Сегодня особенно активно обсуждается и многие пользователи интересуются, с чего начать добычу монет и как это вообще происходит. Популярность этой индустрии уже оказала ощутимое влияние на рынок графических процессоров и мощная видеокарта у многих уже давно ассоциируется не с требовательными играми, а с криптофермами. В данной статье мы расскажем о том, как организовать весь этот процесс с нуля и начать майнить на собственной ферме, что для этого использовать и почему невозможен .
Что такое майнинг на видеокарте
Майнинг на видеокарте - это процесс добычи криптовалюты с помощью графических процессоров (GPU). Для этого используют мощную видеокарту в домашнем компьютере или специально собранную ферму из нескольких устройств в одной системе. Если вас интересует, почему для этого процесса используются именно GPU, то ответ весьма прост. Всё дело в том, что видеокарты изначально разрабатываются для обработки большого количества данных путём произведения однотипных операций, как в случае с обработкой видео. Такая же картина наблюдается и в майнинге криптовалюты, ведь тут процесс хэширования столь же однотипен.
Для майнинга используются полноценные дискретные видеокарты. Ноутбуки или интегрированный в процессор чипы не используются. В сети также встречаются статьи про майнинг на внешней видеокарте, но это также работает не во всех случаях и является не лучшим решением.
Какие видеокарты подойдут для майнинга
Итак, что касается выбора видеокарты, то здесь обычной практикой является приобретение AMD rx 470, rx 480, rx 570, rx 580 или Нвидиа 1060, 1070, 1080 ti. Также подойдут, но не принесут большой прибыли, видеокарты типа r9 280x, r9 290, 1050, 1060. Совершенно точно не принесёт прибыли майнинг на слабой видеокарте вроде geforce gtx 460, gts 450, gtx 550ti. Если говорить о памяти, то брать лучше от 2 гб. Может оказаться недостаточно даже 1 гб, не говоря уже о 512 мб. Если говорить про майнинг на профессиональной видеокарте, то приносит он примерно столько же, сколько и обычные или даже меньше. С учётом стоимости таких ВК - это невыгодно, но добывать с их помощью можно, если они уже есть у вас в наличии.
Стоит также отметить, что все видеокарты могут получить прирост производительности благодаря разблокировке значений, которые заложил производитель. Такой процесс называется разгон. Однако это небезопасно, приводит к потере гарантии и карта может выйти из строя, например, начав показывать артефакты. Разгонять видеокарты можно, но нужно ознакомиться с материалами по данной теме и действовать с осторожностью. Не стоит пытаться сразу установить все значения на максимум, а ещё лучше найти в интернете примеры удачных настроек разгона именно для вашей видеокарты.
Самые популярные видеокарты для майнинга 2020
Ниже приведено сравнение видеокарт. Таблица содержит самых популярных устройств и их максимальное энергопотребление. Нужно сказать, что эти показатели могут варьироваться в зависимости от конкретной модели видеокарты, её производителя, используемой памяти и некоторых других характеристик. Писать об устаревших показателях, таких как майнинг лайткоин на видеокарте, нет смысла, поэтому рассматриваются только три самых популярных алгоритма для ферм на видеокартах.
| Видеокарта | Ethash | Equihash | CryptoNight | Энергопотребление |
|---|---|---|---|---|
| AMD Radeon R9 280x | 11 MH/s | 290 H/s | 490 H/s | 230W |
| AMD Radeon RX 470 | 26 MH/s | 260 H/s | 660 H/s | 120W |
| AMD Radeon RX 480 | 29.5 MH/s | 290 H/s | 730 H/s | 135W |
| AMD Radeon RX 570 | 27.9 MH/s | 260 H/s | 700 H/s | 120W |
| AMD Radeon RX 580 | 30.2 MH/s | 290 H/s | 690 H/s | 135W |
| Nvidia GeForce GTX 750 TI | 0.5 MH/s | 75 H/s | 250 H/s | 55W |
| Nvidia GeForce GTX 1050 TI | 13.9 MH/s | 180 H/s | 300 H/s | 75W |
| Nvidia GeForce GTX 1060 | 22.5 MH/s | 270 H/s | 430 H/s | 90W |
| Nvidia GeForce GTX 1070 | 30 MH/s | 430 H/s | 630 H/s | 120W |
| Nvidia GeForce GTX 1070 TI | 30.5 MH/s | 470 H/s | 630 H/s | 135W |
| Nvidia GeForce GTX 1080 | 23.3 MH/s | 550 H/s | 580 H/s | 140W |
| Nvidia GeForce GTX 1080 TI | 35 MH/s | 685 H/s | 830 H/s | 190W |
Возможен ли майнинг на одной видеокарте?
Если у вас нет желания собирать полноценную ферму из множества GPU или вы просто хотите опробовать этот процесс на домашнем компьютере, то можно майнить и одной видеокартой. Никаких отличий нет и вообще количество устройств в системе не важно. Более того, вы можете установить устройства с разными чипами или даже от разных производителей. Потребуется лишь запустить параллельно две программы для чипов разных компаний. Напомним ещё раз, что майнинг на интегрированной видеокарте не производится.
Какие криптовалюты можно майнить на видеокартах

Майнить на GPU можно любую криптовалюту, но следует понимать, что производительность на разных будет отличаться на одной и той же карточке. Более старые алгоритмы уже плохо подходят для видеопроцессоров и не принесут никакой прибыли. Происходит это из-за появления на рынке новых устройств - так называемых . Они являются куда более производительными и значительно повышают сложность сети, однако их стоимость высока и исчисляется тысячами долларов. Поэтому добыча монет на SHA-256 (Биткоин) или Scrypt (Litecoin, Dogecoin) в домашних условиях - это плохая идея в 2018-ом году.
Кроме LTC и DOGE, ASICи сделали невозможной добычу Bitcoin (BTC), Dash и других валют. Куда лучшим выбором станут криптовалюты, которые используют защищенные от ASIC-ов алгоритмы. Так, например, с помощью GPU получится добывать монеты на алгоритмах CryptoNight (Карбованец, Монеро, Electroneum, Bytecoin), Equihash (ZCash, Hush, Bitcoin Gold) и Ethash (Ethereum, Ethereum Classic). Список далеко не полный и постоянно появляются новые проекты на этих алгоритмах. Среди них встречаются как форки более популярных монет, так и совершенно новые разработки. Изредка даже появляются новые алгоритмы, которые предназначены для решения определённых задач и могут использовать различное оборудование. Ниже будет рассказано о том, как узнать хешрейт видеокарты.
Что нужно для майнинга на видеокарте

Ниже приведён список того, что вам понадобится для создания фермы:
- Сами видеокарты. Выбор конкретных моделей зависит от вашего бюджета или того, что уже имеется в наличии. Конечно, старые устройства на AGP не подойдут, но можно использовать любую карту среднего или топового класса последних годов. Выше вы можете вернуться к таблице производительности видеокарт, которая позволит сделать подходящий выбор.
- Компьютер для их установки. Не обязательно использовать топовое железо и делать ферму на базе высокопроизводительных комплектующих. Достаточно будет какого-нибудь старого AMD Athlon, нескольких гигабайт оперативной памяти и жесткого диска для установки операционной системы и нужных программ. Важна также материнская плата. Она должна иметь достаточное для вашей фермы количество PCI слотов. Существуют специальные версии для майнеров, которые содержат 6-8 слотов и в определённых случаях выгодней использовать их, чем собирать несколько ПК. Особое внимание стоит уделять лишь блоку питания, ведь система будет работать под высокой нагрузкой круглые сутки. Брать БП нужно обязательно с запасом мощности и желательно наличие сертификатов 80 Plus. Возможно также соединение двух блоков в один с помощью специальных переходников, но такое решение вызывает в интернете споры. Корпус лучше не использовать вовсе. Для лучшего охлаждения рекомендуется сделать или купить специальный стенд. Видеокарты в таком случае выносятся с помощью специальных переходников, которые называются райзеры. Приобрести их можно в профильных магазинах или на алиэкспрессе.
- Хорошо проветриваемое сухое помещение. Размещать ферму стоит в нежилой комнате, а лучше вообще в отдельном помещении. Это позволит избавиться от дискомфорта, который возникает из-за шумной работы систем охлаждения и теплоотдачи. Если такой возможности нет, то следует выбирать видеокарты с максимально тихой системой охлаждения. Узнать о ней подробней вы сможете из обзоров в интернете, например, на YouTube. Следует также подумать о циркуляции воздуха и вентилируемости, чтобы максимально снизить температуру.
- Программа майнер. GPU майнинг происходит с помощью специального , которое может быть найдено в интернете. Для производителей ATI Radeon и Nvidia используется разный софт. Это же касается и разных алгоритмов.
- Обслуживание оборудования. Это очень важный пункт, так как не все понимают, что майнинг ферма требует постоянного ухода. Пользователю нужно следить за температурой, менять термопасту и очищать СО от пыли. Следует также помнить о технике безопасности и регулярно проверять исправность системы.
Как настроить майнинг на видеокарте с нуля
В данном разделе нами будет рассмотрен весь процесс добычи от выбора валюты до вывода средств. Следует отметить, что весь этот процесс может несколько отличаться для различных пулов, программ и чипов.
Как выбрать видеокарту для майнинга
Мы рекомендуем вам ознакомиться с таблицей, которая представлена выше и с разделом о подсчёте потенциального заработка. Это позволит рассчитать примерный доход и определиться с тем, какое железо вам больше по карману, а также разобраться со сроками окупаемости вложений. Не стоит также забывать о совместимости разъёмов питания видеокарты и блока питания. Если используются разные, то следует заранее обзавестись соответствующими переходниками. Всё это легко покупается в китайских интернет магазинах за копейки или у местных продавцов с некоторой наценкой.
Выбираем криптовалюту
Теперь важно определиться с тем, какая монета вас интересует и каких целей вы хотите достичь. Если вас интересует заработок в реальном времени, то стоит выбирать валюты с наибольшим профитом на данный момент и продавать их сразу после получения. Можно также майнить самые популярные монеты и держать их до тех пор, пока не произойдёт скачок цены. Есть также, своего рода, стратегический подход, когда выбирается малоизвестная, но перспективная на ваш взгляд валюта и вы вкладываете мощности в неё, в надежде, что в будущем стоимость значительно возрастёт.
Выбираем пул для майнинга

Также имеют некоторые отличия. Некоторые из них требуют регистрации, а некоторым достаточно лишь адреса вашего кошелька для начала работы. Первые обычно хранят заработанные вами средства до достижения минимальной для выплаты суммы, либо в ожидании вывода вами денег в ручном режиме. Хорошим примером такого пула является Suprnova.cc. Там предлагается множество криптовалют и для работы в каждом из пулов достаточно лишь раз зарегистрироваться на сайте. Сервис прост в настройке и хорошо подойдёт новичкам.
Подобную упрощённую систему предлагает и сайт Minergate. Ну а если вы не хотите регистрироваться на каком-то сайте и хранить там заработанные средства, то вам следует выбрать какой-нибудь пул в официальной теме интересующей вас монеты на форуме BitcoinTalk. Простые пулы требуют лишь указания адреса для начисления крипты и в дальнейшем с помощью адреса можно будет узнавать статистику добычи.
Создаем криптовалютный кошелек
Данный пункт не нужен вам, если используете пул, который требует регистрацию и имеет встроенный кошелёк. Если же вы хотите получать выплаты автоматически себе на кошелёк, то попробуйте почитать о создании кошелька в статье о соответствующей монете. Данный процесс может существенно отличаться для разных проектов.
Можно также просто указывать адрес вашего кошелька на какой-то из бирж, но следует отметить, что не все обменные платформы принимают транзакции с пулов. Наилучшим вариантом будет создания кошелька непосредственно на вашем компьютере, но если вы работаете с большим количеством валют, то хранение всех блокчейнов будет неудобно. В таком случае стоит поискать надёжные онлайн кошельки, либо облегчённые версии, которые не требуют загрузки всей цепи блоков.
Выбираем и устанавливаем программу для майнинга
Выбор программы для добычи крипты зависит от выбранной монеты и её алгоритма. Наверное, все разработчики такого ПО имеют темы на BitcoinTalks, где можно найти ссылки на скачивание и информацию о том, как происходят настройка и запуск. Почти все эти программы имеют версии как для Виндовс, так и для Линукс. Большинство таких майнеров бесплатные, но некоторый процент времени они используют для подключения к пулу разработчика. Это своего рода комиссия за использование программного обеспечения. В некоторых случаях её можно отключить, но это приводит к ограничениям функционала.
Настройка программы заключается в том, что вы указываете пул для майнинга, адрес кошелька или логин, пароль (если есть) и другие опции. Рекомендуется, например, выставлять максимальный лимит температуры, при достижении которого ферма отключится, чтобы не вредить видеокартам. Регулируется скорость вентиляторов системы охлаждения и другие более тонкие настройки, которые вряд ли будут использоваться новичками.
Если вы не знаете, какое ПО выбрать, посмотрите наш материал, посвященный либо изучите инструкции на сайте пула. Обычно там всегда есть раздел, который посвящён началу работы. Он содержит перечень программ, которые можно использовать и конфигурации для .bat файлов. С его помощью можно быстро разобраться с настройкой и начать майнинг на дискретной видеокарте. Можно сразу создать батники для всех валют, с которыми вы хотите работать, чтобы в дальнейшем было удобнее переключаться между ними.
Запускаем майнинг и следим за статистикой

После запуска .bat файла с настройками вы увидите консольное окно, куда будет выводиться лог происходящего. Его также можно будет найти в папке с запускаемым файлом. В консоли вы можете ознакомиться с текущими показателем хешрейта и температурой карты. Вызывать актуальные данные обычно позволяют горячие клавиши.
Вы также сможете увидеть, если устройство не находит хэши. В таком случае будет выведено предупреждение. Случается это, когда что-то настроено неправильно, выбрано неподходящее для монеты программное обеспечение или ГПУ не функционирует должным образом. Многие майнеры также используют средства для удалённого доступа к ПК, чтобы следить за работой фермы, когда они находятся не там, где она установлена.
Выводим криптовалюту
Если вы используете пулы вроде Suprnova, то все средства просто накапливаются на вашем аккаунте и вы можете вывести их в любой момент. Остальные пулы чаще всего используют систему, когда средства начисляются автоматически на указанный кошелёк после получения минимальной суммы вывода. Узнать о том, сколько вы заработали, обычно можно на сайте пула. Требуется лишь указать адрес вашего кошелька или залогиниться в личный кабинет.
Сколько можно заработать?
Сумма, которую вы можете заработать, зависит от ситуации на рынке и, конечно, общего хешрейта вашей фермы. Важно также то, какую стратегию вы выберите. Необязательно продавать всё добытое сразу. Можно, например, подождать скачка курса намайненной монеты и получить в разы больше профита. Однако всё не так однозначно и предугадать дальнейшее развитие событий бывает просто нереально.
Окупаемость видеокарт

Подсчитать окупаемость поможет специальный онлайн калькулятор. В интернете их много, но мы рассмотрим этот процесс на примере сервиса WhatToMine . Он позволяет получать данные о текущем профите, основываясь на данных вашей фермы. Нужно только выбрать видеокарты, которые есть у вас в наличии, а потом добавить стоимость электроэнергии в вашем регионе. Сайт посчитает сколько вы можете заработать за сутки.
Следует понимать, что учитывается лишь текущее положение дел на рынке и ситуация может измениться в любой момент. Курс может упасть или подняться, сложность майнинга станет другой или появятся новые проекты. Так, например, может прекратиться добыча эфира в связи с возможным переходом сети на . Если прекратиться майнинг эфириума, то фермам нужно будет куда то направить свободные мощности, например, в майнинг ZCash на GPU, что повлияет на курс этой монеты. Подобных сценариев на рынке множество и важно понимать, что сегодняшняя картина может не сохраниться на протяжении всего срока окупаемости оборудования.
Одной из наиболее скрытых функций, в недавнем обновлении Windows 10, является возможность проверить, какие приложения используют ваш графический процессор (GPU). Если вы когда-либо открывали диспетчер задач, то наверняка смотрели на использование вашего ЦП, чтобы узнать, какие приложения наиболее грузят ЦП. В последних обновлениях добавлена аналогичная функция, но для графических процессоров GPU. Это помогает понять, насколько интенсивным является ваше программное обеспечение и игры на вашем графическом процессоре, не загружая программное обеспечение сторонних разработчиков. Есть и еще одна интересная функция, которая помогает разгрузить ваш ЦП на GPU. Рекомендую почитать, как выбрать .
Почему у меня нет GPU в диспетчере задач?
К сожалению, не все видеокарты смогут предоставить системе Windows статистику, необходимую для чтения графического процессора. Чтобы убедиться, вы можете быстро использовать инструмент диагностики DirectX для проверки этой технологии.
- Нажмите "Пуск " и в поиске напишите dxdiag для запуска средства диагностики DirectX.
- Перейдите во вкладку "Экран", справа в графе "драйверы " у вас должна быть модель WDDM больше 2.0 версии для использования GPU графы в диспетчере задач.
Включить графу GPU в диспетчере задач
Чтобы увидеть использование графического процессора для каждого приложения, вам нужно открыть диспетчер задач.
- Нажмите сочетание кнопок Ctrl + Shift + Esc , чтобы открыть диспетчер задач.
- Нажмите правой кнопкой мыши в диспетчере задач на поле пустое "Имя" и отметьте из выпадающего меню GPU. Вы также можете отметить Ядро графического процессора , чтобы видеть, какие программы используют его.
- Теперь в диспетчере задач, справа видна графа GPU и ядро графического процессора.

Просмотр общей производительности графического процессора
Вы можете отслеживать общее использование GPU, чтобы следить за ним при больших нагрузках и анализировать. В этом случае вы можете увидеть все, что вам нужно, на вкладке "Производительность ", выбрав графический процессор.

Каждый элемент графического процессора разбивается на отдельные графики, чтобы дать вам еще больше информации о том, как используется ваш GPU. Если вы хотите изменить отображаемые графики, вы можете щелкнуть маленькую стрелку рядом с названием каждой задачи. На этом экране также отображается версия вашего драйвера и дата, что является хорошей альтернативой использованию DXDiag или диспетчера устройств.

Говоря о параллельных вычислениях на GPU мы должны помнить, в какое время мы живем, сегодняшний день это время когда все в мире ускоренно настолько, что мы с вами теряем счет времени, не замечая, как оно проноситься мимо. Всё, что мы делаем, связано с высокой точностью и скоростью обработки информации, в таких условиях нам непременно нужны инструменты для того, чтобы обработать всю информацию, которая у нас есть и преобразовать её в данные, к тому же говоря о таких задачах надо помнить, что данные задачи необходимы не только крупным организациям или мегакорпорациям, в решение таких задач сейчас нуждаются и рядовые пользователи, которые, которые решают свои жизненные задачи, связанные с высокими технологиями у себя дома на персональных компьютерах! Появление NVIDIA CUDA было не удивительным, а, скорее, обоснованным, потому, как в скором времени будет необходимо обрабатывать значительно более трудоёмкие задачи на ПК, чем ранее. Работа, которая ранее занимала очень много времени, теперь будет занимать считанные минуты, соответственно это повлияет на общую картину всего мира!
Что же такое вычисление на GPU
Вычисления на GPU — это использование GPU для вычисления технических, научных, бытовых задач. Вычисление на GPU заключает в себе использование CPU и GPU с разнородной выборкой между ними, а именно: последовательную часть программ берет на себя CPU , в то время как трудоёмкие вычислительные задачи остаются GPU . Благодаря этому происходит распараллеливание задач, которое приводит к ускорению обработки информации и уменьшает время выполнения работы, система становиться более производительной и может одновременно обрабатывать большее количество задач, чем ранее. Однако, чтобы добиться такого успеха одной лишь аппаратной поддержкой не обойтись, в данном случае необходима поддержка ещё и программного обеспечения, что бы приложение могло переносить наиболее трудоёмкие вычисления на GPU .
Что такое CUDA
CUDA — технология программирования на упрощённом языке Си алгоритмов, которые исполняються на графических процессорах ускорителей GeForce восьмого поколения и старше, а также соответствующих карт Quadro и Tesla от компании NVIDIA. CUDA позволяет включать в текст Си программы специальные функции. Эти функции пишутся на упрощённом языке программирования Си и выполняются на графическом процессоре. Первоначальная версия CUDA SDK была представлена 15 февраля 2007 года. Для успешной трансляции кода на этом языке, в состав CUDA SDK входит собственный Си-компилятор командной строки nvcc компании NVIDIA. Компилятор nvcc создан на основе открытого компилятора Open64 и предназначен для трансляции host-кода (главного, управляющего кода) и device-кода (аппаратного кода) (файлов с расширением .cu ) в объектные файлы, пригодные в процессе сборки конечной программы или библиотеки в любой среде программирования, например в Microsoft Visual Studio.
Возможности технологии
- Стандартный язык C для параллельной разработки приложений на GPU .
- Готовые библиотеки численного анализа для быстрого преобразования Фурье и базового пакета программ линейной алгебры.
- Специальный драйвер CUDA для вычислений с быстрой передачей данных между GPU и CPU .
- Возможность взаимодействия драйвера CUDA с графическими драйверами OpenGL и DirectX .
- Поддержка операционных систем Linux 32/64-bit, Windows XP 32/64-bit и MacOS.
Преимущества технологии
- Интерфейс программирования приложений CUDA (CUDA API) основан на стандартном языке программирования Си с некоторыми ограничениями. Это упрощает и сглаживает процеcс изучения архитектуры CUDA .
- Разделяемая между потоками память (shared memory) размером в 16 Кб может быть использована под организованный пользователем кэш с более широкой полосой пропускания, чем при выборке из обычных текстур.
- Более эффективные транзакции между памятью центрального процессора и видеопамятью.
- Полная аппаратная поддержка целочисленных и побитовых операций.
Пример применения технологии
cRark
Самое трудоёмкое в этой программе — это настойка. Программа имеет консольный интерфейс, но благодаря инструкции, которая прилагается к самой программе, ей можно пользоваться. Далее приведена краткая инструкция по настройке программы. Мы проверим программу на работоспособность и сравним её с другой подобной программой, которая не использует NVIDIA CUDA , в данном случае это известная программа «Advanced Archive Password Recovery».
Из скаченного архива cRark нам нужно только три файла: crark.exe , crark-hp.exe и password.def . Сrark.exe — это консольная утилита вскрытия паролей RAR 3.0 без шифрованных файлов внутри архива (т.е. раскрывая архив мы видим названия, но не можем распаковать архив без пароля).
Сrark-hp.exe — это консольная утилита вскрытия паролей RAR 3.0 с шифрованием всего архива (т.е. раскрывая архив мы не видим ни названия, ни самих архивов и не можем распаковать архив без пароля).
Password.def - это любой переименованный текстовой файл с очень небольшим содержанием (к примеру: 1-я строка: ## 2-я строка: ?* , в этом случае вскрытие пароля будет происходить с использованием всех знаков). Password.def — это руководитель програмы cRark. В файле содержаться правила вскрытия пароля (или область знаков которую crark.exe будет использовать в своей работе). Подробнее о возможностях выбора этих знаков написано в текстовом файле полученном при вскрытии скачанного на сайте у автора программы cRark: russian.def .
Подготовка
Сразу скажу, что программа работает только если ваша видеокарта основана на GPU с поддержкой уровня ускорения CUDA 1.1. Так что серия видеокарт, основанных на чипе G80, таких как GeForce 8800 GTX , отпадает, так как они имеют аппаратную поддержку ускорения CUDA 1.0. Программа подбирает с помощью CUDA только пароли на архивы RAR версий 3.0+. Необходимо установить все программное обеспечение, связанное с CUDA , а именно:
- Драйверы NVIDIA , поддерживающие CUDA , начиная с 169.21
- NVIDIA CUDA SDK , начиная с версии 1.1
- NVIDIA CUDA Toolkit , начиная с версии 1.1
Создаём любую папку в любом месте (например на диске С:) и называем любым именем например «3.2». Помещаем туда файлы: crark.exe , crark-hp.exe и password.def и запароленный/зашифрованный архив RAR.
Далее, следует запустить консоль командной строки Windows и перейти в ней созданную папку. В Windows Vista и 7 следует вызвать меню «Пуск» и в поле поиска ввести «cmd.exe», в Windows XP из меню «Пуск» сначала следует вызвать диалог «Выполнить» и уже в нём вводить «cmd.exe». После открытия консоли следует ввести команду вида: cd C:\папка\ , cd C:\3.2 в данном случае.
Набираем в текстовом редакторе две строки (можно также сохранить текст как файл .bat в папке с cRark) для подбора пароля запароленного RAR-архива с незашифрованными файлами:
echo off;
cmd /K crark (название архива).rar
для подбора пароля запароленного и зашифрованного RAR-архива:
echo off;
cmd /K crark-hp (название архива).rar
Копируем 2 строки текстового файла в консоль и нажимаем Enter (или запускаем.bat файл).
Результаты
Процесс расшифровки показан на рисунке:
Скорость подбора на cRark с помощью CUDA составила 1625 паролей/секунду. За одну минуту тридцать шесть секунд был подобран пароль с 3-мя знаками: «q}$». Для сравнения: скорость перебора в Advanced Archive Password Recovery на моём двуядерном процессоре Athlon 3000+ равна максимум 50 паролей/секунду и перебор должен был бы длиться 5 часов. То есть подбор по bruteforce в cRark архива RAR с помощью видеокарты GeForce 9800 GTX+ происходит в 30 раз быстрее, чем на CPU .


Для тех, у кого процессор Intel, хорошая системная плата с высокой частотой системной шины (FSB 1600 МГц), показатель CPU rate и скорость перебора будут выше. А если у вас четырёхъядерный процессор и пара видеокарт уровня GeForce 280 GTX , то быстродействие перебора паролей ускоряется в разы. Подводя итоги примера надо сказать, что данная задача была решена с применением технологии CUDA всего за каких то 2 минуты вместо 5-ти часов что говорит о высоком потенциале возможностей для данной технологии!
Выводы
Рассмотрев сегодня технологию для параллельных вычислений CUDA мы наглядно увидели всю мощь и огромный потенциал для развития данной технологии на примере программы для восстановления пароля для RAR архивов. Надо сказать о перспективах данной технологии, данная технология непременно найдет место в жизни каждого человека, который решит ей воспользоваться, будь то научные задачи, или задачи, связанные с обработкой видео, или даже экономические задачи которые требуют быстрого точного расчета, всё это приведет к неизбежному повышению производительности труда, которое нельзя будет не заметить. На сегодняшний день в лексикон уже начинает входить словосочетание «домашний суперкомпьютер»; абсолютно очевидно, что для воплощения такого предмета в реальность в каждом доме уже есть инструмент под названием CUDA . Начиная с момента выхода карт, основанных на чипе G80 (2006 г.), выпущено огромное количество ускорителей на базе NVIDIA, поддерживающих технологию CUDA , которая способна воплотить мечты о суперкомпьютерах в каждом доме в реальность. Продвигая технологию CUDA , NVIDIA поднимает свой авторитет в глазах клиентов в виде предоставления дополнительных возможностей их оборудования, которое у многих уже куплено. Остается только лишь верить, что в скором времени CUDA будет развиваться очень быстро и даст пользователям в полной мере воспользоваться всеми возможностями параллельных вычислений на GPU .
Как-то раз довелось мне побеседовать на компьютерном рынке с техническим директором одной из многочисленных компаний, занимающихся продажами ноутбуков. Этот «специалист» пытался с пеной у рта объяснить, какая именно конфигурация ноутбука мне нужна. Главный посыл его монолога заключался в том, что время центральных процессоров (CPU) закончилось, и сейчас все приложения активно используют вычисления на графическом процессоре (GPU), а потому производительность ноутбука целиком и полностью зависит от графического процессора, а на CPU можно не обращать никакого внимания. Поняв, что спорить и пытаться вразумить этого технического директора абсолютно бессмысленно, я не стал терять времени зря и купил нужный мне ноутбук в другом павильоне. Однако сам факт такой вопиющей некомпетентности продавца меня поразил. Было бы понятно, если бы он пытался обмануть меня, как покупателя. Отнюдь. Он искренне верил в то, что говорил. Да, видимо, маркетологи в NVIDIA и AMD не зря едят свой хлеб, и им-таки удалось внушить некоторым пользователям идею о доминирующей роли графического процессора в современном компьютере.
Тот факт, что сегодня вычисления на графическом процессоре (GPU) становятся всё более популярными, не вызывает сомнения. Однако это отнюдь не принижает роли центрального процессора. Более того, если говорить о подавляющем большинстве пользовательских приложений, то на сегодняшний день их производительность целиком и полностью зависит от производительности CPU. То есть подавляющее количество пользовательских приложений не используют вычисления на GPU.
Вообще, вычисления на GPU главным образом выполняются на специализированных HPC-системах для научных расчетов. А вот пользовательские приложения, в которых применяются вычисления на GPU, можно пересчитать по пальцам. При этом следует сразу же оговориться, что термин «вычисления на GPU» в данном случае не вполне корректен и может ввести в заблуждение. Дело в том, что если приложение использует вычисление на GPU, то это вовсе не означает, что центральный процессор бездействует. Вычисление на GPU не предполагает переноса нагрузки с центрального процессора на графический. Как правило, центральный процессор при этом остается загруженным, а использование графического процессора, наряду с центральным, позволяет повысить производительность, то есть сократить время выполнения задачи. Причем сам GPU здесь выступает в роли своеобразного сопроцессора для CPU, но ни в коем случае не заменяет его полностью.
Чтобы разобраться, почему вычисления на GPU не являются эдакой панацеей и почему некорректно утверждать, что их вычислительные возможности превосходят возможности CPU, необходимо уяснить разницу между центральным и графическим процессором.
Различия в архитектурах GPU и CPU
Ядра CPU проектируются для выполнения одного потока последовательных инструкций с максимальной производительностью, а GPU - для быстрого исполнения очень большого числа параллельно выполняемых потоков инструкций. В этом и заключается принципиальное отличие графических процессоров от центральных. CPU представляет собой универсальный процессор или процессор общего назначения, оптимизированный для достижения высокой производительности единственного потока команд, обрабатывающего и целые числа, и числа с плавающей точкой. При этом доступ к памяти с данными и инструкциями происходит преимущественно случайным образом.
Для повышения производительности CPU они проектируются так, чтобы выполнять как можно больше инструкций параллельно. Например для этого в ядрах процессора используется блок внеочередного выполнения команд, позволяющий переупорядочивать инструкции не в порядке их поступления, что позволяет поднять уровень параллелизма реализации инструкций на уровне одного потока. Тем не менее это все равно не позволяет осуществить параллельное выполнение большого числа инструкций, да и накладные расходы на распараллеливание инструкций внутри ядра процессора оказываются очень существенными. Именно поэтому процессоры общего назначения имеют не очень большое количество исполнительных блоков.
Графический процессор устроен принципиально иначе. Он изначально проектировался для выполнения огромного количества параллельных потоков команд. Причем эти потоки команд распараллелены изначально, и никаких накладных расходов на распараллеливание инструкций в графическом процессоре просто нет. Графический процессор предназначен для визуализации изображения. Если говорить упрощенно, то на входе он принимает группу полигонов, проводит все необходимые операции и на выходе выдает пикселы. Обработка полигонов и пикселов независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому из-за изначально параллельной организации работы в GPU используется большое количество исполнительных блоков, которые легко загрузить, в отличие от последовательного потока инструкций для CPU.
Графические и центральные процессоры различаются и по принципам доступа к памяти. В GPU доступ к памяти легко предсказуем: если из памяти читается тексель текстуры, то через некоторое время придет срок и для соседних текселей. При записи происходит то же самое: если какойто пиксел записывается во фреймбуфер, то через несколько тактов будет записываться пиксел, расположенный рядом с ним. Поэтому GPU, в отличие от CPU, просто не нужна кэшпамять большого размера, а для текстур требуются лишь несколько килобайт. Различен и принцип работы с памятью у GPU и CPU. Так, все современные GPU имеют несколько контроллеров памяти, да и сама графическая память более быстрая, поэтому графические процессоры имеют гораздо бо льшую пропускную способность памяти, по сравнению с универсальными процессорами, что также весьма важно для параллельных расчетов, оперирующих огромными потоками данных.
В универсальных процессорах бо льшую часть площади кристалла занимают различные буферы команд и данных, блоки декодирования, блоки аппаратного предсказания ветвления, блоки переупорядочения команд и кэшпамять первого, второго и третьего уровней. Все эти аппаратные блоки нужны для ускорения исполнения немногочисленных потоков команд за счет их распараллеливания на уровне ядра процессора.
Сами же исполнительные блоки занимают в универсальном процессоре относительно немного места.
В графическом процессоре, наоборот, основную площадь занимают именно многочисленные исполнительные блоки, что позволяет ему одновременно обрабатывать несколько тысяч потоков команд.
Можно сказать, что, в отличие от современных CPU, графические процессоры предназначены для параллельных вычислений с большим количеством арифметических операций.
Использовать вычислительную мощь графических процессоров для неграфических задач возможно, но только в том случае, если решаемая задача допускает возможность распараллеливания алгоритмов на сотни исполнительных блоков, имеющихся в GPU. В частности, выполнение расчетов на GPU показывает отличные результаты в случае, когда одна и та же последовательность математических операций применяется к большому объему данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико. Эта операция предъявляет меньшие требования к управлению исполнением и не нуждается в использовании емкой кэшпамяти.
Можно привести множество примеров научных расчетов, где преимущество GPU над CPU в плане эффективности вычислений неоспоримо. Так, множество научных приложений по молекулярному моделированию, газовой динамике, динамике жидкостей и прочему отлично приспособлено для расчетов на GPU.
Итак, если алгоритм решения задачи может быть распараллелен на тысячи отдельных потоков, то эффективность решения такой задачи с применением GPU может быть выше, чем ее решение средствами только процессора общего назначения. Однако нельзя так просто взять и перенести решение какойто задачи с CPU на GPU, хотя бы просто потому, что CPU и GPU используют разные команды. То есть когда программа пишется под решение на CPU, то применяется набор команд х86 (или набор команд, совместимый с конкретной архитектурой процессора), а вот для графического процессора используются уже совсем другие наборы команд, которые опять-таки учитывают его архитектуру и возможности. При разработке современных 3D-игр применяются API DirectX и OрenGL, позволяющие программистам работать с шейдерами и текстурами. Однако использование API DirectX и OрenGL для неграфических вычислений на графическом процессоре - это не лучший вариант.
NVIDIA CUDA и AMD APP
Именно поэтому, когда стали предприниматься первые попытки реализовать неграфические вычисления на GPU (General Purpose GPU, GPGPU), возник компилятор BrookGPU. До его создания разработчикам приходилось получать доступ к ресурсам видеокарты через графические API OpenGL или Direct3D, что значительно усложняло процесс программирования, так как требовало специфических знаний - приходилось изучать принципы работы с 3D-объектами (шейдерами, текстурами и т.п.). Это явилось причиной весьма ограниченного применения GPGPU в программных продуктах. BrookGPU стал своеобразным «переводчиком». Эти потоковые расширения к языку Си скрывали от программистов трехмерный API и при его использовании надобность в знаниях 3D-программирования практически отпала. Вычислительные мощности видеокарт стали доступны программистам в виде дополнительного сопроцессора для параллельных расчетов. Компилятор BrookGPU обрабатывал файл с кодом Cи и расширениями, выстраивая код, привязанный к библиотеке с поддержкой DirectX или OpenGL.
Во многом благодаря BrookGPU, компании NVIDIA и ATI (ныне AMD) обратили внимание на зарождающуюся технологию вычислений общего назначения на графических процессорах и начали разработку собственных реализаций, обеспечивающих прямой и более прозрачный доступ к вычислительным блокам 3D-ускорителей.
В результате компания NVIDIA разработала программно-аппаратную архитектуру параллельных вычислений CUDA (Compute Unified Device Architecture). Архитектура CUDA позволяет реализовать неграфические вычисления на графических процессорах NVIDIA.
Релиз публичной бета-версии CUDA SDK состоялся в феврале 2007 года. В основе API CUDA лежит упрощенный диалект языка Си. Архитектура CUDA SDK обеспечивает программистам реализацию алгоритмов, выполнимых на графических процессорах NVIDIA, и включение специальных функций в текст программы на Cи. Для успешной трансляции кода на этом языке в состав CUDA SDK входит собственный Сикомпилятор командной строки nvcc компании NVIDIA.
CUDA - это кроссплатформенное программное обеспечение для таких операционных систем, как Linux, Mac OS X и Windows.
Компания AMD (ATI) также разработала свою версию технологии GPGPU, которая ранее называлась AТI Stream, а теперь - AMD Accelerated Parallel Processing (APP). Основу AMD APP составляет открытый индустриальный стандарт OpenCL (Open Computing Language). Стандарт OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. Это полностью открытый стандарт, его использование не облагается лицензионными отчислениями. Отметим, что AMD APP и NVIDIA CUDA несовместимы друг с другом, тем не менее, последняя версия NVIDIA CUDA поддерживает и OpenCL.
Тестирование GPGPU в видеоконвертерах
Итак, мы выяснили, что для реализации GPGPU на графических процессорах NVIDIA предназначена технология CUDA, а на графических процессорах AMD - API APP. Как уже отмечалось, использование неграфических вычислений на GPU целесообразно только в том случае, если решаемая задача может быть распараллелена на множество потоков. Однако большинство пользовательских приложений не удовлетворяют этому критерию. Впрочем, есть и некоторые исключения. К примеру, большинство современных видеоконвертеров поддерживают возможность использования вычислений на графических процессорах NVIDIA и AMD.
Для того чтобы выяснить, насколько эффективно используются вычисления на GPU в пользовательских видеоконвертерах, мы отобрали три популярных решения: Xilisoft Video Converter Ultimate 7.7.2, Wondershare Video Converter Ultimate 6.0.3.2 и Movavi Video Converter 10.2.1. Эти конвертеры поддерживают возможность использования графических процессоров NVIDIA и AMD, причем в настройках видеоконвертеров можно отключить эту возможность, что позволяет оценить эффективность применения GPU.
Для видеоконвертирования мы применяли три различных видеоролика.
Первый видеоролик имел длительность 3 мин 35 с и размер 1,05 Гбайт. Он был записан в формате хранения данных (контейнер) mkv и имел следующие характеристики:
- видео:
- формат - MPEG4 Video (H264),
- разрешение - 1920*um*1080,
- режим битрейта - Variable,
- средний видеобитрейт - 42,1 Мбит/с,
- максимальный видеобитрейт - 59,1 Мбит/с,
- частота кадров - 25 fps;
- аудио:
- формат - MPEG-1 Audio,
- аудиобитрейт - 128 Кбит/с,
- количество каналов - 2,
Второй видеоролик имел длительность 4 мин 25 с и размер 1,98 Гбайт. Он был записан в формате хранения данных (контейнер) MPG и имел следующие характеристики:
- видео:
- формат - MPEG-PS (MPEG2 Video),
- разрешение - 1920*um*1080,
- режим битрейта - Variable.
- средний видеобитрейт - 62,5 Мбит/с,
- максимальный видеобитрейт - 100 Мбит/с,
- частота кадров - 25 fps;
- аудио:
- формат - MPEG-1 Audio,
- аудиобитрейт - 384 Кбит/с,
- количество каналов - 2,
Третий видеоролик имел длительность 3 мин 47 с и размер 197 Мбайт. Он был записан в формате хранения данных (контейнер) MOV и имел следующие характеристики:
- видео:
- формат - MPEG4 Video (H264),
- разрешение - 1920*um*1080,
- режим битрейта - Variable,
- видеобитрейт - 7024 Кбит/с,
- частота кадров - 25 fps;
- аудио:
- формат - AAC,
- аудиобитрейт - 256 Кбит/с,
- количество каналов - 2,
- частота семплирования - 48 кГц.
Все три тестовых видеоролика конвертировались с использованием видеоконвертеров в формат хранения данных MP4 (кодек H.264) для просмотра на планшете iPad 2. Разрешение выходного видеофайла составляло 1280*um*720.
Отметим, что мы не стали использовать абсолютно одинаковые настройки конвертирования во всех трех конвертерах. Именно поэтому по времени конвертирования некорректно сравнивать эффективность самих видеоконвертеров. Так, в видеоконвертере Xilisoft Video Converter Ultimate 7.7.2 для конвертирования применялся пресет iPad 2 - H.264 HD Video. В этом пресете используются следующие настройки кодирования:
- кодек - MPEG4 (H.264);
- разрешение - 1280*um*720;
- частота кадров - 29,97 fps;
- видеобитрейт - 5210 Кбит/с;
- аудиокодек - AAC;
- аудиобитрейт - 128 Кбит/с;
- количество каналов - 2;
- частота семплирования - 48 кГц.
В видеоконвертере Wondershare Video Converter Ultimate 6.0.3.2 использовался пресет iPad 2 cо следующими дополнительными настройками:
- кодек - MPEG4 (H.264);
- разрешение - 1280*um*720;
- частота кадров - 30 fps;
- видеобитрейт - 5000 Кбит/с;
- аудиокодек - AAC;
- аудиобитрейт - 128 Кбит/с;
- количество каналов - 2;
- частота семплирования - 48 кГц.
В конвертере Movavi Video Converter 10.2.1 применялся пресет iPad (1280*um*720, H.264) (*.mp4) со следующими дополнительными настройками:
- видеоформат - H.264;
- разрешение - 1280*um*720;
- частота кадров - 30 fps;
- видеобитрейт - 2500 Кбит/с;
- аудиокодек - AAC;
- аудиобитрейт - 128 Кбит/с;
- количество каналов - 2;
- частота семплирования - 44,1 кГц.
Конвертирование каждого исходного видеоролика проводилось по пять раз на каждом из видеоконвертеров, причем с использованием как графического процессора, так и только CPU. После каждого конвертирования компьютер перезагружался.
В итоге, каждый видеоролик конвертировался десять раз в каждом видеоконвертере. Для автоматизации этой рутинной работы была написана специальная утилита с графическим интерфейсом, позволяющая полностью автоматизировать процесс тестирования.
Конфигурация стенда для тестирования
Стенд для тестирования имел следующую конфигурацию:
- процессор - Intel Core i7-3770K;
- материнская плата - Gigabyte GA-Z77X-UD5H;
- чипсет системной платы - Intel Z77 Express;
- память - DDR3-1600;
- объем памяти - 8 Гбайт (два модуля GEIL по 4 Гбайт);
- режим работы памяти - двухканальный;
- видеокарта - NVIDIA GeForce GTX 660Ti (видеодрайвер 314.07);
- накопитель - Intel SSD 520 (240 Гбайт).
На стенде устанавливалась операционная система Windows 7 Ultimate (64-bit).
Первоначально мы провели тестирование в штатном режиме работы процессора и всех остальных компонентов системы. При этом процессор Intel Core i7-3770K работал на штатной частоте 3,5 ГГц c активированным режимом Turbo Boost (максимальная частота процессора в режиме Turbo Boost составляет 3,9 ГГц).
Затем мы повторили процесс тестирования, но при разгоне процессора до фиксированной частоты 4,5 ГГц (без использования режима Turbo Boost). Это позволило выявить зависимость скорости конвертирования от частоты процессора (CPU).
На следующем этапе тестирования мы вернулись к штатным настройкам процессора и повторили тестирование уже с другими видеокартами:
- NVIDIA GeForce GTX 280 (драйвер 314.07);
- NVIDIA GeForce GTX 460 (драйвер 314.07);
- AMD Radeon HD6850 (драйвер 13.1).
Таким образом, видеоконвертирование проводилось на четырех видеокартах различной архитектуры.
Старшая видеокарта NVIDIA GeForce 660Ti основана на одноименном графическом процессоре с кодовым обозначением GK104 (архитектура Kepler), производимом по 28-нм техпроцессу. Этот графический процессор содержит 3,54 млрд транзисторов, а площадь кристалла составляет 294 мм2.
Напомним, что графический процессор GK104 включает четыре кластера графической обработки (Graphics Processing Clusters, GPC). Кластеры GPC являются независимыми устройствами в составе процессора и способны работать как отдельные устройства, поскольку обладают всеми необходимыми ресурсами: растеризаторами, геометрическими движками и текстурными модулями.
Каждый такой кластер имеет два потоковых мультипроцессора SMX (Streaming Multiprocessor), но в процессоре GK104 в одном из кластеров один мультипроцессор заблокирован, поэтому всего имеется семь мультипроцессоров SMX.
Каждый потоковый мультипроцессор SMX содержит 192 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 1344 вычислительных ядра CUDA. Кроме того, каждый SMX-мультипроцессор содержит 16 текстурных модулей (TMU), 32 блока специальных функций (Special Function Units, SFU), 32 блока загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Видеокарта GeForce GTX 460 основана на графическом процессоре с кодовым обозначением GF104 на базе архитектуры Fermi. Этот процессор производится по 40-нм техпроцессу и содержит порядка 1,95 млрд транзисторов.
Графический процессор GF104 включает два кластера графической обработки GPC. Каждый из них имеет четыре потоковых мультипроцессора SM, но в процессоре GF104 в одном из кластеров один мультипроцессор заблокирован, поэтому существует всего семь мультипроцессоров SM.
Каждый потоковый мультипроцессор SM содержит 48 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 336 вычислительных ядра CUDA. Кроме того, каждый SM-мультипроцессор содержит восемь текстурных модулей (TMU), восемь блоков специальных функций (Special Function Units, SFU), 16 блоков загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Графический процессор GeForce GTX 280 относится ко второму поколению унифицированной архитектуры графических процессоров NVIDIA и по своей архитектуре сильно отличается от архитектуры Fermi и Kepler.
Графический процессор GeForce GTX 280 состоит из кластеров обработки текстур (Texture Processing Clusters, TPC), которые, хоть и похожи, но в то же время сильно отличаются от кластеров графической обработки GPC в архитектурах Fermi и Kepler. Всего таких кластеров в процессоре GeForce GTX 280 насчитывается десять. Каждый TPC-кластер включает три потоковых мультипроцессора SM и восемь блоков текстурной выборки и фильтрации (TMU). Каждый мультипроцессор состоит из восьми потоковых процессоров (SP). Мультипроцессоры также содержат блоки выборки и фильтрации текстурных данных, используемых как в графических, так и в некоторых расчетных задачах.
Таким образом, в одном TPC-кластере - 24 потоковых процессора, а в графическом процессоре GeForce GTX 280 их уже 240.
Сводные характеристики используемых в тестировании видеокарт на графических процессорах NVIDIA представлены в таблице .
В приведенной таблице нет видеокарты AMD Radeon HD6850, что вполне естественно, поскольку по техническим характеристикам ее трудно сравнивать с видеокартами NVIDIA. А потому рассмотрим ее отдельно.
Графический процессор AMD Radeon HD6850, имеющий кодовое наименование Barts, изготовляется по 40-нм техпроцессу и содержит 1,7 млрд транзисторов.
Архитектура процессора AMD Radeon HD6850 представляет собой унифицированную архитектуру с массивом общих процессоров для потоковой обработки многочисленных видов данных.
Процессор AMD Radeon HD6850 состоит из 12 SIMD-ядер, каждое из которых содержит по 16 блоков суперскалярных потоковых процессоров и четыре текстурных блока. Каждый суперскалярный потоковый процессор содержит пять универсальных потоковых процессоров. Таким образом, всего в графическом процессоре AMD Radeon HD6850 насчитывается 12*um*16*um*5=960 универсальных потоковых процессоров.
Частота графического процессора видеокарты AMD Radeon HD6850 составляет 775 МГц, а эффективная частота памяти GDDR5 - 4000 МГц. При этом объем памяти составляет 1024 Мбайт.
Результаты тестирования
Итак, давайте обратимся к результатам тестирования. Начнем с первого теста, когда используется видеокарта NVIDIA GeForce GTX 660Ti и штатный режим работы процессора Intel Core i7-3770K.
На рис. 1-3 показаны результаты конвертирования трех тестовых видеороликов тремя конвертерами в режимах с применением графического процессора и без.
Как видно по результатам тестирования, эффект от использования графического процессора налицо. Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 в случае применения графического процессора время конвертирования сокращается на 14, 9 и 19% для первого, второго и третьего видеоролика соответственно.
Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 использование графического процессора позволяет сократить время конвертирования на 10, 13 и 23% для первого, второго и третьего видеоролика соответственно.
Но более всех от применения графического процессора выигрывает конвертер Movavi Video Converter 10.2.1. Для первого, второго и третьего видеоролика сокращение времени конвертирования составляет 64, 81 и 41% соответственно.
Понятно, что выигрыш от использования графического процессора зависит и от исходного видеоролика, и от настроек видеоконвертирования, что, собственно, и демонстрируют полученные нами результаты.
Теперь посмотрим, каков будет выигрыш по времени конвертирования при разгоне процессора Intel Core i7-3770K до частоты 4,5 ГГц. Если считать, что в штатном режиме все ядра процессора при конвертировании загружены и в режиме Turbo Boost работают на частоте 3,7 ГГц, то увеличение частоты до 4,5 ГГц соответствует разгону по частоте на 22%.
На рис. 4-6 показаны результаты конвертирования трех тестовых видеороликов при разгоне процессора в режимах с использованием графического процессора и без. В данном случае применение графического процессора позволяет получить выигрыш по времени конвертирования.
Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 в случае применения графического процессора время конвертирования сокращается на 15, 9 и 20% для первого, второго и третьего видеоролика соответственно.
Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 использование графического процессора позволяет сократить время конвертирования на 10, 10 и 20% для первого, второго и третьего видеоролика соответственно.
Для конвертера Movavi Video Converter 10.2.1 применение графического процессора позволяет сократить время конвертирования на 59, 81 и 40% соответственно.
Естественно, интересно посмотреть, как разгон процессора позволяет уменьшить время конвертирования при использовании графического процессора и без него.
На рис. 7-9 представлены результаты сравнения времени конвертирования видеороликов без использования графического процессора в штатном режиме работы процессора и в режиме разгона. Поскольку в данном случае конвертирование проводится только средствами CPU без вычислений на GPU, очевидно, что увеличение тактовой частоты работы процессора приводит к сокращению времени конвертирования (увеличению скорости конвертирования). Столь же очевидно, что сокращение скорости конвертирования должно быть примерно одинаково для всех тестовых видеороликов. Так, для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 при разгоне процессора время конвертирования сокращается на 9, 11 и 9% для первого, второго и третьего видеоролика соответственно. Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 время конвертирования сокращается на 9, 9 и 10% для первого, второго и третьего видеоролика соответственно. Ну а для видеоконвертера Movavi Video Converter 10.2.1 время конвертирования сокращается на 13, 12 и 12% соответственно.
Таким образом, при разгоне процессора по частоте на 20% время конвертирования сокращается примерно на 10%.
Сравним время конвертирования видеороликов с использованием графического процессора в штатном режиме работы процессора и в режиме разгона (рис. 10-12).
Для видеоконвертера Xilisoft Video Converter Ultimate 7.7.2 при разгоне процессора время конвертирования сокращается на 10, 10 и 9% для первого, второго и третьего видеоролика соответственно. Для видеоконвертера Wondershare Video Converter Ultimate 6.0.32 время конвертирования сокращается на 9, 6 и 5% для первого, второго и третьего видеоролика соответственно. Ну а для видеоконвертера Movavi Video Converter 10.2.1 время конвертирования сокращается на 0,2, 10 и 10% соответственно.
Как видим, для конвертеров Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 сокращение времени конвертирования при разгоне процессора примерно одинаково как при использовании графического процессора, так и без его применения, что логично, поскольку эти конвертеры не очень эффективно используют вычисления на GPU. А вот для конвертера Movavi Video Converter 10.2.1, который эффективно использует вычисления на GPU, разгон процессора в режиме использования вычислений на GPU мало сказывается на сокращении времени конвертирования, что также понятно, поскольку в данном случае основная нагрузка ложится на графический процессор.
Теперь посмотрим результаты тестирования с различными видеокартами.
Казалось бы, чем мощнее видеокарта и чем больше в графическом процессоре ядер CUDA (или универсальных потоковых процессоров для видеокарт AMD), тем эффективнее должно быть видеоконвертирование в случае применения графического процессора. Но на практике получается не совсем так.
Что касается видеокарт на графических процессорах NVIDIA, то ситуация следующая. При использовании конвертеров Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 время конвертирования практически никак не зависит от типа используемой видеокарты. То есть для видеокарт NVIDIA GeForce GTX 660Ti, NVIDIA GeForce GTX 460 и NVIDIA GeForce GTX 280 в режиме использования вычислений на GPU время конвертирования получается одно и то же (рис. 13-15).
|
|
Рис. 1. Результаты конвертирования первого |
процессора видеокартах в режиме использования графического процессора |
|
|
Рис. 14. Результаты сравнения времени конвертирования второго видеоролика |
|
|
|
Рис. 15. Результаты сравнения времени конвертирования третьего видеоролика |
|



Объяснить это можно лишь тем, что алгоритм вычислений на графическом процессоре, реализованный в конвертерах Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32, просто неэффективен и не позволяет активно задействовать все графические ядра. Кстати, именно этим объясняется и тот факт, что для этих конвертеров разница по времени конвертирования в режимах использования GPU и без использования невелика.
В конвертере Movavi Video Converter 10.2.1 ситуация несколько иная. Как мы помним, этот конвертер способен очень эффективно использовать вычисления на GPU, а поэтому в режиме использования GPU время конвертирования зависит от типа используемой видеокарты.
А вот с видеокартой AMD Radeon HD 6850 всё как обычно. То ли драйвер видеокарты «кривой», то ли алгоритмы, реализованные в конвертерах, нуждаются в серьезной доработке, но в случае применения вычислений на GPU результаты либо не улучшаются, либо ухудшаются.
Если говорить более конкретно, то ситуация следующая. Для конвертера Xilisoft Video Converter Ultimate 7.7.2 при использовании графического процессора для конвертирования первого тестового видеоролика время конвертирования увеличивается на 43%, при конвертировании второго ролика - на 66%.
Причем, конвертер Xilisoft Video Converter Ultimate 7.7.2 характеризуется еще и нестабильностью результатов. Разброс по времени конвертирования может достигать 40%! Именно поэтому мы повторяли все тесты по десять раз и рассчитывали средний результат.
А вот для конвертеров Wondershare Video Converter Ultimate 6.0.32 и Movavi Video Converter 10.2.1 при использовании графического процессора для конвертирования всех трех видеороликов время конвертирования не изменяется вообще! Вероятно, что конвертеры Wondershare Video Converter Ultimate 6.0.32 и Movavi Video Converter 10.2.1 либо не используют технологию AMD APP при конвертировании, либо видеодрайвер AMD попросту «кривой», в результате чего технология AMD APP не работает.
Выводы
На основании проведенного тестирования можно сделать следующие важные выводы. В современных видеоконвертерах действительно может применяться технология вычислений на GPU, что позволяет повысить скорость конвертирования. Однако это вовсе не означает, что все вычисления целиком переносятся на GPU и CPU остается незадействованным. Как показывает тестирование, при использовании технологии GPGPU центральный процессор остается загруженным, а значит, применение мощных, многоядерных центральных процессоров в системах, используемых для конвертирования видео, остается актуальным. Исключением из этого правила является технология AMD APP на графических процессорах AMD. Например, при использовании конвертера Xilisoft Video Converter Ultimate 7.7.2 с активированной технологией AMD APP нагрузка на CPU действительно снижается, но это приводит к тому, что время конвертирования не сокращается, а, наоборот, увеличивается.
Вообще, если говорить о конвертировании видео с дополнительным использованием графического процессора, то для решения этой задачи целесообразно применять видеокарты с графическими процессорами NVIDIA. Как показывает практика, только в этом случае можно добиться увеличения скорости конвертирования. Причем нужно помнить, что реальный прирост в скорости конвертирования зависит от очень многих факторов. Это входной и выходной форматы видео, и, конечно же, сам видеоконвертер. Конвертеры Xilisoft Video Converter Ultimate 7.7.2 и Wondershare Video Converter Ultimate 6.0.32 для этой задачи подходят плохо, а вот конвертер и Movavi Video Converter 10.2.1 способен очень эффективно использовать возможности NVIDIA GPU.
Что же касается видеокарт на графических процессорах AMD, то для задач видеоконвертирования их не стоит применять вообще. В лучшем случае никакого прироста в скорости конвертирования это не даст, а в худшем - можно получить ее снижение.
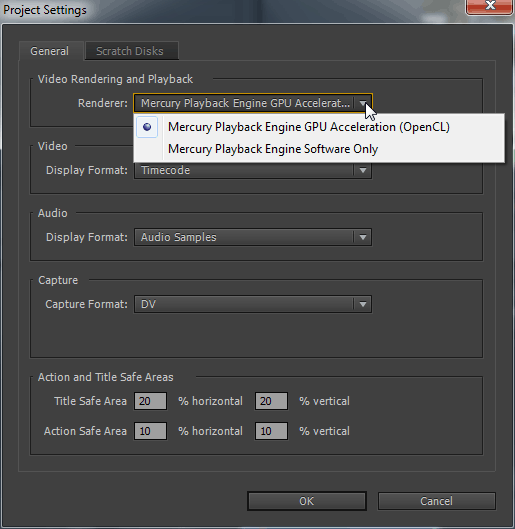
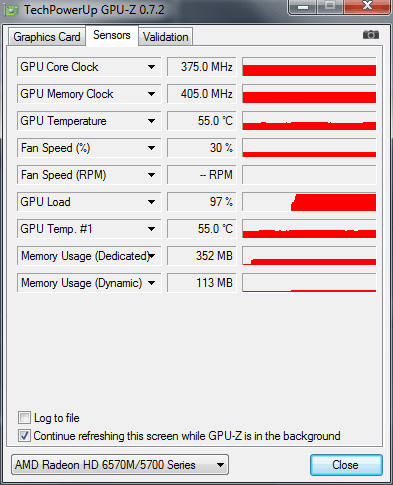
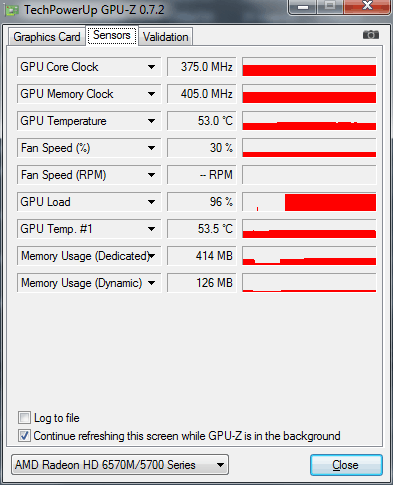
Часто стал появляться вопрос: почему нет GPU ускорения в программе Adobe Media Encoder CC? А то что Adobe Media Encoder использует GPU ускорение, мы выяснили , а также отметили нюансы его использования . Также встречается утверждение: что в программе Adobe Media Encoder CC убрали поддержку GPU ускорения. Это ошибочное мнение и вытекает из того, что основная программа Adobe Premiere Pro CC теперь может работать без прописанной и рекомендованной видеокарты, а для включения GPU движка в Adobe Media Encoder CC, видеокарта должна быть обязательно прописана в документах: cuda_supported_cards или opencl_supported_cards. Если с чипсетами nVidia все понятно, просто берем имя чипсета и вписываем его в документ cuda_supported_cards. То при использовании видеокарт AMD прописывать надо не имя чипсета, а кодовое название ядра. Итак, давайте на практике проверим, как на ноутбуке ASUS N71JQ с дискретной графикой ATI Mobility Radeon HD 5730 включить GPU движок в Adobe Media Encoder CC. Технические данные графического адаптера ATI Mobility Radeon HD 5730 показываемые утилитой GPU-Z:
Запускаем программу Adobe Premiere Pro CC и включаем движок: Mercury Playback Engine GPU Acceleration (OpenCL).
Три DSLR видео на таймлайне, друг над другом, два из них, создают эффект картинка в картинке.

Ctrl+M, выбираем пресет Mpeg2-DVD, убираем черные полосы по бокам с помощью опции Scale To Fill. Включаем также повышеное качество для тестов без GPU: MRQ (Use Maximum Render Quality). Нажимаем на кнопку: Export. Загрузка процессора до 20% и оперативной памяти 2.56 Гбайт.

Загрузка GPU чипсета ATI Mobility Radeon HD 5730 составляет 97% и 352Мб бортовой видеопамяти. Ноутбук тестировался при работе от аккумулятора, поэтому графическое ядро / память работают на пониженных частотах: 375 / 810 МГц.
Итоговое время просчета: 1 минута и 55 секунд
(вкл/откл. MRQ при использовании GPU движка, не влияет на итогове время просчета).
При установленной галке Use Maximum Render Quality теперь нажимаем на кнопку: Queue.

Тактовые частоты процессора при работе от аккумулятора: 930МГц.


Запускаем AMEEncodingLog и смотрим итоговое время просчета: 5 минут и 14 секунд .

Повторяем тест, но уже при снятой галке Use Maximum Render Quality, нажимаем на кнопку: Queue.

Итоговое время просчета: 1 минута и 17 секунд .

Теперь включим GPU движок в Adobe Media Encoder CC, запускаем программу Adobe Premiere Pro CC, нажимаем комбинацию клавиш: Ctrl + F12, выполняем Console > Console View и в поле Command вбиваем GPUSniffer, нажимаем Enter.
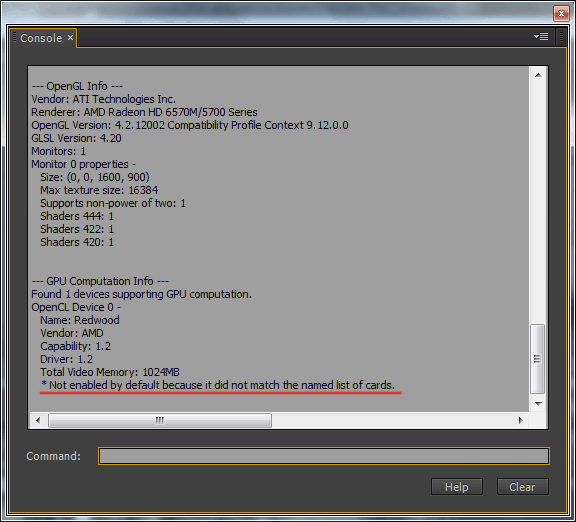
Выделяем и копируем имя в GPU Computation Info.
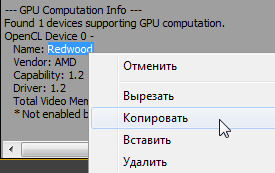
В директории программы Adobe Premiere Pro CC открываем документ opencl_supported_cards, и в алфавитном порядке вбиваем кодовое имя чипсета, Ctrl+S.

Нажимаем на кнопку: Queue, и получаем GPU ускорение просчета проекта Adobe Premiere Pro CC в Adobe Media Encoder CC.
Итоговое время: 1 минута и 55 секунд .

Подключаем ноутбук к розетке, и повторяем результаты просчетов. Queue, галка MRQ снята, без включения движка, загрузка оперативной памяти немного подросла:

Тактовые частоты процессора: 1.6ГГц при работе от розетки и включении режима: Высокая производительность.

Итоговое время: 46 секунд .

Включаем движок: Mercury Playback Engine GPU Acceleration (OpenCL), как видно от сети ноутбучная видеокарта работает на своих базовых частотах, загрузка GPU в Adobe Media Encoder CC достигает 95%.

Итоговое время просчета, снизилось с 1 минуты 55 секунд , до 1 минуты и 5 секунд .

*Для визуализации в Adobe Media Encoder CC теперь используется графический процессор (GPU). Поддерживаются стандарты CUDA и
OpenCL. В Adobe Media Encoder CC, движок GPU используется для следующих процессов визуализации:
- Изменение четкости (от высокой к стандартной и наоборот).
- Фильтр временного кода.
- Преобразования формата пикселей.
- Расперемежение.
Если визуализируется проект Premiere Pro, в AME используются установки визуализации с GPU, заданные для этого проекта. При этом будут использованы все возможности визуализации с GPU, реализованные в Premiere Pro. Для визуализации проектов AME используется ограниченный набор возможностей визуализации с GPU.
Если последовательность визуализируется с использованием оригинальной поддержки, применяется настройка GPU из AME, настройка проекта игнорируется. В этом случае все возможности визуализации с GPU Premiere Pro используются напрямую в AME.
Если проект содержит VST сторонних производителей, используется настройка GPU проекта. Последовательность кодируется с помощью PProHeadless, как и в более ранних версиях AME. Если флажок Enable Native Premiere Pro Sequence Import (Разрешить импорт исходной последовательности Premiere Pro) снят, всегда используется PProHeadless и настройка GPU.
Читаем про скрытый раздел на системном диске ноутбука ASUS N71JQ.