Max degree of parallelism (DOP) - дополнительна опция конфигурации SQL Server, с
которой связано много вопросов и которой посвящено множество публикаций. В этой
статье своего блога, автор надеется внести немного ясности в то, что эта опция
делает и как её нужно использовать.
Во-первых, автор хотел бы рассеять любые сомнения по поводу того, что указанная
опция устанавливает, сколько процессоров может использовать SQL Server при
обслуживании нескольких подключений (или пользователей) - это не так! Если SQL
Server имеет доступ к четырем неактивным процессорам, и он настроен на использование
всех четырёх процессоров, он будет использовать все четыре процессора, независимо
от максимальной степени параллелизма.
Так, что же эта опция даёт? Эта опция устанавливает максимальное число процессоров,
которые SQL Server может использовать для одного запроса. Если запрос к SQL Server
должен вернуть большой объём данных (много записей), его иногда имеет смысл
распараллелить, разбив на несколько маленьких запросов, каждый из которых будет
возвращать своё подмножество строк. Таким образом, SQL Server может использовать
несколько процессоров, и, следовательно, на многопроцессорных системах большое
количество записей всего запроса потенциально может быть возвращено быстрее, чем
на однопроцессорной системе.
Есть множество критериев, которые должны быть учтены до того, как SQL Server вызовет
"Intra Query Parallelism" (разбивку запроса на несколько потоков), и
нет смысла их здесь детализировать. Вы можете найти их в BOL, поискав фразу
"Degree of parallelism". Там написано, что решение о распараллеливании основано
на доступности памяти процессору и, особенно, на доступности самих процессоров.
Итак, почему мы должны продумать использование этой опции - потому что, оставляя
её в значении по умолчанию (SQL Server сам принимает решение о распараллеливании),
иногда можно получить нежелательные эффекты. Эти эффекты выглядят примерно так:
Распараллеленные запросы выполняются медленнее.
Время исполнения запросов может стать недетерминированным, и это может раздражить пользователей. Время исполнения может измениться потому что:
Запрос может иногда распараллеливаться, а иногда нет.
Запрос может блокироваться параллельным запросом, если перед этим процессоры были перегружены работой.
Прежде, чем мы продолжим, автор хотел бы заметить, что нет особой необходимости погружаться во внутреннюю организацию параллелизма. Если же Вы этим интересуетесь, Вы можете почитать статью "Parallel Query Processing" в Books on Line, в которой эта информация изложена более детально. Автор считает, что есть только две важные вещи, которые стоит знать о внутренней организации параллелизма:
Параллельные запросы могут породить больше потоков, чем указано в опции "Max degree of parallelism". DOP 4 может породить более двенадцати потоков, четыре для запроса и дополнительные потоки, используемые для сортировок, потоков, агрегатов и сборок и т.д.
Распараллеливание запросов может провоцировать разные SPID ожидать с типом ожидания CXPACKET или 0X0200. Этим можно воспользоваться для того, что бы найти те SPID, которые находятся в состоянии ожидания при параллельных операциях, и имеют в sysprocesses waittype: CXPACKET. Для облегчения этой задачи, автор предлагает воспользоваться имеющейся в его блоге хранимой процедурой: track_waitstats.
И так "Запрос может выполняться медленнее при распараллеливании" почему?
Если у системы очень слабая пропускная способность дисковых подсистем, тогда при анализе запроса, его декомпозиция может выполняться дольше, чем без параллелизма.
Возможен перекос данных или блокировки диапазонов данных для процессора, порождённые другим, используемым параллельно и запущенным позже процессом, и т.д.
Если отсутствует индекс для предиката, что приводит к сканированию таблицы. Параллельная операция в рамках запроса может скрыть тот факт, что запрос выполнился бы намного быстрее с последовательным планом исполнения и с правильным индексом.
Из всего этого следует рекомендация проверять исполнение запроса без параллелизма
(DOP=1), это поможет идентифицировать возможные проблемы.
Упомянутые выше эффекты параллелизма, сами собой должны навести Вас на мысль о
том, что внутренняя механика распараллеливания запросов не подходит для применения
в OLTP - приложениях. Это такие приложения, для которых изменение времени исполнения
запроса может раздражать пользователей и для которых сервер, одновременно обслуживающий
множество пользователей, вряд ли выберет параллельный план исполнения из-за присущих
этим приложениям особенностей профиля рабочей нагрузки процессора.
Поэтому, если Вы собираетесь использовать параллелизм, то, скорее всего это
понадобится, для задач извлечения данных (data warehouse), поддержки принятия
решений или отчётных систем, где не много запросов, но они являются достаточно
тяжёлыми и исполняются на мощном сервере с большим объёмом оперативной памяти.
Если Вы решили использовать параллелизм, какое же значение нужно установить для DOP?.
Хорошей практикой для этого механизма является то, что если Вы имеете 8 процессоров,
тогда устанавливайте DOP = 4, и это с большой степенью вероятности будет оптимальной
установкой. Однако, нет никаких гарантий, что так оно и будет работать. Единственный
способ убедиться в этом - протестировать разные значения для DOP. В дополнение к этому,
автор хотел предложить свой, основанный на эмпирических наблюдениях совет, никогда
не устанавливать это число больше, чем половине от числа процессоров, которые есть
в наличии. Если бы автор имел процессоров меньше шести, он установил бы DOP в 1,
что просто запрещает распараллеливание. Он мог бы сделать исключение, если бы имел
базу данных, которая поддерживает процесс только одного пользователя (некоторые
технологии извлечения данных или задачи отчётности), в этом случае, в порядке
исключения, можно будет установить DOP в 0 (значение по умолчанию), которое
позволяет SQL Server самому принимать решение о необходимости распараллеливания запроса.
Прежде, чем закончить статью, автор хотел предостеречь Вас по поводу того, что
параллельное создание индексов зависит от числа, которое Вы устанавливаете для DOP.
Это означает, что Вы можете захотеть изменять его на время создания или пересоздания
индексов, чтобы повысить производительность этой операции, и, конечно же, Вы можете
использовать в запросе хинт MAXDOP, который позволяет игнорировать установленное
в конфигурации значение и может быть использован в часы минимальной нагрузки.
Наконец, ваш запрос может замедляться при распараллеливании из-за ошибок, поэтому
убедитесь, что на вашем сервере установлен последний сервисный пакет (service pack).
| CREATE proc track_waitstats (@num_samples int =10 ,@delaynum int =1 ,@delaytype nvarchar (10 )="minutes" ) AS -- T. Davidson -- This stored procedure is provided =AS IS= with no warranties, -- and confers no rights. -- Use of included script samples are subject to the terms -- specified at http://www.microsoft.com/info/cpyright.htm -- @num_samples is the number of times to capture waitstats, -- default is 10 times. default delay interval is 1 minute -- delaynum is the delay interval. delaytype specifies whether -- the delay interval is minutes or seconds -- create waitstats table if it does not exist, otherwise truncate set nocount on if not exists (select 1 from sysobjects where name = "waitstats" ) create table waitstats ( varchar (80 ), requests numeric (20 ,1 ), numeric (20 ,1 ), numeric (20 ,1 ), now datetime default getdate ()) else truncate table waitstats dbcc sqlperf (waitstats,clear) -- clear out waitstats declare @i int ,@delay varchar (8 ) ,@dt varchar (3 ) ,@now datetime ,@totalwait numeric (20 ,1 ) ,@endtime datetime ,@begintime datetime ,@hr int ,@min int ,@sec int select @i = 1 select @dt = case lower (@delaytype) when "minutes" then "m" when "minute" then "m" when "min" then "m" when "mm" then "m" when "mi" then "m" when "m" then "m" when "seconds" then "s" when "second" then "s" when "sec" then "s" when "ss" then "s" when "s" then "s" else @delaytype end if @dt not in ("s" ,"m" ) begin print "please supply delay type e.g. seconds or minutes" return end if @dt = "s" begin select @sec = @delaynum % 60 select @min = cast ((@delaynum / 60 ) as int ) select @hr = cast ((@min / 60 ) as int ) select @min = @min % 60 end if @dt = "m" begin select @sec = 0 select @min = @delaynum % 60 select @hr = cast ((@delaynum / 60 ) as int ) end select @delay = right ("0" + convert (varchar (2 ),@hr),2 2 ),@min),2 ) + ":" + + right ("0" +convert (varchar (2 ),@sec),2 ) if @hr > 23 or @min > 59 or @sec > 59 begin select "hh:mm:ss delay time cannot > 23:59:59" select "delay interval and type: " + convert (varchar (10 ) ,@delaynum) + "," + @delaytype + " converts to " + @delay return end while (@i <= @num_samples) begin insert into waitstats (, requests, ,) exec ("dbcc sqlperf(waitstats)" ) select @i = @i + 1 waitfor delay @delay End --- create waitstats report execute get_waitstats --//--//--//--//--//--//--//--//--//-//--//--//--//--//--//--//--//--/ CREATE proc get_waitstats AS -- This stored procedure is provided =AS IS= with no warranties, and -- confers no rights. -- Use of included script samples are subject to the terms specified -- at http://www.microsoft.com/info/cpyright.htm -- -- this proc will create waitstats report listing wait types by -- percentage -- can be run when track_waitstats is executing set nocount on declare @now datetime ,@totalwait numeric (20 ,1 ) ,@endtime datetime ,@begintime datetime ,@hr int ,@min int ,@sec int select @now=max (now),@begintime=min (now),@endtime=max (now) from waitstats where = "Total" --- subtract waitfor, sleep, and resource_queue from Total select @totalwait = sum () + 1 from waitstats where not in ("WAITFOR" ,"SLEEP" ,"RESOURCE_QUEUE" , "Total" , "***total***" ) and now = @now -- insert adjusted totals, rank by percentage descending delete waitstats where = "***total***" and now = @now insert into waitstats select "***total***" ,0 ,@totalwait ,@totalwait ,@now select , ,percentage = cast (100 */@totalwait as numeric (20 ,1 )) from waitstats where not in ("WAITFOR" ,"SLEEP" ,"RESOURCE_QUEUE" ,"Total" ) and now = @now order by percentage desc |
Max degree of parallelism (DOP) - дополнительна опция конфигурации SQL Server, с которой связано много вопросов и которой посвящено множество публикаций. В этой статье своего блога, автор надеется внести немного ясности в то, что эта опция делает и как её нужно использовать.
Во-первых, автор хотел бы рассеять любые сомнения по поводу того, что указанная опция устанавливает, сколько процессоров может использовать SQL Server при обслуживании нескольких подключений (или пользователей) - это не так! Если SQL Server имеет доступ к четырем неактивным процессорам, и он настроен на использование всех четырёх процессоров, он будет использовать все четыре процессора, независимо от максимальной степени параллелизма.
Так, что же эта опция даёт? Эта опция устанавливает максимальное число процессоров, которые SQL Server может использовать для одного запроса. Если запрос к SQL Server должен вернуть большой объём данных (много записей), его иногда имеет смысл распараллелить, разбив на несколько маленьких запросов, каждый из которых будет возвращать своё подмножество строк. Таким образом, SQL Server может использовать несколько процессоров, и, следовательно, на многопроцессорных системах большое количество записей всего запроса потенциально может быть возвращено быстрее, чем на однопроцессорной системе.
Есть множество критериев, которые должны быть учтены до того, как SQL Server вызовет "Intra Query Parallelism" (разбивку запроса на несколько потоков), и нет смысла их здесь детализировать. Вы можете найти их в BOL, поискав фразу "Degree of parallelism". Там написано, что решение о распараллеливании основано на доступности памяти процессору и, особенно, на доступности самих процессоров.
Итак, почему мы должны продумать использование этой опции - потому что, оставляя её в значении по умолчанию (SQL Server сам принимает решение о распараллеливании), иногда можно получить нежелательные эффекты. Эти эффекты выглядят примерно так:
- Распараллеленные запросы выполняются медленнее.
- Время исполнения запросов может стать недетерминированным, и это может раздражить пользователей. Время исполнения может измениться потому что:
- Запрос может иногда распараллеливаться, а иногда нет.
- Запрос может блокироваться параллельным запросом, если перед этим процессоры были перегружены работой.
Прежде, чем мы продолжим, автор хотел бы заметить, что нет особой необходимости погружаться во внутреннюю организацию параллелизма. Если же Вы этим интересуетесь, Вы можете почитать статью "Parallel Query Processing" в Books on Line, в которой эта информация изложена более детально. Автор считает, что есть только две важные вещи, которые стоит знать о внутренней организации параллелизма:
- Параллельные запросы могут породить больше потоков, чем указано в опции "Max degree of parallelism". DOP 4 может породить более двенадцати потоков, четыре для запроса и дополнительные потоки, используемые для сортировок, потоков, агрегатов и сборок и т.д.
- Распараллеливание запросов может провоцировать разные SPID ожидать с типом ожидания CXPACKET или 0X0200. Этим можно воспользоваться для того, что бы найти те SPID, которые находятся в состоянии ожидания при параллельных операциях, и имеют в sysprocesses waittype: CXPACKET. Для облегчения этой задачи, автор предлагает воспользоваться имеющейся в его блоге хранимой процедурой: track_waitstats.
И так "Запрос может выполняться медленнее при распараллеливании" почему?
- Если у системы очень слабая пропускная способность дисковых подсистем, тогда при анализе запроса, его декомпозиция может выполняться дольше, чем без параллелизма.
- Возможен перекос данных или блокировки диапазонов данных для процессора, порождённые другим, используемым параллельно и запущенным позже процессом, и т.д.
- Если отсутствует индекс для предиката, что приводит к сканированию таблицы. Параллельная операция в рамках запроса может скрыть тот факт, что запрос выполнился бы намного быстрее с последовательным планом исполнения и с правильным индексом.
Упомянутые выше эффекты параллелизма, сами собой должны навести Вас на мысль о том, что внутренняя механика распараллеливания запросов не подходит для применения в OLTP - приложениях. Это такие приложения, для которых изменение времени исполнения запроса может раздражать пользователей и для которых сервер, одновременно обслуживающий множество пользователей, вряд ли выберет параллельный план исполнения из-за присущих этим приложениям особенностей профиля рабочей нагрузки процессора.
Поэтому, если Вы собираетесь использовать параллелизм, то, скорее всего это понадобится, для задач извлечения данных (data warehouse), поддержки принятия решений или отчётных систем, где не много запросов, но они являются достаточно тяжёлыми и исполняются на мощном сервере с большим объёмом оперативной памяти.
Если Вы решили использовать параллелизм, какое же значение нужно установить для DOP?. Хорошей практикой для этого механизма является то, что если Вы имеете 8 процессоров, тогда устанавливайте DOP = 4, и это с большой степенью вероятности будет оптимальной установкой. Однако, нет никаких гарантий, что так оно и будет работать. Единственный способ убедиться в этом - протестировать разные значения для DOP. В дополнение к этому, автор хотел предложить свой, основанный на эмпирических наблюдениях совет, никогда не устанавливать это число больше, чем половине от числа процессоров, которые есть в наличии. Если бы автор имел процессоров меньше шести, он установил бы DOP в 1, что просто запрещает распараллеливание. Он мог бы сделать исключение, если бы имел базу данных, которая поддерживает процесс только одного пользователя (некоторые технологии извлечения данных или задачи отчётности), в этом случае, в порядке исключения, можно будет установить DOP в 0 (значение по умолчанию), которое позволяет SQL Server самому принимать решение о необходимости распараллеливания запроса.
Прежде, чем закончить статью, автор хотел предостеречь Вас по поводу того, что параллельное создание индексов зависит от числа, которое Вы устанавливаете для DOP. Это означает, что Вы можете захотеть изменять его на время создания или пересоздания индексов, чтобы повысить производительность этой операции, и, конечно же, Вы можете использовать в запросе хинт MAXDOP, который позволяет игнорировать установленное в конфигурации значение и может быть использован в часы минимальной нагрузки.
Наконец, ваш запрос может замедляться при распараллеливании из-за ошибок, поэтому убедитесь, что на вашем сервере установлен последний сервисный пакет (service pack).
REATE proc track_waitstats@num_samples int =10
,@delaynum int =1
,@delaytype nvarchar (10 )="minutes"
AS
-- T. Davidson
-- This stored procedure is provided =AS IS= with no warranties,
-- and confers no rights.
-- Use of included script samples are subject to the terms
-- specified at http://www.microsoft.com/info/cpyright.htm
-- @num_samples is the number of times to capture waitstats,
-- default is 10 times. default delay interval is 1 minute
-- delaynum is the delay interval. delaytype specifies whether
-- the delay interval is minutes or seconds
-- create waitstats table if it does not exist, otherwise truncate
set
nocount
on
if
not
exists
(select
1
from
sysobjects
where
name = "waitstats"
)
create
table
waitstats ( varchar
(80
),
requests numeric
(20
,1
),
numeric
(20
,1
),
numeric
(20
,1
),
now datetime
default
getdate
())
else
truncate
table
waitstats
dbcc sqlperf (waitstats,clear) -- clear out waitstats
declare
@i int
,@delay varchar
(8
)
,@dt varchar
(3
)
,@now datetime
,@totalwait numeric
(20
,1
)
,@endtime datetime
,@begintime datetime
,@hr int
,@min int
,@sec int
select
@i = 1
select
@dt = case
lower
(@delaytype)
when
"minutes"
then
"m"
when
"minute"
then
"m"
when
"min"
then
"m"
when
"mm"
then
"m"
when
"mi"
then
"m"
when
"m"
then
"m"
when
"seconds"
then
"s"
when
"second"
then
"s"
when
"sec"
then
"s"
when
"ss"
then
"s"
when
"s"
then
"s"
else
@delaytype
end
if
@dt not
in
("s"
,"m"
)
begin
print
"please supply delay type e.g. seconds or minutes"
return
end
if
@dt = "s"
begin
select
@sec = @delaynum % 60
select
@min = cast
((@delaynum / 60
) as
int
)
select
@hr = cast
((@min / 60
) as
int
)
select
@min = @min % 60
end
if
@dt = "m"
begin
select
@sec = 0
select
@min = @delaynum % 60
select
@hr = cast
((@delaynum / 60
) as
int
)
end
select
@delay = right
("0"
+ convert
(varchar
(2
),@hr),2
) + ":"
+
2
),@min),2
) + ":"
+
+ right
("0"
+convert
(varchar
(2
),@sec),2
)
if
@hr > 23
or
@min > 59
or
@sec > 59
begin
select
"hh:mm:ss delay time cannot > 23:59:59"
select
"delay interval and type: "
+ convert
(varchar
(10
)
,@delaynum) + ","
+ @delaytype + " converts to "
+ @delay
return
end
while
(@i <= @num_samples)
begin
insert
into
waitstats (, requests,
,)
exec
("dbcc sqlperf(waitstats)"
)
select
@i = @i + 1
waitfor
delay
@delay
End
Create waitstats report
execute
get_waitstats
--//--//--//--//--//--//--//--//--//-//--//--//--//--//--//--//--//--/
CREATE
proc
get_waitstats
AS
-- This stored procedure is provided =AS IS= with no warranties, and
-- confers no rights.
-- Use of included script samples are subject to the terms specified
-- at http://www.microsoft.com/info/cpyright.htm
--
-- this proc will create waitstats report listing wait types by
-- percentage
-- can be run when track_waitstats is executing
set nocount on
declare
@now datetime
,@totalwait numeric
(20
,1
)
,@endtime datetime
,@begintime datetime
,@hr int
,@min int
,@sec int
select
@now=max
(now),@begintime=min
(now),@endtime=max
(now)
from
waitstats where
= "Total"
Subtract waitfor, sleep, and resource_queue from Total
select
@totalwait = sum
() + 1
from
waitstats
where
not
in
("WAITFOR"
,"SLEEP"
,"RESOURCE_QUEUE"
, "Total"
, "***total***"
) and
now = @now
Insert adjusted totals, rank by percentage descending
delete waitstats where = "***total***" and now = @now
insert
into
waitstats select
"***total***"
,0
,@totalwait
,@totalwait
,@now
select
,
,percentage = cast
(100
*/@totalwait as
numeric
(20
,1
))
from
waitstats
where
not
in
("WAITFOR"
,"SLEEP"
,"RESOURCE_QUEUE"
,"Total"
)
and
now = @now
order
by
percentage desc
Оптимизация работы 1С. Настройка сервера MS SQL
Включите возможность мгновенной инициализации файлов (Database instant file initialization)
- Создание базы данных
- Добавление файлов, журналов или данных в существующую базу данных
- Увеличение размера существующего файла (включая операции автоувеличения)
- Восстановление базы данных или файловой группы
Для включения настройки:
- На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.msc).
- Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей.
- На правой панели дважды кликните Выполнение задач по обслуживанию томов.
- Нажмите кнопку «Добавить» пользователя или группу и добавьте сюда пользователя, под которым запущен сервер MS SQL Server.
- Нажмите кнопку Применить.
Включите параметр «Блокировка страниц в памяти» (Lock pages in memory)
Эта настройка определяет, какие учетные записи могут сохранять данные в оперативной памяти, чтобы система не отправляла страницы данных в виртуальную память на диске, что может повысить производительность.
Для включения настройки:
- В меню Пуск выберите команду Выполнить. В поле Открыть введите gpedit.msc.
- В консоли Редактор локальных групповых политик разверните узел Конфигурация компьютера, затем узел Конфигурация Windows.
- Разверните узлы Настройки безопасности и Локальные политики.
- Выберите папку Назначение прав пользователя.
- Политики будут показаны на панели подробностей.
- На этой панели дважды кликните параметр Блокировка страниц в памяти.
- В диалоговом окне Параметр локальной безопасности - блокировка страниц в памяти выберите «Добавить» пользователя или группу.
- В диалоговом окне Выбор: пользователи, учетные записи служб или группы добавьте ту учетную запись, под которой у вас запускается служба MS SQL Server.
- Чтобы изменения вступили в силу, перезагрузите сервер или зайдите под тем пользователем, под которым у вас запускается MS SQL Server.
Отключите механизм DFSS для дисков.
Механизм Dynamic Fair Share Scheduling отвечает за балансировку и распределение аппаратных ресурсов между пользователями. Иногда его работа может негативно сказываться на производительности 1С. Чтобы отключить его только для дисков, нужно:
- Найти в реестре ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TSFairShare\Disk
- Установить значение параметра EnableFairShare в 0
Отключите сжатие данных для каталогов, в которых лежат файлы базы.
При включенном сжатии ОС будет пытаться дополнительно обрабатывать файлы при модификации, что замедлит сам процесс записи, но сэкономит место.
Чтобы отключить сжатие файлов в каталоге, необходимо:
- Открыть свойства каталога
- На закладке Общие нажать кнопку Другие
- Снять флаг «Сжимать» содержимое для экономии места на диске.
Установите параметр «Максимальная степень параллелизма» (Max degree of parallelism) в значение 1.
Данный параметр определяет, во сколько потоков может выполняться один запрос. По умолчанию параметр равен 0, это означает, что сервер сам подбирает число потоков. Для баз с характерной для 1С нагрузкой рекомендуется поставить данный параметр в значение 1, т.к. в большинстве случаев это положительно скажется на работе запросов.
Для настройки параметра необходимо:
- Открыть свойства сервера и выбрать закладку Дополнительно
- Установить значение параметра равное единице.
Ограничьте максимальный объем памяти сервера MS SQL Server.
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей. Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства сервера и выбрать закладку Память
- Указать значение параметра Максимальный размер памяти сервера.
Включите флаг «Поддерживать» приоритет SQL Server (Boost SQL Server priority).
Данный флаг позволяет повысить приоритет процесса MS SQL Server над другими процессами.
Имеет смысл включать флаг только в том случае, если на компьютере с сервером СУБД не установлен сервер 1С.
Для установки флага необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства сервера и выбрать закладку Процессоры
- Включить флаг «Поддерживать приоритет SQL Server (Boost SQL Server priority)» и нажать Ок.
Установите размер авто увеличения файлов базы данных.
Автоувеличение позволяет указать величину, на которую будет увеличен размер файла базы данных, когда он будет заполнен. Если поставить слишком маленький размер авторасширения, тогда файл будет слишком часто расширяться, на что будет уходить время. Рекомендуется установить значение от 512 МБ до 5 ГБ.
- Запустить Management Studio и подключиться к нужному серверу
- Напротив каждого файла в колонке Автоувеличение поставить необходимое значение
Данная настройка будет действовать только для выбранной базы. Если вы хотите, чтобы такая настройка действовала для всех баз, нужно выполнить эти же действия для служебной базы model. После этого все вновь созданные базы будет иметь те же настройки, что и база model.
Разнесите файлы данных mdf и файлы логов ldf на разные физические диски.
В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства нужной базы и выбрать закладку Файлы
- Запомнить имена и расположение файлов
- Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
- Поставить флаг Удалить соединения и нажать Ок
- Открыть Проводник и переместить файл данных и файл журнала на нужные носители
- В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
- Нажать кнопку Добавить и указать файл mdf с нового диска
- В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок.
ОБЛАСТЬ ПРИМЕНЕНИЯ ЭТОЙ СТАТЬИ: SQL Server (начиная с 2008)База данных SQL AzureХранилище данных SQL AzureParallel Data Warehouse
В этом разделе описываются способы настройки параметра конфигурации сервера max degree of parallelism (MAXDOP) в SQL Server 2016 с помощью среды SQL Server Management Studio или Transact-SQL. Если экземпляр SQL Server работает на многопроцессорном компьютере, он определяет оптимальную степень параллелизма, то есть количество процессоров, задействованных для выполнения одной инструкции, для каждого из планов параллельного выполнения. Для ограничения количества процессоров в плане параллельного выполнения может быть использован параметр max degree of parallelism . SQL Server учитывает планы параллельного выполнения для запросов, операций DDL с индексами, параллельной вставки, изменения столбца в режиме "в сети", параллельного сбора статистики и заполнения статических курсоров и курсоров, управляемых набором ключей.
Ограничения
- Если параметр affinity mask имеет значение, отличное от значения по умолчанию, он может ограничивать число процессоров, доступных для SQL Server в симметричных многопроцессорных системах (SMP).
Этот параметр является дополнительным и его следует изменять только опытным администраторам баз данных или сертифицированным техническим специалистам SQL Server .
Чтобы разрешить серверу определять максимальную степень параллелизма, установите 0 в качестве значения данного параметра, то есть значение по умолчанию. Установка значения 0 в качестве максимальной степени параллелизма позволяет SQL Server использовать все доступные процессоры (до 64 процессоров). Чтобы отключить создание параллельных планов, присвойте параметру max degree of parallelism значение 1. Задайте значение для параметра в диапазоне от 1 до 32 767, чтобы указать максимальное количество процессорных ядер, которые могут быть использованы при выполнении одного запроса. Если указано значение, превышающее количество доступных процессоров, используется действительное количество доступных процессоров. Если у компьютера только один процессор, то значение параметра max degree of parallelism учитываться не будет.
Значение параметра max degree of parallelism можно переопределить, задав в инструкции указание запроса MAXDOP. Дополнительные сведения см. в разделе .
Операции по созданию и перестройке индексов, а также по удалению кластеризованного индекса могут оказаться достаточно ресурсоемкими. Значение параметра max degree of parallelism для операций с индексами можно переопределить, указав в инструкции параметр индекса MAXDOP. Значение MAXDOP применяется к инструкции во время выполнения и в метаданных индекса не хранится. Дополнительные сведения см. в статье .
Помимо запросов и операций с индексами, этот параметр также управляет степенью параллелизма при выполнении инструкций DBCC CHECKTABLE, DBCC CHECKDB и DBCC CHECKFILEGROUP. Планы параллельного выполнения для этих инструкций можно отключить с помощью флага трассировки 2528. Дополнительные сведения см. в разделе .
Безопасность
Разрешения
Разрешения на выполнение хранимой процедуры sp_configure без параметров или только с первым параметром по умолчанию предоставляются всем пользователям. Для выполнения процедуры sp_configure с обоими параметрами для изменения параметра конфигурации или запуска инструкции RECONFIGURE необходимо иметь разрешение ALTER SETTINGS на уровне сервера. Разрешение ALTER SETTINGS неявным образом предоставлено предопределенным ролям сервера sysadmin и serveradmin .
В обозревателе объектов щелкните правой кнопкой мыши сервер и выберите пункт Свойства .
Щелкните узел Дополнительно .
В поле Максимальная степень параллелизма укажите максимальное число процессоров, которое может быть использовано в плане параллельного выполнения.
Настройка параметра максимальной степени параллелизма
Установите соединение с компонентом Компонент Database Engine.
На панели «Стандартная» нажмите Создать запрос .
Скопируйте следующий пример в окно запроса и нажмите кнопку Выполнить . В этом примере описывается использование процедуры для задания значения параметра max degree of parallelism равным 8 .
USE AdventureWorks2012 ; GO EXEC sp_configure "show advanced options" , 1 ; GO RECONFIGURE WITH OVERRIDE; GO EXEC sp_configure "max degree of parallelism" , 8 ; GO RECONFIGURE WITH OVERRIDE; GO
Дополнительные сведения см. в статье
Цель: изучить влияние параллелизма SQL на работу с запросами 1С
Литература:
Тестовая среда:
· Windows server 2008 R2 Enterprise
· MS SQL server 2008 R2
· 1С Предприятие 8.2.19.90
Рисунок 1. SQL properties “General”

Рисунок 2. SQL properties “Advansed”
Инструменты:
· SQL server profiler
· Консоль запросов 1С
Тестовый запрос:
ВЫБРАТЬ
АК.Наименование КАК Наименование
ИЗ
РегистрСведений.АдресныйКлассификатор КАК АК
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.АдресныйКлассификатор КАК АК1
ПО АК.Код = АК1.Код
Подготовка:
Запускаем SQL server Profiler, устанавливаем соединение, отмечаем события и колонки как показано на рисунке 3.

Рисунок 3. Trace properties
Устанавливаем отбор для нашей базы
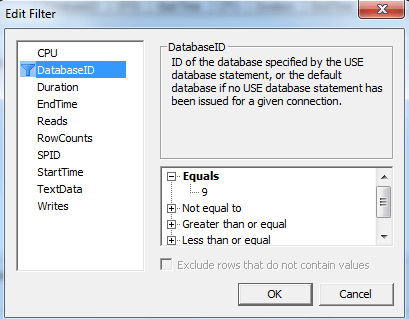
Рисунок 4. Фильтр по базе
Сокращения:
· Max degree of parallelism – MDOP
· Сost threshold for parallelism - cost
Тестирование последовательного плана запроса (MDOP = 1)

Рисунок 5. Консоль запросов – время выполнения 20 сек.
Параметр SQL сервера “Max degree of parallelism” установлен в 1 (без параллелизма). Смотрим результат в профайлере (рис.6)

Рисунок 6. Последовательный план запроса
SQL сервер сформировал последовательный план запроса, при этом: общая загрузка CPU = 6,750 (сек), а время на выполнение запроса = 7,097(сек)
Тестирование параллельного плана запроса (MDOP = 0, cost =5)
Переводим SQL server в режим параллелизма (в SQL Query):
USE master ;
EXEC sp_configure "show advanced option" , 1;
RECONFIGURE WITH OVERRIDE
USE master ;
exec sp_configure "max degree of parallelism" , 0;
RECONFIGURE WITH OVERRIDE
Выполняем тот же запрос (Рисунок 7)

Рисунок 7. Консоль запросов – время выполнения 16 сек.
Проверяем результат в профайлере (Рисунок 8)

Рисунок 8. Параллельный план запроса
Сервер SQL в этот раз сформировал параллельный план запроса, при этом общая загрузка CPU = 7,905 сек, а длительность выполнения запроса = 3,458 сек
Тестирование последовательного плана запроса (MDOP = 0, cost = 150)
Попытаемся избавиться от параллельного плана, используя параметр «Сost threshold for parallelism». По умолчанию параметр установлен в 5. В нашем случае от формирования параллельного плана удалось избавиться при значении 150 (в SQL Query):
USE master ;
exec sp_configure "cost threshold for parallelism" , 150 ;
Проверяем выполнение запроса в данных условиях (рис. 9)

Рисунок 9. Консоль запросов – время выполнения 20 сек.
Проверяем результат в профайлере (рис.10)

Рисунок 10. Последовательный план запроса.
Сервер SQL сформировал последовательный план запроса. Общая загрузка CPU = 7,171 сек, время выполнения запроса =7, 864 сек.
Выводы:
· Выполнение тестового запроса в среде 1С Предприятия с использованием SQL сервером параллельного плана запроса дает значительный прирост производительности по сравнению с последовательным планом (16 сек. против 20 сек. – выигрыш 4 сек.)
· Выполнения тестового запроса самим сервером SQL при использовании параллельного плана запроса происходит в два раза быстрее, чем при использовании последовательного плана запроса (3,5 сек. против 7,1 сек.)
· Параллелизм SQL сервера можно регулировать не только, используя параметр MDOP, но и параметр «Сost threshold for parallelism»