoduché. Z konečného súboru jednoducho skopírujte všetky frázy skupiny ako celok so všetkými indikátormi a prilepte ich do tohto súboru namiesto predchádzajúcich fráz s ich údajmi. A výpočet prebehne automaticky.
Je dôležité, aby stĺpce v konečnom a mojom súbore boli v tomto poradí. Najprv fráza, potom frekvencia a až potom iba konkurencia. V opačnom prípade budete počítať hlúposti.
Potom budete musieť trochu sedieť a vytvoriť ďalší súbor alebo hárok (odporúčam) vo vnútri súboru so všetkými údajmi o každej skupine. Tento list nebude obsahovať všetky frázy, ale iba hlavnú frázu skupiny (pomocou nej určíme, o akú skupinu ide) a vypočítané hodnoty skupiny z môjho súboru. Toto je druh konečného súboru údajov pre každú skupinu s vypočítanými hodnotami. Pozerám sa na neho pri výbere textov na publikovanie.
Ukážu sa všetky rovnaké 3 stĺpce, ale bez akýchkoľvek výpočtov.
Do prvého vložíme hlavnú frázu skupiny. V zásade môžete urobiť čokoľvek. Je to potrebné iba na to, aby ste ho skopírovali a pomocou vyhľadávania našli umiestnenie všetkých kľúčov skupiny, ktoré sú na inom hárku.
V druhom skopírujeme vypočítanú hodnotu frekvencie z môjho súboru a v treťom priemerná hodnota skupinovej súťaže. Tieto čísla preberáme z riadku „Výsledok“.
V dôsledku toho získate nasledujúce.
Toto je 1. list. Druhý list obsahuje všetok obsah konečného súboru, t.j. všetky frázy s indikátormi ich frekvencie a konkurencie.
Teraz sa pozeráme na 1. list. Vyberáme najekonomickejšiu skupinu kľúčov. Skopírujte frázu z 1. stĺpca a nájdite ju pomocou vyhľadávania (Ctrl + F) v druhom hárku, kde budú vedľa nej zvyšné frázy skupiny.
To je všetko. Príručka sa skončila. Na prvý pohľad je všetko veľmi komplikované, ale v skutočnosti je to celkom jednoduché. Ako som povedal na úplnom začiatku článku, stačí s tým začať. V budúcnosti plánujem pre tieto pokyny vytvoriť video manuál.
V tejto poznámke ukončujem inštrukciu.
Všetci priatelia. Ak mám nejaké návrhy, otázky - čakám v komentároch. Dobudúcna.
P. S. Zaznamenajte objem obsahu. Vo Worde sa ukázalo viac ako 50 listov drobného písma. Bolo možné nevydať článok, ale vytvoriť knihu.
S pozdravom Konstantin Khmelev!
Sémantické jadro je strašidelný názov, ktorý si SEO vymysleli, aby odkazoval na celkom jednoduchú vec. Stačí si vybrať kľúčové otázky, pre ktoré budeme propagovať naše stránky.
A v tomto článku vám ukážem, ako správne poskladať sémantické jadro tak, aby sa váš web rýchlo dostal na vrchol a nestagnoval niekoľko mesiacov. Má tiež svoje „tajomstvá“.
A predtým, ako prejdeme k zostavovaniu SN, pozrime sa, čo to je a na čo by sme mali nakoniec prísť.
Čo je sémantické jadro v jednoduchých slovách
Zdá sa to zvláštne, ale sémantickým jadrom je bežný súbor programu Excel, ktorý obsahuje zoznam kľúčových dopytov, pre ktoré budete vy (alebo váš copywriter) písať články pre tento web.
Napríklad takto vyzerá moje sémantické jadro:
Zelenou farbou som označil tie kľúčové slová, pre ktoré som už napísal články. Žltá - tie, pre ktoré sa v blízkej budúcnosti chystám písať články. A bezfarebné bunky - to znamená, že k týmto požiadavkám príde o niečo neskôr.
Pre každú kľúčovú požiadavku som určil frekvenciu, súbežnosť a prišiel som s „chytľavým“ nadpisom. Mali by ste dostať približne rovnaký súbor. Teraz môj SN pozostáva zo 150 kľúčových slov. To znamená, že mám „materiál“ poskytnutý najmenej 5 mesiacov vopred (aj keď napíšem jeden článok denne).
Ďalej budeme hovoriť o tom, na čo sa pripraviť, ak sa zrazu rozhodnete objednať zbierku sémantického jadra od špecialistov. Tu stručne poviem - dostanete rovnaký zoznam, ale iba pre tisíce „kľúčov“. V SA však nie je dôležitá kvantita, ale kvalita. A na toto sa zameriame.
Prečo vôbec potrebujete sémantické jadro?
A vlastne, prečo potrebujeme toto trápenie? Koniec koncov, môžete len písať kvalitné články a priťahovať tým publikum, však? Áno, môžete písať, ale nebudete vedieť upútať.
Hlavnou chybou, ktorú 90% bloggerov robí, je písanie vysokokvalitných článkov. Nerobím si srandu, majú skutočne zaujímavé a užitočné materiály. Ale vyhľadávače o tom nevedia. Nie sú to psychici, sú to len roboti. V súlade s tým nedávajú váš článok medzi TOP.
Tu s názvom je ešte jeden jemný bod. Napríklad máte veľmi kvalitný článok na tému „Ako podnikať“ v „knihe mordo“. Veľmi podrobne a profesionálne tam popisujete všetko o Facebooku. Vrátane toho, ako tam propagovať komunity. Váš článok je najkvalitnejší, užitočný a zaujímavý článok na túto tému na internete. Vedľa teba nikto neležal. Ale aj tak ti to nepomôže.
Prečo kvalitné články vyletujú z TOP
Predstavte si, že by vašu stránku nenavštívil robot, ale živý inšpektor (hodnotiteľ) z Yandexu. Uvedomil si, že máš najlepší článok. A rukami ste sa dostali na prvé miesto vo výsledkoch vyhľadávania pre požiadavku „Propagácia komunity na Facebooku“.
Viete, čo bude ďalej? Veľmi skoro odtiaľ odletíte. Pretože na váš článok ani v prvom rade nikto nekliká. Ľudia zadajú požiadavku „Propagácia komunity na Facebooku“ a váš nadpis znie „Ako správne podnikať v„ mordobooku “. Originálne, svieže, vtipné, ale ... nie na požiadanie. Ľudia chcú vidieť presne to, čo hľadali, nie vašu kreativitu.
Preto bude váš článok nečinný, aby obsadil miesto v hornej časti SERP. A živý hodnotiteľ, vášnivý obdivovateľ vašej kreativity, môže úrady poprosiť, koľko len chcú, aby vás nechali aspoň v TOP-10. Ale nepomôže to. Všetky prvé miesta budú obsadené prázdnymi článkami, ako sú plevy semien, ktoré si včerajší školáci navzájom kopírovali.
Tieto články však budú mať správny „relevantný“ názov - „Propagácia komunity na Facebooku od začiatku“ ( krok za krokom, v 5 krokoch, od A po Z, zadarmo atď.) Útočné? Stále by. No bojujte proti nespravodlivosti. Dajme dohromady kompetentné sémantické jadro, aby vaše články zaujali prvé miesta, ktoré si zaslúžia.
Ďalší dôvod, prečo si začať vymýšľať SJ práve teraz
Je tu ešte jedna vec, o ktorej ľudia z nejakého dôvodu trochu premýšľajú. Musíte písať články často - najmenej každý týždeň a najlepšie 2-3 krát týždenne, aby ste získali väčšiu návštevnosť a rýchlejšie.
Každý to vie, ale takmer nikto to nerobí. A to všetko preto, že majú „kreatívnu stagnáciu“, „nemôžu sa nijako prinútiť“, „lenivosť“. Ale v skutočnosti je celý problém presne v neprítomnosti konkrétneho sémantického jadra.
Do vyhľadávacieho poľa som zadal jeden zo svojich základných kľúčov - „smm“ a Yandex mi okamžite dal tucet tipov, čo by ešte mohlo zaujímať ľudí, ktorých zaujíma „smm“. Tieto kľúče musím skopírovať do notebooku. Potom skontrolujem každého z nich rovnakým spôsobom a tiež pre nich zozbieram stopy.
Po prvej fáze zbierania SN by ste mali mať textový dokument obsahujúci 10-30 širokých základných kľúčov, s ktorými budeme ďalej pracovať.
Krok č. 2 - Analýza základných kľúčov v programe SlovoEB
Samozrejme, ak napíšete článok na žiadosť „webinár“ alebo „smm“, zázrak sa nestane. Pri takej širokej požiadavke nikdy nebudete môcť dosiahnuť TOP. Základný kľúč musíme rozdeliť na mnoho malých otázok na túto tému. A urobíme to pomocou špeciálneho programu.
Používam KeyCollector, ale je platený. Môžete použiť bezplatný analóg - program SlovoEB. Môžete si ho stiahnuť z oficiálneho webu.
Najťažšou vecou pri práci s týmto programom je správne ho nakonfigurovať. Ukazujem, ako správne nakonfigurovať a používať Slovoeb. V tomto článku sa však zameriavam na výber kľúčov pre Yandex Direct.
A tu sa pozrime krok za krokom na funkcie použitia tohto programu na zostavenie sémantického jadra pre SEO.
Najprv vytvoríme nový projekt a pomenujeme ho podľa širokého kľúča, ktorý chcete analyzovať.
Projektu zvyčajne dávam rovnaké meno ako svoj základný kľúč, aby som sa neskôr nezamotal. A áno, upozorním vás ešte na jednu chybu. Nepokúšajte sa analyzovať všetky základné kľúče súčasne. Potom bude pre vás veľmi ťažké filtrovať „prázdne“ kľúčové slová zo zŕn zlata. Rozoberme jeden kľúč naraz.
Po vytvorení projektu vykonávame základnú operáciu. To znamená, že v skutočnosti analyzujeme kľúč prostredníctvom programu Yandex Wordstat. Ak to chcete urobiť, kliknite na tlačidlo „Vorstat“ v rozhraní programu, zadajte svoj základný kľúč a kliknite na „Spustiť zbierku“.
Rozoberme si napríklad základný kľúč pre môj blog „kontextovej reklamy“.
Potom sa spustí proces a po chvíli nám program poskytne výsledok - až 2 000 kľúčových dopytov, ktoré obsahujú „kontextovú reklamu“.
Vedľa každej žiadosti bude tiež „špinavá“ frekvencia - koľkokrát bol tento kľúč (+ jeho slovné formy a chvosty) mesačne prehľadávaný prostredníctvom služby Yandex. Neodporúčam vám však vyvodzovať z týchto čísel akékoľvek závery.
Krok č. 3 - Zhromažďovanie presných kľúčových frekvencií
Špinavá frekvencia nám nič neukáže. Ak sa na to zameriate, potom sa nečudujte, keď váš kľúč pre 1000 žiadostí neprinesie jediné kliknutie za mesiac.
Musíme identifikovať čistú frekvenciu. Za týmto účelom najskôr vyberieme všetky nájdené kľúče so začiarknutím a potom klikneme na tlačidlo „Yandex Direct“ a spustíme postup znova. Teraz nám Slovoeb pre každý kľúč vyhľadá presnú frekvenciu požiadavky za mesiac.
Teraz máme objektívny obraz - koľkokrát boli používatelia internetu zadaní za posledný mesiac. Teraz navrhujem zoskupiť všetky kľúčové dotazy podľa frekvencie, aby bolo s nimi pohodlnejšie pracovať.
Ak to chcete urobiť, kliknite na ikonu "filter" v stĺpci "Frekvencia"! ", A zadajte - odfiltrovanie kľúčov s hodnotou„ menšou alebo rovnou 10 “.
Teraz vám program ukáže iba tie dopyty, ktorých frekvencia je menšia alebo rovná hodnote „10“. Tieto dotazy môžete odstrániť alebo ich v budúcnosti skopírovať do inej skupiny kľúčových dotazov. Menej ako 10 je veľmi málo. Písanie článkov na tieto otázky je stratou času.
Teraz musíme vybrať tie kľúčové slová, ktoré nám prinesú viac -menej dobrú návštevnosť. A na to musíme zistiť ešte jeden parameter - úroveň súbežnosti požiadavky.
Krok č. 4 - Kontrola konkurenčných dopytov
Všetky „kľúče“ v tomto svete sú rozdelené do 3 typov: vysokofrekvenčný (HF), stredný (MF), nízky (LF). Môžu byť tiež vysoko konkurenčné (VC), stredne konkurenčné (SK) a málo konkurencieschopné (NK).
VC spravidla prijíma simultánne požiadavky na KV. To znamená, že ak sa požiadavka často hľadá na internete, potom existuje veľa stránok, ktoré ju chcú propagovať. Ale nie je to vždy tak, existujú šťastné výnimky.
Umenie zostaviť sémantické jadro je presne v hľadaní takých dotazov, ktoré majú vysokú frekvenciu a ich úroveň konkurencie je nízka. Je veľmi ťažké určiť úroveň súťaže ručne.
Môžete sa zamerať na ukazovatele, ako je počet hlavných stránok v TOP-10, dĺžka a kvalita textov. úroveň dôveryhodnosti a častíc stránok v TOP vydaní na požiadanie. To všetko vám poskytne predstavu o tom, ako náročná je konkurencia o pozície pre tento konkrétny dotaz.
Odporúčam však, aby ste to využili služba Mutagen... Berie do úvahy všetky parametre, ktoré som spomenul vyššie, plus tucet ďalších, o ktorých ste pravdepodobne ani nepočuli ani vy, ani ja. Po analýze služba poskytuje presnú hodnotu - aká je úroveň konkurencie pre túto požiadavku.
Tu som skontroloval dotaz „nastavenie kontextovej reklamy v službe Google adwords“. Mutagén nám ukázal, že tento kľúč má konkurencieschopnosť „viac ako 25“ - to je maximálna hodnota, ktorú ukazuje. A tento dotaz má iba 11 zobrazení za mesiac. Nám to teda rozhodne nevyhovuje.
Môžeme skopírovať všetky kľúče, ktoré sme vybrali v Slovoebe, a vykonať hromadnú kontrolu v Mutagene. Potom sa budeme musieť len pozrieť do zoznamu a prijať tie žiadosti, ktoré majú veľa požiadaviek a nízky level súťaž.
Mutagen je platená služba. Môžete však vykonať 10 kontrol denne zadarmo. Náklady na overenie sú navyše veľmi nízke. Za celý čas práce s ním som ešte neutratil ani 300 rubľov.
Mimochodom, na úkor úrovne konkurencie. Ak máte mladý web, je lepšie zvoliť dopyty s úrovňou konkurencie 3-5. A ak propagujete viac ako rok, môžete si vziať 10-15.
Mimochodom, na úkor frekvencie žiadostí. Teraz musíme urobiť posledný krok, ktorý vám umožní prilákať veľkú návštevnosť aj pri nízkofrekvenčných požiadavkách.
Krok č. 5 - Zhromažďovanie chvostov pre vybrané kľúče
Ako bolo mnohokrát dokázané a overené, váš web bude získavať väčšinu návštevnosti nie z hlavných kľúčov, ale z takzvaných „chvostov“. To je, keď človek vstúpi do vyhľadávací reťazec podivné kľúčové slová, s frekvenciou 1-2 mesačne, ale takýchto žiadostí je veľa.
Ak chcete vidieť „chvost“ - stačí prejsť na stránku Yandex a do vyhľadávacieho panela zadať vami zvolené kľúčové slovo. Tu je to, čo zhruba uvidíte.
Teraz stačí napísať tieto ďalšie slová do samostatného dokumentu a použiť ich vo svojom článku. Navyše ich nemusíte vždy dávať vedľa hlavného kľúča. V opačnom prípade sa vo vyhľadávačoch zobrazí „nadmerná optimalizácia“ a vaše články sa zobrazia vo výsledkoch vyhľadávania.
Stačí ich použiť na rôznych miestach vo svojom článku a potom od nich získate aj ďalšiu návštevnosť. Tiež by som vám odporučil, aby ste sa pokúsili použiť čo najviac slovných foriem a synoným pre váš hlavný dotaz na kľúčové slovo.
Máme napríklad požiadavku - „Nastavenie kontextovej reklamy“. Preformulujte to takto:
- Prispôsobiť = prispôsobiť, vytvoriť, vytvoriť, spustiť, spustiť, povoliť, hostiť ...
- Kontextová reklama = kontext, priama, upútavka, YAN, adwords, cms. priamo, adwords ...
Nikdy presne neviete, ako budú ľudia hľadať informácie. Pridajte všetky tieto ďalšie slová do svojho sémantického jadra a používajte ich pri písaní textov.
Zhromažďujeme teda zoznam 100 - 150 kľúčových slov. Ak zostavujete sémantické jadro prvýkrát, môže vám to trvať niekoľko týždňov.
Alebo mu možno dobre zlomiť oči? Možno existuje príležitosť delegovať prípravu CL na špecialistov, ktorí to urobia lepšie a rýchlejšie? Áno, existujú takíto špecialisti, ale ich služby nemusíte vždy využívať.
Mám si objednať CJ od špecialistov?
Sémantickí jadroví špecialisti vás prevedú iba krokmi 1 - 3 z nášho diagramu. Niekedy sa za veľký dodatočný poplatok vykonajú aj kroky 4-5 - (zbieranie chvostov a kontrola konkurencieschopnosti požiadaviek).
Potom vám poskytnú niekoľko tisíc kľúčových slov, s ktorými budete v budúcnosti musieť pracovať.
A otázkou je, či sa chystáte písať články sami, alebo si na to najať copywriterov. Ak sa chcete zamerať na kvalitu, nie na kvantitu, musíte napísať sami. Potom vám však nebude stačiť získať iba zoznam kľúčov. Na napísanie kvalitného článku si budete musieť vybrať témy, ktoré dostatočne dobre poznáte.
A tu vyvstáva otázka - prečo vlastne potrebujeme špecialistov v oblasti osnov? Súhlaste, analyzujte základný kľúč a zozbierajte presné frekvencie (kroky č. 1-3) nie je vôbec ťažké. Zaberie vám to doslova pol hodinu času.
Najťažšie je vybrať požiadavky RF, ktoré majú nízku konkurenciu. A teraz, ako sa ukazuje, potrebujete HF-NK, na ktorý môžete napísať dobrý článok. Presne to vám zaberie 99% času pri práci na sémantickom jadre. A žiadny špecialista vám to neurobí. Oplatí sa minúť peniaze na objednanie takýchto služieb?
Keď sú služby špecialistu na svojpomoc užitočné
Je to iná vec, ak pôvodne plánujete prilákať copywriterov. Potom nemusíte rozumieť predmetu žiadosti. Pochopiť to nebudú ani vaši textári. Jednoducho si vezmú pár článkov na túto tému a zostavia z nich vlastný text.
Takéto články budú prázdne, špinavé, takmer zbytočné. Ale bude ich veľa. Samostatne môžete za týždeň napísať maximálne 2-3 kvalitné články. A armáda copywriterov vám poskytne 2-3 sračkový text denne. Súčasne budú optimalizované pre požiadavky, čo znamená, že pritiahnu určitý druh návštevnosti.
V tomto prípade áno, neváhajte a najmite si špecialistu na YA. Nechajte ich súčasne zostaviť aj TK pre copywriterov. Ale chápete, že to bude tiež stáť nejaké peniaze.
Zhrnutie
Aby sme konsolidovali informácie, znova si prejdeme hlavné body článku.
- Sémantické jadro je jednoducho zoznam kľúčových slov, pre ktoré budete na stránke písať články na propagáciu.
- Texty je potrebné optimalizovať na presné kľúčové otázky, inak sa vaše dokonca aj najkvalitnejšie články nikdy nedostanú na TOP.
- SN je ako plán obsahu pre sociálne médiá. Pomáha vám to neprepadnúť „kreatívnej kríze“ a vždy presne vedieť, o čom budete zajtra, pozajtra a o mesiac písať.
- Na zostavenie sémantického jadra je vhodné použiť voľný program Slovoeb, potrebuješ ju.
- Tu je päť krokov na zostavenie CL: 1 - Výber základných klávesov; 2 - Analýza základných kľúčov; 3 - Zhromažďovanie presnej frekvencie dopytov; 4 - Kontrola súbežnosti kľúčov; 5 - Zbierka „chvostov“.
- Ak chcete písať články sami, je lepšie vytvoriť si sémantické jadro sami, pre seba. Tu vám kompilátory CL nepomôžu.
- Ak chcete pracovať na kvantite a používať textárov na písanie článkov, je úplne možné zapojiť delegáta a zostaviť sémantické jadro. Kiežby bolo na všetko dostatok peňazí.
Dúfam, že vám tento návod pomohol. Uložte si ho medzi obľúbené, aby ste ho nestratili, a zdieľajte ho so svojimi priateľmi. Nezabudnite si stiahnuť moju knihu. Tam vám ukážem najrýchlejšiu cestu z nuly do prvého milióna na internete (výpis z osobná skúsenosť na 10 rokov =)
Vidíme sa neskôr!
Váš Dmitrij Novosyolov
K záložkám
Ako vybudovať správne sémantické jadro
Ak si myslíte, že služba alebo program dokáže zostaviť správne jadro, budete sklamaní. Jediná služba schopná zbierať správnu sémantiku váži asi jeden a pol kilogramu a spotrebuje asi 20 wattov energie. Toto je mozog.
Navyše, v tomto prípade má mozog namiesto abstraktných vzorcov veľmi špecifickú praktickú aplikáciu. V tomto článku vám ukážem zriedka diskutované kroky v procese zhromažďovania sémantiky, ktoré nemožno automatizovať.
K zberu sémantiky existujú dva prístupy
Priblížte sa k jednému (ideálne):
Klady: v tomto prípade získate 100% pokrytie - zobrali ste všetky skutočné požiadavky s návštevnosťou pre hlavný dotaz „ploty“ a vybrali ste odtiaľ všetko, čo potrebujete: od elementárneho „nákupu plotov“ až po nenápadnú „inštaláciu betónových parapetov na cena plotu “.
Mínusy: uplynuli dva mesiace a práve ste dokončili prácu s dotazmi.
Prístup dva (mechanické):
Obchodným školám, trénerom a kontextovým agentúram trvalo dlho, kým zistili, čo s tým urobiť. Na jednej strane nemôžu na žiadosť „plotov“ skutočne prejsť celým poľom - je to drahé a náročné na prácu, ľudí to nemožno naučiť samo. Na druhej strane, peniaze študentov a klientov treba tiež nejako vziať.
Riešenie bolo vynájdené: zoberieme dotaz „ploty“, vynásobíme „cenami“, „nákupom“ a „inštaláciou“ - a ideme. Nemusíte nič analyzovať, čistiť a zbierať, hlavnou vecou je znásobiť dopyty v „multiplikačnom skripte“. Vznikajúce problémy zároveň znepokojovali niekoľko ľudí:
- Každý si vymyslí plus mínus rovnaké násobenie, takže otázky ako „inštalácia plotov“ alebo „nákup plotov“ sa okamžite „prehrievajú“.
- Tisíce kvalitných dopytov, ako napríklad „vlnité ploty v Dolgoprudnom“, nebudú vôbec zahrnuté do sémantického jadra.
Multiplikačný prístup sa úplne vyčerpal: nastávajú ťažké časy, víťazmi budú iba tie spoločnosti, ktoré dokážu vyriešiť problém vysoko kvalitného spracovania skutočne veľkého skutočného sémantického jadra - od výberu základní po čistenie, klastrovanie a vytváranie obsahu pre stránky.
Cieľom tohto článku je naučiť čitateľa nielen vybrať správnu sémantiku, ale tiež nájsť rovnováhu medzi pracovným vstupom, veľkosťou jadra a osobnou efektivitou.
Čo je základom a ako vyhľadávať dotazy
Najprv sa dohodneme na terminológii. Základom je akási všeobecná požiadavka. Ak sa vrátite k vyššie uvedenému príkladu, predáte akékoľvek ploty, potom sú „ploty“ pre vás hlavným základom. Ak predávate iba vlnité ploty, vašim hlavným základom budú „vlnité ploty“.
Súčasne na žiadosť „ploty z vlnitej lepenky“ - iba 127 tisíc zobrazení, to znamená, že pokrytie sa zmenšilo desaťkrát. Porovnateľným spôsobom sa zníži počet požiadaviek aj návštevnosť stránok.
Môžeme teda povedať, že základom je všeobecná požiadavka popisujúca produkt, službu alebo niečo iné, a to podľa jej samotnej formulácie určujúcej mieru oslovenia potenciálneho publika.
- Popíšte produkt alebo službu.
- Poskytnú taký objem pokročilých požiadaviek, ktoré môžete spracovať v primeranom časovom rámci.
Teraz sa pokúsme vysporiadať s problémom nájdenia základov ako takých.
1. Ako nazývate produkt alebo službu?
Ak ste dodávateľom, opýtajte sa na to klienta. Zákazník vám napríklad povie: „Predávam športové povrchy v Moskve a regióne.“ Vyhoďte Moskvu a región zo znenia zákazníka a tiež vyberte synonymá.
Základne v tomto prípade budú nasledovné
Obrázky sú údajmi o frekvencii pre Moskvu a región podľa WordStat. Je ľahké vidieť, že každý z dotazov pri hĺbkovej analýze programu WordStat poskytne inú vzorku pokročilých dotazov a každá vzorka je segmentom cieľového dopytu.
Príklad so synonymami je komplikovanejší: „malý“ mediálny plán na predaj luxusných nehnuteľností pre viac ako sto základní s frekvenciou v Moskve:
Záver: zbieranie sémantiky je ťažké. Samotný zber nízkofrekvenčných požiadaviek je však celkom jednoduchý - od Key Collector po MOAB a ďalšie existuje veľa služieb. Nejde o službu. Faktom je, že pomocou služby nie je možné vybrať správne základy - to sa dá urobiť iba rukami a ľudským mozgom, je to najťažšia a najťažšia operácia.
Už sme si teda pamätali na definície produktu alebo služby „od hlavy“ a priviedli ich do skrátených foriem. To znamená, že ak predávame nákladné autá KamAZ, jednoducho do súboru napíšeme „Kamaz“.
Je dôležité porozumieť kľúčovému princípu -vzorkovanie pre dopyt „Kamaz“ a pre dotaz „65115 -Kamaz“ dáva rôzne dopyty, čiastočne sa neprekrývajúce. Ide o rôzne entity.
Preto nie je potrebné bolestne čítať názvy konkurentov alebo ich analyzovať v diskutabilných službách. Oddýchnite si, zapnite fantáziu, nalejte si pohár dobrého koňaku a prečítajte si webové stránky konkurencie. Tu je zoznam SKU, z ktorých každý je samostatným výberom.
3. Služby vyhľadávača
Príklad: Pravý stĺpec programu WordStat obsahuje takzvané dopyty, ktoré používatelia hľadali spolu so zadaným. Pri pohľade do pravého stĺpca dopytu z vyššie uvedeného príkladu vidíte dopyt so slovom „sklápač“.
Dobre. Nepotrebujeme požiadavku „kúpiť sklápač kamaz“, pretože sa aj tak dostane do rozšírených dopytov na základe „kamaz“, ale dopyt „ sklápač„Je to nový segment s oddelenými novými požiadavkami, novým dopytom a novou sémantikou.
Berieme to do projektu. Podobne analyzujeme blok „hľadaných spolu s týmto“ vo výsledkoch vyhľadávania pre „Yandex“ a Google.
Google napríklad navrhuje dotaz „farmár“
Tu je to, čo na ňom môžete získať v programe WordStat
Pozrime sa, čo hovorí Yandex. Aj keď predpokladáme, že nepredávate nič iné ako vozidlá KamAZ, vaše úsilie aj tak nebude zbytočné.
Môžete vziať požiadavku „traktor“ a získať nový dopyt po svojich nákladných vozidlách a po nich
Všeobecne si myslím, že zásada je jasná: úlohou je nájsť čo najviac cieľových základní, ktoré pôsobia ako iniciátory, hnacie sily nových dlhých sémantických chvostov.
Tu samozrejme môžete poskytnúť oveľa viac tipov: pozrite sa na súbor kotiev konkurentov a pozrite sa na súbory na stiahnutie zo serverov SpyWords alebo Serpstat. To všetko je, samozrejme, dobré. Skôr by bolo pekné, keby to nebolo také smutné. Pretože v skutočnosti sa práca ešte ani nezačala: každý môže zbierať, ale snažte sa to všetko upratať, zoskupiť a kompetentne spravovať.
Vyššie uvedené je dosť na to, aby ste mali jasnú myseľ a zhromaždili sémantiku rádovo lepšie a lepšie ako 99% vašich konkurentov.
Ako netráviť celý život zbieraním kľúčových slov
Mnoho ľudí sa pýta: ako správne zvládnuť sémantiku, ako ju „vystrihnúť“. Ak predávate náhrobky z byvolieho rohu v Naryan -Mar, je nepravdepodobné, že by ste sa s týmto problémom stretli - vždy budete mať malú sémantiku. Zároveň v „horúcich“ obľúbených témach je sémantika vždy v plnom prúde: názvy značiek, kategórií, modelov, ich synonymá atď.
Tento problém riešime viacúrovňovou prioritizáciou sémantiky.
1. Uprednostnenie sémantiky pred zhromažďovaním žiadostí
Ak ešte veľa zostáva, odstráňte tie sekcie, kde je marža menšia ako 25 - 30%, tam s najväčšou pravdepodobnosťou ani veľa nezarobíte - nanajvýš malá zmena vo vrecku a navyše výrobcovi ukážete viac obrat a knock out nové zľavy. Môžete zarobiť zaujímavé peniaze na tovare a službách s maržou 30% a viac - nie vždy a nie všade, samozrejme, ale tieto čísla som už mnohokrát videl pri rôznych projektoch.
2. Zbierka základov a rozšírená sémantika k nim
Zozbierané? Je to aj tak veľa? Poradie otázok. Vedľa každej základne umiestnite 1, 2 alebo 3. Prinútite sa do toho takto:
Zámerne sa obmedzujem na tri hodnoty- je to jednoduché. Ak máte desať úrovní priority, zbláznite sa z premýšľania, či dať 6 alebo 7 na konkrétny základ - a preto sú riešenia veľmi jednoduché a zrejmé.
Okrem toho pomáha štruktúrovať vaše podnikanie pre seba - pozrieť sa na to prizmou dopytu a marginality: filtrujeme podľa stĺpca „Priorita“ a vidíme, že „1“ sme dali na tie základy, po ktorých je malý dopyt .
To znamená, že je potrebné buď aktívnejšie spolupracovať s inými produktovými radami, znižovať nákupné ceny alebo stimulovať dopyt - ale to je iný príbeh.
3. Odrežte všetky neprioritné oblasti a stále existuje príliš veľa sémantiky
Keď hovoria o „orezaní“ sémantiky, tí, ktorí s tým pracovali, spravidla znamenajú odstránenie nízkofrekvenčných dotazov s frekvenciou pod určitou hranicou. V tematických diskusiách na Facebooku a na fórach pravidelne vidím čísla od 5 do 10 (čo znamená celkovú frekvenciu požiadavky).
To znamená, že všetko, čo má frekvenciu menšiu ako 10, je zámerne odstránené z poľa.
Je jasné, že to dokážete, ak máte stále veľa sémantiky. Vždy však ide o výber medzi konzumáciou rýb a sedením na nepohodlných predmetoch. Ak príliš veľa odstránite, budú vám chýbať niektoré vylučujúce kľúčové slová, pri spustení získate väčšiu „špinavú“ návštevnosť, ale priberiete na nákladoch práce.
Môj názor je tento: bod podmienenej rovnováhy je tu na úrovni „odstraňujeme všetko, čo nemá frekvenciu“. To vám umožní vyhodiť asi polovicu polí prijatých z rôznych zdrojov a zároveň zostane prevádzka pri štarte veľmi čistá, s chybou doslova 1-3% a rýchlo sa vyčistí.
Čo znamená „upratať“
Hovory? Nie tiež, pretože stránka má obrovský vplyv na počet hovorov: možno je s kampaňou všetko v poriadku, iba je stránka nesprávne vytvorená.
Účinnosť kampane vo vyhľadávaní môžete rýchlo skontrolovať na serveri Yandex.Metrica. Na to potrebujeme dva alebo tri dni po spustení kampane získať správu o frázach, ktoré slúžili ako zdroje konverzie. Ako nájsť túto správu v Metrica:
Kliknite na kríž vo všetkých skupinách, okrem „Hľadať frázu“, a potom na „Použiť“. Dostaneme správu o frázach, pre ktoré používatelia videli naše reklamy, klikli na ne a navštívili naše stránky. Čo robiť s touto správou?
Starostlivo si prečítajte a zvýraznite irelevantné frázy, ktoré nie sú relevantné pre vaše podnikanie. V žargóne sa im hovorí „smeti“. V profesionálne vykonaných kampaniach po prvom spustení môže byť podiel „odpadkov“ od 1 do 4%, v kampaniach zbieraných „na kolene“ - až 20 - 40%.
Ako ste už pravdepodobne pochopili, postup s dodatočným čistením odpadu by sa mal vykonávať pravidelne - najmenej dvakrát až trikrát za mesiac. Prečo tak často?
Mali sme zaujímavý príklad z praxe. Pracovali sme s kampaňou, do ktorej sme pre klienta zaradili dopyt s vysokou maržou „čierna dymová nafta“. Klient pracoval s naftovými motormi a takáto požiadavka znamená, že klient má vážny problém s motorom a pravdepodobne aj potreba kvalifikovaných služieb.
V septembri 2016, keď zoskupenie ruskej flotily zamierilo do Sýrie, lietadlová loď „Admirál Kuznetsov“ upútala pozornosť medzinárodných médií silným čiernym dymom z výfukového potrubia. To nevyhnutne vyvolalo požiadavky ako „nafta s čiernym dymom admirál Kuznetsov“.
Predtým jednoducho neexistovali žiadne takéto požiadavky, takže neexistovali žiadne nevýhody formátu „-admirál, -kuznetsov“. Preto sa naša reklama nielen zobrazila na takéto žiadosti, ale generovala aj nezmyselné kliknutia, ktoré nemali žiadnu obchodnú hodnotu.
Takéto dotazy je možné rýchlo sledovať iba v „metrikách“: urobte preto na začiatku kampane pravidlom kontrolovať sémantiku častejšie (neskôr - menej často) a navyše mínus nové odpadky.
Samozrejme, vzniká otázka: čo vo všeobecnosti ovplyvňuje množstvo odpadu. Je to jednoduché - štatistická spoľahlivosť sémantiky.
Čo ovplyvňuje objem sémantiky
Ľudia nie vždy chápu, o čom hovoria, keď diskutujú o vplyve veľkého sémantického jadra na cenu za kliknutie, kvalitu kampane a podobne. Bohatá sémantika sama osebe nevedie k zníženiu nákladov na kliknutie ani k zvýšeniu kvality kampane. Aký je skutočný vplyv stoviek a tisícov zhromaždených dopytov LF?
1. Čistota dopravy pri spustení kampane
Čím viac dotazov zozbierate, tým viac negatívnych kľúčových slov nájdete. Na nekonečne veľkej vzorke dopytov nájdete všetky možné vylučujúce kľúčové slová a strávite tým nekonečné množstvo času.
V praxi stojí za to obmedziť sa na požiadavky, ako som povedal, s frekvenciou 1 pre požadovaný región - pri spustení to poskytne „odpadky“ v oblasti 3-4%, po ktorých rýchlo vyčistíte zostávajúce žiadosti o odpadky, mínusy, z ktorých z nejakého dôvodu nie sú, boli zahrnuté do vzorky.
Pri tom by ste mali používať rady programu WordStat aj vyhľadávače a zhromažďovať rady pre každý dotaz prijatý v programe WordStat. Samotné používanie programu WordStat poskytne veľké množstvo odpadu - najmenej 10 - 15% pri spustení (ak nie viac). Všetci však chápeme, že čím viac odpadkov, tým viac finančných prostriedkov sa vynaloží, tým menej potenciálnych zákazníkov na jednotku nákladov.
2. Relevancia reklám pre dopyty
Skutočná návštevnosť, ktorá sa dostane na váš web, nepochádza väčšinou z požiadaviek, ktoré ste pridali do kampane, ale z rozšírení z nich. Na jeden dotaz pridaný do kampane existujú najmenej tri alebo štyri rozšírené možnosti - jedná sa o ultranízke frekvencie, ktoré nemôžete vôbec predvídať, používatelia ich generujú hneď v okamihu hľadania.
Preto samotná požiadavka nie je taká dôležitá: na ultranízkych frekvenciách je taký veľký prenos s frekvenciou prechodu jeden alebo dvakrát za mesiac alebo za rok, že nemá zmysel viazať sa na konkrétnu požiadavku. Je dôležité zozbierať štatisticky významnú sémantiku, rozdeliť ju na malé skupiny podobných dopytov a vytvárať pre ne reklamy.
Viac sémantiky znamená viac skupín, väčšiu presnosť zhody a nižšie náklady na kampane vo vyhľadávaní. V konkrétnej skupine podobných extrémne nízkych frekvencií, z ktorej sa vytvorí reklama, môže existovať päť až desať dopytov - a ak do šesť mesiacov z tejto reklamy extrahujete frázy z Metrica, dostanete zoznam najmenej 30 -40 fráz.
Opakujem: sémantika nie je všeliekom na všetko a nie božstvom. Sémantika veľa ovplyvňuje: čistotu návštevnosti, relevanciu reklám pre dopyty - ale nie všetko. Nemá zmysel zbierať obrovské vzorky „núl“ v nádeji, že sa tým zlacní doprava - to sa nestane.
Sémantika ovplyvňuje:
Tu sú faktory, ktoré by ste si mali najskôr zapamätať. Skúsme však v skratke zhrnúť výsledky.
Stručne
- Zhromažďujte základné otázky - všeobecné frázy popisujúce vaše produkty a služby.
- Skontrolujte, či ste zhromaždili všetky synonymá a reformulácie: WordStat, ktorý vám pomôže, a blok „podobných dotazov“ v SERP.
- Zhromažďujte rozšírenia pre prijaté žiadosti: WordStat, rady pre vyhľadávanie, databázu MOAB - všetko ide do činnosti.
- Vytvorte tabuľku, v ktorej bude vedľa každého základu uvedená jeho frekvencia a počet rozšírených požiadaviek.
- Ak je žiadostí príliš veľa a nemáte čas ich spracovať, uprednostnite základne v závislosti od rozpätia, frekvencie a počtu požiadaviek.
- Bol vytvorený konečný sémantický plán. Teraz je čas vyčistiť a zoskupiť sémantiku.
Optimalizácia a propagácia webových stránok vždy začína zhromažďovaním sémantického jadra stránky a výberom kľúčových slov k téme stránky, v závislosti od toho, ako správne je sémantické jadro zostavené, závisí úspech propagácie a optimalizácie stránky.
Pozrime sa podrobnejšie na to, ako správne zostaviť sémantiku pre web, aké chyby sa vyskytujú pri výbere dopytov a aké základné nástroje sa používajú na zhromažďovanie sémantiky.
Sémantické jadro stránok je zoskupené do samostatných kategórií kľúčové dotazy (slová) zodpovedajúce téme vášho webu a umožňujúce používateľom nájsť váš web na internete prostredníctvom vyhľadávača (Yandex alebo Google).
Dobre vyvinuté sémantické jadro umožní každej stránke vášho zdroja splniť konkrétne požiadavky používateľov a pomôže vám efektívne predávať vaše produkty a služby, ako aj budete schopní pritiahnuť na stránku cieľové publikum.

DÔLEŽITÉ! K zostaveniu sémantiky webu je potrebné pristupovať veľmi zodpovedne a obozretne, pretože vybrané kľúčové slová budú použité, keď:
- interná optimalizácia stránok (prepojenie, metaznačky)
- optimalizácia externých webových stránok (nákup odkazov)
- príprava reklamných kampaní (kontextová reklama, sociálne siete)
Prečítajte si pozorne článok a neváhajte sa opýtať na otázky v komentároch alebo napísať sociálne siete, Rád odpoviem na každý komentár a otázku.
Základné pojmy a pojmy
Dopyty (kľúčové slová)- zhromažďuje ich vyhľadávací nástroj (Yandex alebo Google) na účely štatistiky a používajú ich vyhľadávače s Yandex Direct alebo Google AdWords.
Aby ste získali sémantické jadro, musíte definovať zoznam služieb a tovarov, ktoré chcete propagovať, a presne vybrať, aké požiadavky budú používatelia a zákazníci vyhľadávať váš tovar alebo služby.
Prvým krokom pri zostavovaní sémantiky je napíšte všetky najdôležitejšie slová charakterizujúce tému vášho webu a potom napíšte pravdepodobne pre každú kategóriu slov, fráz a fráz, podľa ktorých vás môžu používatelia hľadať v sieti (váš tovar alebo služby).

Na presnejšie zozbieranie jadra žiadostí musíte pochopiť, aké typy žiadostí sú a aké typy žiadostí sú vhodné pre váš web.
Napríklad poskytujete servis mobilné telefóny v určitej oblasti. Je zbytočné a veľmi nákladné snažiť sa, aby bol váš web prvý na žiadosť „oprava smartfónu“, pretože existuje veľmi vysoká frekvencia tejto požiadavky, ale aj veľmi vysoká konkurencia.
Aké typy žiadostí existujú?
Najdôležitejšia vec, podľa ktorej SEO optimalizátory triedia dotazy, je frekvencia dopytov. Existujú 3 hlavné kategórie žiadostí:

Vysokofrekvenčné požiadavky (HF) - najpopulárnejšie otázky pozostávajú hlavne z 1 - 2 slov a charakterizujú tému všeobecne. Mnoho SEO rozdeľuje frekvenciu na základe čísel a začína HF dopytmi od 3 000 do 5 000 tisíc dopytov mesačne. Osobne si myslím, že tento prístup je nevhodný, a KV otázky charakterizujem ako otázky, ktoré sú v danej téme najobľúbenejšie, a charakterizujem tému ako celok.
Príklad:kup si hodinky(151 759 žiadostí mesačne v Moskve a Moskovskom regióne) príp objednať webovú stránku (14 019 žiadostí mesačne v Moskve a moskovskom regióne).
Žiadosti o stredné frekvencie (MF)- dotazy sú menej populárne a zvyčajne majú 2 až 4 slová, rovnako sú presnejšie a zamerané tak z hľadiska geografického významu, ako aj z praktického hľadiska. Podľa môjho názoru je reklama na stredne frekvenčné dopyty najúčinnejšia a cielenejšia a poskytuje vynikajúci výsledok.
Príklad:kupujte hodinky lacno(8 596 žiadostí mesačne v Moskve a Moskovskom regióne) príp objednajte si lacno webovú stránku (439 žiadostí mesačne v Moskve a Moskovskom regióne).
Nízkofrekvenčné požiadavky (LF)- najnepopulárnejšie požiadavky pozostávajúce zo 4 až 7 slov, ktoré majú presný charakter žiadosti a veľmi konkrétne poslanie. Propagácia na nízkofrekvenčných požiadavkách je spravidla najúčinnejšia a najrýchlejšia, tu je potrebné postupovať podľa zásady „čím viac, tým lepšie“.
Príklad:kde môžem kúpiť lacné hodinky?(90 žiadostí mesačne v Moskve a Moskovskom regióne) alebo kde objednajte si web lacno (39 žiadostí mesačne v Moskve a Moskovskom regióne).
Okrem frekvencie je pre správny zber sémantického jadra pre nový web potrebné pochopiť aj to, ako konkurencieschopná je požiadavka. Určenie súbežnosti žiadosti je veľmi jednoduché.

Zadajte dotaz do vyhľadávacieho poľa a zobrazí sa vám počet stránok v základni vyhľadávača zodpovedajúcich dopytu. Čím vyššia je konkurencia, tým ťažšie je dostať sa pre danú frázu do TOP-10.
Pokiaľ ide o konkurencieschopnosť, žiadosti sú tieto:
- Vysoko konkurencieschopný (VK)
- Stredne konkurencieschopný (Spojené kráľovstvo)
- Nízka konkurencia (NK)
Vysoko konkurenčné vysokofrekvenčné dotazy (HF VK) sú jedným z najťažšie propagovateľných (napríklad pri kúpe hodiniek), takže keď vytvoríte sémantické jadro pre nový web, je lepšie nemrhať časom a ignorovať ich .
Etapy zostavovania sémantického jadra
Celú prácu na zhromažďovaní sémantického jadra je možné rozdeliť do niekoľkých jednoduchých krokov. Predtým, ako budete pokračovať vo vytváraní sémantického jadra, mali by ste v excle vytvoriť súbor, do ktorého napíšete všetky stránky svojho webu, čím vytvoríte štruktúru sémantického jadra.

Predpokladajme, že predávate zariadenie na sledovanie videa, na stránke máte veľký počet kategórií a podkategórií, musíte do súboru zapísať všetky kategórie a podkategórie v plnom rozsahu.
Príklad:
Vreckové hodinky
- mechanické hodinky
- mechanické pánske hodinky
- mechanické dámske hodinky- kremenné hodinky
- Digitálne hodinky
Hodiny starého otca
- mechanická pružina
- mechanický kettlebell
Zhromažďujeme všetky možné tematické otázky
Najprv musíte vytvoriť „kostru“ jadra požiadaviek, stránok vášho webu, hlavných kategórií tovarov a služieb, potom do každej kategórie pridáte podkategórie a podsekcie.

Otvoríte štandardný nástroj na zostavovanie sémantiky „Yandex Wordstat“ a do vyhľadávacieho panela zadáte všetky očakávané kľúčové slová vhodné pre určitú kategóriu. Zapisovanie všetkých slov do súboru bez výnimky.
Doplnok pre prehliadač Yandex Wordstat Assistant pomáha veľmi dobre fungovať pri výbere dopytov v programe Wordstat (pokyny sú priložené)
Ak je váš web regionálne spojený, vyberte región svojho webu. Pomôže vám to presnejšie porozumieť tomu, ako často používatelia zadávajú dotazy na vašu tému vo vašom regióne. (Vopred odfiltrujte a zahoďte všetky slová, ktoré sa netýkajú vášho regiónu)
Zhromažďujte všetky možné otázky súvisiace s vašou témou a súvisiace s obsahom vašich stránok. Keď máte zhromaždené všetky požiadavky pre každú stránku, môžete prejsť na ďalší krok.
Filtrovanie nevhodných a prázdnych dopytov
V tejto fáze by ste mali mať veľký štruktúrovaný súbor zoskupený do sekcií, ktorý obsahuje veľký počet kľúčových slov relevantných pre predmet vášho webu.
Medzi kľúčovými dopytmi, ktoré ste vybrali, musíte vybrať a odstrániť určité dopyty:
- Duplicitné kľúčové slová„Kúpte si hodinky“ a „kúpte si hodinky“ (nechať požiadavku, ktorá znie prirodzenejšie, stojí za to).
- Zadané alebo nesprávne zadané kľúčové slová„Kúpte si hodinky“ alebo „kúpte si hodinky Murzhsky“.
- Kľúčové otázky týkajúce sa značky alebo značky, ktorú nepredávate„Kúpte si hodinky Apple“ alebo „Kúpte si inteligentné hodinky“.
- Žiadosti uvádzajúce región, v ktorom nie ste zastúpení„Kúpte si hodinky v Novosibirsku“, „Kúpte si hodinky z Petrohradu“ (ak pracujete v určitom meste, okamžite vylúčte tieto požiadavky zo zoznamu a ponechajte iba región svojej prítomnosti)
- Odstráňte slová obsahujúce mená vašich konkurentov z dopytov(Odporúčam zaradiť ich do samostatného zoznamu a inzerovať podľa týchto požiadaviek v Yandex Direct, tieto žiadosti budú lacné a zákazníkov môžete čiastočne odobrať konkurentovi)
- Všeobecné typy informácií(sťahovanie, zadarmo, použité, vlastné, recenzia, recenzie) v akejkoľvek téme ľudia hľadajú návody alebo recenzie na výber produktu alebo hľadajú spôsob, ako vytvoriť alebo stiahnuť určitý obsah zadarmo, pretože vašim cieľom predaja tovaru a služieb je stojí za to tieto slová vymazať.
Po odstránení všetkých vyššie uvedených kľúčových slov a vyčistení sémantického jadra by ste sa mali znova dôkladne pozrieť na celý zoznam a zopakovať čistenie dotazov.
Odstránenie zdieľaných a vysoko konkurenčných kľúčov
V praxi mnoho vysokofrekvenčných a vysoko konkurenčných slov neprináša zisk, peniaze a čas vynaložený na ich propagáciu nie sú opodstatnené, pretože nie je úplne jasné, aké informácie klient hľadá pri zadávaní vysokofrekvenčnej požiadavky.

Príklad: keď používateľ zadá dotaz „mechanické hodinky“, chce vedieť, ako fungujú, alebo zistiť, ako ich opraviť, alebo porozumieť tomu, ktoré hodinky sa považujú za mechanické. Je pre vás ťažké to predpovedať, preto by takéto žiadosti mali byť vymazané. Najlepšia požiadavka pre vás je „kúpte si mechanické hodinky“ alebo „opravte mechanické hodinky“.
Preto odporúčam odstrániť sémantické jadro dotazy s najvyššou frekvenciou. Ušetríte tak čas i peniaze investované do propagácie webových stránok. Po odstránení všetkých bežných dotazov RF môžete predpokladať, že vaše sémantické jadro je pripravené.
Musíte mať súbor so štruktúrou, ktorá opakuje štruktúru webu a pre každú stránku boli vybraté slová na propagáciu.
Služby zhromažďovania sémantického jadra
Ako už bolo uvedené, vyhľadávacie nástroje zhromažďujú údaje z dopytov, aby predpovedali rozpočet v reklamných službách (Yandex Direct a Google AdWords). Na zhromažďovanie sémantického jadra sa používajú platené služby i samostatné programy a bezplatné služby z vyhľadávačov. Rýchlo sa pozrieme na každého z nich.
Bezplatné služby
Bezplatné služby na zhromažďovanie sémantického jadra sú najobľúbenejšie a najčastejšie používané vyhľadávač má svoju vlastnú službu, ale zvážime iba dve z najpopulárnejších.

Yandex Wordstat- jedna z najobľúbenejších služieb, ktorá vám umožňuje presnejšie zistiť, aké kľúčové dopyty použili používatelia vyhľadávacieho nástroja Yandex, má schopnosť vidieť „sezónnosť konkrétneho dopytu“ a „regionálny odkaz na dopyt“ .

Plánovač kľúčových slov (Google AdWords)- s výberom slov v službe Google je všetko oveľa zaujímavejšie a na prvý pohľad komplikovanejšie ako v programe Wordstat, ale môžete získať podrobnejšie a podrobnejšie informácie o požiadavke, vyhodnotiť konkurencieschopnosť žiadosti a tiež okamžite získať veľa podobných kľúčov. Mnoho ľudí používa Wordstat a dopĺňa svoje dotazy plánovačom kľúčových slov.

Slovoeb Je to veľmi zaujímavý nástroj (samostatný program), ktorý je distribuovaný bezplatne a pomáha v ňom vytvárať sémantické jadrá. Plná štruktúra katalógu a zber údajov z Wordstatu a AdWords, flexibilné v nastaveniach a veľmi pohodlné.
Platené služby
Platené programy a služby vám umožňujú výrazne rozšíriť základňu vašich kľúčových slov, pretože zhromažďujú nielen dotazy od online služba vyhľadávače, ale berú do úvahy aj dodatočné údaje.

Zberač kľúčov- jeden z najbežnejších a obľúbené programy medzi optimalizátormi Seo. Umožňuje vám efektívnejšie vyčistiť sémantické jadro a je veľmi užitočný pre veľké jadrá dotazov, pretože v tomto programe môžete vytvoriť komplexnú štruktúru a nenechať sa zmiasť. Licencia sa kúpi 1krát a budete ju používať doživotne. Pri neustálom používaní program stojí za 100% investovanie.

- online služba na zhromažďovanie kľúčových slov a zostavovanie sémantického jadra, platíte za predplatné s niekoľkými verziami, často používané optimalizátormi SEO
Chyby pri zostavovaní sémantického jadra
Na samom konci stojí za zváženie najčastejších chýb pri vytváraní sematického jadra:
- Nesledujte vysokofrekvenčné požiadavky- ak sa zaoberáte internetovým obchodom predávajúcim tovar alebo poskytujete služby, je dôležité, aby ste boli na prvom mieste v transakčných problémoch
- nezneužívajte žiadosti o informácie-vašim cieľom nie je odpovedať na otázky používateľa, ale predať mu váš produkt alebo službu
- veľa požiadaviek na stránku- 20 kľúčov na stránku je príliš veľa, ak takú stránku máte, oddeľte z nej bežné požiadavky na samostatnú stránku a propagujte dve stránky s 10 požiadavkami na každú.
závery
Na úspešnú propagáciu a optimalizáciu webu (blogu) je potrebné vytvoriť kvalitné sémantické jadro, ak sa sami nechcete zaoberať zostavovaním sémantického jadra, odporúčam kontaktovať spoločnosť Semyon Yadren a objednať si jeho sémantiku. .
Odporúčame vám pozrieť si video „Ako si vytvoriť sémantické jadro pre svojpomoc“