Maksimum paralellik derecesi (DOP) - isteğe bağlı yapılandırma seçeneği SQL Server birçok sorunun bağlantılı olduğu ve birçok yayının ayrıldığı. Bu blog yazısında yazar, bu seçeneğin ne yaptığı ve nasıl kullanılacağı konusunda biraz netlik sağlamayı umuyor.
İlk olarak, yazar, yukarıdaki seçeneğin SQL Server'ın birden fazla bağlantıya (veya kullanıcıya) hizmet verirken kullanabileceği kaç CPU'yu belirlediğine dair herhangi bir şüpheyi ortadan kaldırmak istiyor - öyle değil! SQL Server'ın dört etkin olmayan işlemciye erişimi varsa ve dört işlemcinin tümünü kullanacak şekilde yapılandırılmışsa, maksimum paralellik derecesinden bağımsız olarak dört işlemcinin tümünü kullanır.
Peki bu seçenek ne işe yarıyor? Bu seçenek, SQL Server'ın tek bir sorgu için kullanabileceği maksimum işlemci sayısını ayarlar. SQL Server'a yapılan sorgunun dönmesi gerekiyorsa büyük hacimli veri (birçok kayıt), bazen onu paralelleştirmek, her biri kendi satır alt kümesini döndürecek birkaç küçük sorguya bölmek mantıklıdır. Bu nedenle, SQL Server birden çok işlemci kullanabilir ve bu nedenle, çok işlemcili sistemlerde, çok sayıda tüm sorgu kaydı potansiyel olarak tek işlemcili bir sisteme göre daha hızlı döndürülebilir.
SQL Server "Intra Query Parallelism"i başlatmadan önce karşılanması gereken birçok kriter vardır ve bunları burada detaylandırmanın bir anlamı yoktur. Bunları BOL'de "Paralellik derecesi" ifadesini aratarak bulabilirsiniz. Paralelleştirme kararının, işlemci için belleğin kullanılabilirliğine ve özellikle işlemcilerin kullanılabilirliğine bağlı olduğunu söylüyor.
Öyleyse, neden bu seçeneği kullanmayı düşünmeliyiz - çünkü onu varsayılan değerinde bırakmak (SQL Server'ın kendisi paralelleştirmeye karar verir) bazen istenmeyen etkilere neden olabilir. Bu efektler şuna benzer:
Paralelleştirilmiş sorgular daha yavaştır.
İsteklerin yürütme süresi deterministik olmayabilir ve bu da kullanıcıları rahatsız edebilir. Yürütme süreleri değişebilir çünkü:
Sorgu bazen paralelleştirilebilir ve bazen olmayabilir.
İşlemciler daha önce işle aşırı yüklenmişse, bir istek paralel bir istek tarafından engellenebilir.
Devam etmeden önce yazar, paralelliğin iç kısımlarına dalmaya özel bir ihtiyaç olmadığını belirtmek ister. Bu konuyla ilgileniyorsanız, bu bilgilerin daha ayrıntılı olarak sunulduğu Books on Line'daki "Paralel Sorgu İşleme" makalesini okuyabilirsiniz. Yazar, paralelliğin iç organizasyonu hakkında bilinmesi gereken sadece iki önemli şey olduğuna inanmaktadır:
Paralel sorgular, "Maksimum paralellik derecesi" seçeneğinde belirtilenden daha fazla iş parçacığı oluşturabilir. DOP 4, dördü sorgu için olmak üzere on ikiden fazla iş parçacığı ve sıralamalar, iş parçacıkları, toplamalar ve derlemeler vb. için kullanılan ek iş parçacıkları oluşturabilir.
Paralelleştirme istekleri, farklı SPID'lerin CXPACKET veya 0X0200 bekleme türüyle beklemesine neden olabilir. Bu, paralel işlemlerde bekleyen ve sysprocesses'te bekleme tipi: CXPACKET olan SPID'leri bulmak için kullanılabilir. Bu görevi kolaylaştırmak için yazar, blogunda saklı yordamı kullanmanızı önerir: track_waitstats.
Ve böylece "Sorgu paralelleştirildiğinde daha yavaş çalışabilir" neden?
Sistem çok zayıfsa verim disk alt sistemleri, daha sonra bir isteği analiz ederken, ayrıştırılması paralellik olmadan daha uzun sürebilir.
Paralel olarak kullanılan ve daha sonra başlatılan başka bir işlemin neden olduğu işlemci için veri çarpıklığı veya veri aralıklarının engellenmesi vb. olasıdır.
Yüklem için bir dizin yoksa, bu bir tablo taramasıyla sonuçlanır. Bir sorgu içinde paralel işlem, sorgunun sıralı bir yürütme planı ve doğru dizin ile çok daha hızlı çalışacağı gerçeğini gizleyebilir.
Tüm bunlardan, paralellik olmadan isteğin yürütülmesini kontrol etme önerisini takip eder (DOP = 1), bu olası sorunları belirlemeye yardımcı olacaktır.
Yukarıda bahsedilen paralelliğin etkileri, kendi başlarına, paralelleştirme sorgularının iç mekaniğinin OLTP uygulamalarında kullanım için uygun olmadığı fikrine yol açmalıdır. Bunlar, sorgu yürütme sürelerinin değiştirilmesinin kullanıcılar için can sıkıcı olabileceği ve birden çok kullanıcıya hizmet veren bir sunucunun, bu uygulamaların doğal işlemci iş yükü profili nedeniyle paralel yürütme planı seçmesinin pek mümkün olmadığı uygulamalardır.
Bu nedenle, paralellik kullanacaksanız, büyük olasılıkla, çok fazla isteğin olmadığı, ancak oldukça ağır oldukları ve güçlü bir sunucuda çalıştığı veri çıkarma görevleri (veri ambarı), karar destek veya raporlama sistemleri için gerekli olacaktır. büyük miktarda operasyonel bellek ile.
Eşzamanlılık kullanmaya karar verirseniz, DOP için hangi değeri ayarlamanız gerekir? 8 işlemciniz varsa DOP = 4 olarak ayarlamak bu mekanizma için iyi bir uygulamadır ve bu büyük olasılıkla en uygun ayardır. Ancak, bu şekilde çalışacağının garantisi yoktur. Bundan emin olmanın tek yolu, DOP için farklı değerleri test etmektir. Buna ek olarak, yazar, bu sayıyı asla mevcut işlemci sayısının yarısından fazlasına ayarlamamak için ampirik tavsiyesini sunmak istedi. Yazarın altıdan az işlemcisi olsaydı, DOP'yi 1'e ayarlardı ve bu da paralelleştirmeye izin vermezdi. Yalnızca bir kullanıcı sürecini (bazı veri çıkarma teknolojileri veya raporlama görevleri) destekleyen bir veritabanı varsa bir istisna yapabilir, bu durumda bir istisna olarak DOP'yi 0'a (varsayılan değer) ayarlamak mümkün olacaktır, bu da Bir sorguyu paralelleştirme ihtiyacına karar vermek SQL Server'a bağlıdır.
Makaleyi bitirmeden önce yazar, paralel dizin oluşturmanın DOP için belirlediğiniz sayıya bağlı olduğu konusunda sizi uyarmak istedi. Bu, bu işlemin performansını iyileştirmek için dizin oluşturma veya yeniden oluşturma sırasında değiştirmek isteyebileceğiniz anlamına gelir ve elbette sorguda ayarlanan değeri yok saymanıza izin veren MAXDOP ipucunu kullanabilirsiniz. yapılandırma ve yoğun olmayan saatlerde kullanılabilir ...
Son olarak, hatalar nedeniyle paralelleştirme sırasında isteğiniz yavaşlayabilir, bu nedenle sunucunuzda en son hizmet paketinin kurulu olduğundan emin olun.
| CREATE proc track_waitstats (@num_samples int = 10 , @ gecikme sayısı int = 1 , @ gecikme türü nvarchar ( 10 ) = "dakika") AS - T. Davidson - Bu saklı yordam sağlanır = OLDUĞU GİBİ = garanti olmadan,- ve hiçbir hak vermez. - Dahil edilen komut dosyası örneklerinin kullanımı şartlara tabidir - http://www.microsoft.com/info/cpyright.htm adresinde belirtilmiştir - @num_samples, bekleme istatistiklerini yakalama sayısıdır, - varsayılan 10 katıdır. varsayılan gecikme aralığı 1 dakikadır - delaynum gecikme aralığıdır. gecikme türü olup olmadığını belirtir - gecikme aralığı dakika veya saniyedir - mevcut değilse waitstats tablosu oluşturun, aksi takdirde kısaltın yoksa nocount'u açın (seçin 1 name = "waitstats"), tablo bekleme istatistikleri (varchar ( 80 ), sayısal istekler ( 20 ,1 ), sayısal ( 20 ,1 ), sayısal ( 20 ,1 ), şimdi datetime varsayılan getdate ()) başka tablo waitstats'ı kısalt dbcc sqlperf (waitstats, clear) - waitstats'ı temizle bildir @i int, @ delay varchar ( 8 ), @ dt varchar ( 3 ), @ şimdi tarih saat, @ totalwait sayısal ( 20 ,1 ), @ bitiş zamanı tarihsaat, @ başlangıç zamanı tarihsaat, @ saat int, @ dakika int, @ saniye int @i = seçin 1 @dt = büyük/küçük harf seçin (@delaytype) "dakika" olduğunda, ardından "dakika" olduğunda "m", ardından "min" olduğunda "m", ardından "mm" olduğunda "m" ve "mi" olduğunda "m" ve ardından "m" öğesini seçin "m" olduğunda "m" olduğunda "saniye" olduğunda sonra "s" olduğunda "saniye" olduğunda "s" "sn" olduğunda "s" sonra "s" olduğunda "s" olduğunda "s" başka @ @dt ("s", "m") içinde değilse gecikme türü bitişi yazdırmaya başla "lütfen gecikme türünü belirtin, örneğin saniye veya dakika"@dt = "s" başlangıcı ise dönüş bitişi @sec = @delaynum% öğesini seçin 60 @min seçin = yayın ((@delaynum / 60 ) int olarak) @hr = cast ((@min / 60 ) int olarak) @min = @min% öğesini seçin 60 @dt = "m" ise bitiş @sec = seçin 0 @min = @delaynum% öğesini seçin 60 @hr'yi seçin = yayınlayın ((@delaynum / 60 ) int olarak) end select @delay = right ("0" + convert (varchar ( 2 ), @ saat), 2 2 ), @ dk), 2 ) + ":" + + sağ ("0" + convert (varchar ( 2 ), @ sn), 2 ) eğer @hr> 23 veya @min> 59 veya @sec> 59 seçmeye başla "ss: aa: ss gecikme süresi olamaz> 23:59:59""gecikme aralığını seçin ve şunu yazın:" + convert (varchar ( 10 ), @ delaynum) + "," + @delaytype + "dönüştürür" + @delay return end while (@i<= @num_samples) begin insert into waitstats (, requests, ,) exec ("dbcc sqlperf(waitstats)" ) select @i = @i + 1 waitfor delay @delay End --- waitstats raporu oluştur get_waitstats yürüt --//--//--//--//--//--//--//--//--//-//--//--//--//--//--//--//--//--/ CREATE proc get_waitstats AS - Bu saklı yordam sağlanır = OLDUĞU GİBİ = hiçbir garanti olmadan ve- hiçbir hak vermez. - Dahil edilen komut dosyası örneklerinin kullanımı belirtilen şartlara tabidir. - http://www.microsoft.com/info/cpyright.htm adresinde -- - bu işlem, bekleme türlerini listeleyen bekleme istatistikleri raporu oluşturacaktır:- yüzde - track_waitstats yürütülürken çalıştırılabilir@now datetime, @ totalwait numeric ( 20 ,1 ), @ bitiş zamanı tarihsaat, @ başlangıç zamanı tarihsaat, @ sa int, @ min int, @ sec int select @ şimdi = maks (şimdi), @ başlangıç zamanı = min (şimdi), @ bitiş zamanı = maks (şimdi) waitstats'tan burada = " Toplam " --- bekleme, uyku ve resource_queue'yi Toplam'dan çıkarın@totalwait = toplam () + öğesini seçin 1 ("WAITFOR", "SLEEP", "RESOURCE_QUEUE", "Toplam", "*** toplam ***") olmayan bekleme durumlarından ve şimdi = @now - düzeltilmiş toplamları ekleyin, azalan yüzdeye göre sıralayın waitstats'ı sil burada = "*** total ***" ve şimdi = @now waitstats'a ekle "*** total ***" öğesini seçin, 0 , @ totalwait, @ totalwait, @ şimdi seç,, yüzde = yayın ( 100 * / @ sayısal olarak toplam bekleme ( 20 ,1 )) bekleme durumlarından ("WAITFOR", "SLEEP", "RESOURCE_QUEUE", "Toplam") ve şimdi = @şimdi yüzde azalmaya göre sırala |
Maksimum paralellik derecesi (DOP), birçok yayında tartışılan, tartışmalı ek bir SQL Server yapılandırma seçeneğidir. Bu blog yazısında yazar, bu seçeneğin ne yaptığı ve nasıl kullanılacağı konusunda biraz netlik sağlamayı umuyor.
İlk olarak, yazar, yukarıdaki seçeneğin SQL Server'ın birden fazla bağlantıya (veya kullanıcıya) hizmet verirken kullanabileceği kaç CPU'yu belirlediğine dair herhangi bir şüpheyi ortadan kaldırmak istiyor - öyle değil! SQL Server'ın dört etkin olmayan işlemciye erişimi varsa ve dört işlemcinin tümünü kullanacak şekilde yapılandırılmışsa, maksimum paralellik derecesinden bağımsız olarak dört işlemcinin tümünü kullanır.
Peki bu seçenek ne işe yarıyor? Bu seçenek, SQL Server'ın tek bir sorgu için kullanabileceği maksimum işlemci sayısını ayarlar. SQL Server'a yapılan bir sorgunun büyük miktarda veri (birçok kayıt) döndürmesi gerekiyorsa, bazen onu paralelleştirmek ve her biri kendi satır alt kümesini döndürecek birkaç küçük sorguya bölmek mantıklı olur. Bu nedenle, SQL Server birden çok işlemci kullanabilir ve bu nedenle, çok işlemcili sistemlerde, çok sayıda tüm sorgu kaydı potansiyel olarak tek işlemcili bir sisteme göre daha hızlı döndürülebilir.
SQL Server "Intra Query Parallelism"i başlatmadan önce karşılanması gereken birçok kriter vardır ve bunları burada detaylandırmanın bir anlamı yoktur. Bunları BOL'de "Paralellik derecesi" ifadesini aratarak bulabilirsiniz. Paralelleştirme kararının, işlemci için belleğin kullanılabilirliğine ve özellikle işlemcilerin kullanılabilirliğine bağlı olduğunu söylüyor.
Öyleyse, neden bu seçeneği kullanmayı düşünmeliyiz - çünkü onu varsayılan değerinde bırakmak (SQL Server'ın kendisi paralelleştirmeye karar verir) bazen istenmeyen etkilere neden olabilir. Bu efektler şuna benzer:
- Paralelleştirilmiş sorgular daha yavaştır.
- İsteklerin yürütme süresi deterministik olmayabilir ve bu da kullanıcıları rahatsız edebilir. Yürütme süreleri değişebilir çünkü:
- Sorgu bazen paralelleştirilebilir ve bazen olmayabilir.
- İşlemciler daha önce işle aşırı yüklenmişse, bir istek paralel bir istek tarafından engellenebilir.
Devam etmeden önce yazar, paralelliğin iç kısımlarına dalmaya özel bir ihtiyaç olmadığını belirtmek ister. Bu konuyla ilgileniyorsanız, bu bilgilerin daha ayrıntılı olarak sunulduğu Books on Line'daki "Paralel Sorgu İşleme" makalesini okuyabilirsiniz. Yazar, paralelliğin iç organizasyonu hakkında bilinmesi gereken sadece iki önemli şey olduğuna inanmaktadır:
- Paralel sorgular, "Maksimum paralellik derecesi" seçeneğinde belirtilenden daha fazla iş parçacığı oluşturabilir. DOP 4, dördü sorgu için olmak üzere on ikiden fazla iş parçacığı ve sıralamalar, iş parçacıkları, toplamalar ve derlemeler vb. için kullanılan ek iş parçacıkları oluşturabilir.
- Paralelleştirme istekleri, farklı SPID'lerin CXPACKET veya 0X0200 bekleme türüyle beklemesine neden olabilir. Bu, paralel işlemlerde bekleyen ve sysprocesses'te bekleme tipi: CXPACKET olan SPID'leri bulmak için kullanılabilir. Bu görevi kolaylaştırmak için yazar, blogunda saklı yordamı kullanmanızı önerir: track_waitstats.
Ve böylece "Sorgu paralelleştirildiğinde daha yavaş çalışabilir" neden?
- Sistemin disk alt sistemlerinin verimi çok düşükse, bir isteği analiz ederken, ayrıştırılması paralellik olmadan daha uzun sürebilir.
- Paralel olarak kullanılan ve daha sonra başlatılan başka bir işlemin neden olduğu işlemci için veri çarpıklığı veya veri aralıklarının engellenmesi vb. olasıdır.
- Yüklem için bir dizin yoksa, bu bir tablo taramasıyla sonuçlanır. Bir sorgu içinde paralel işlem, sorgunun sıralı bir yürütme planı ve doğru dizin ile çok daha hızlı çalışacağı gerçeğini gizleyebilir.
Yukarıda bahsedilen paralelliğin etkileri, kendi başlarına, paralelleştirme sorgularının iç mekaniğinin OLTP uygulamalarında kullanım için uygun olmadığı fikrine yol açmalıdır. Bunlar, sorgu yürütme sürelerinin değiştirilmesinin kullanıcılar için can sıkıcı olabileceği ve birden çok kullanıcıya hizmet veren bir sunucunun, bu uygulamaların doğal işlemci iş yükü profili nedeniyle paralel yürütme planı seçmesinin pek mümkün olmadığı uygulamalardır.
Bu nedenle, paralellik kullanacaksanız, büyük olasılıkla, çok fazla isteğin olmadığı, ancak oldukça ağır oldukları ve güçlü bir sunucuda çalıştığı veri çıkarma görevleri (veri ambarı), karar destek veya raporlama sistemleri için gerekli olacaktır. büyük miktarda operasyonel bellek ile.
Eşzamanlılık kullanmaya karar verirseniz, DOP için hangi değeri ayarlamanız gerekir? 8 işlemciniz varsa DOP = 4 olarak ayarlamak bu mekanizma için iyi bir uygulamadır ve bu büyük olasılıkla en uygun ayardır. Ancak, bu şekilde çalışacağının garantisi yoktur. Bundan emin olmanın tek yolu, DOP için farklı değerleri test etmektir. Buna ek olarak, yazar, bu sayıyı asla mevcut işlemci sayısının yarısından fazlasına ayarlamamak için ampirik tavsiyesini sunmak istedi. Yazarın altıdan az işlemcisi olsaydı, DOP'yi 1'e ayarlardı ve bu da paralelleştirmeye izin vermezdi. Yalnızca bir kullanıcı sürecini (bazı veri çıkarma teknolojileri veya raporlama görevleri) destekleyen bir veritabanı varsa bir istisna yapabilir, bu durumda bir istisna olarak DOP'yi 0'a (varsayılan değer) ayarlamak mümkün olacaktır, bu da Bir sorguyu paralelleştirme ihtiyacına karar vermek SQL Server'a bağlıdır.
Makaleyi bitirmeden önce yazar, paralel dizin oluşturmanın DOP için belirlediğiniz sayıya bağlı olduğu konusunda sizi uyarmak istedi. Bu, bu işlemin performansını iyileştirmek için dizin oluşturma veya yeniden oluşturma sırasında değiştirmek isteyebileceğiniz anlamına gelir ve elbette sorguda ayarlanan değeri yok saymanıza izin veren MAXDOP ipucunu kullanabilirsiniz. yapılandırma ve yoğun olmayan saatlerde kullanılabilir ...
Son olarak, hatalar nedeniyle paralelleştirme sırasında isteğiniz yavaşlayabilir, bu nedenle sunucunuzda en son hizmet paketinin kurulu olduğundan emin olun.
REATE proc track_waitstats@num_samples int = 10
, @ gecikme sayısı int = 1
, @ gecikme türü nvarchar ( 10 ) = "dakika"
OLARAK
- T. Davidson
- Bu saklı yordam sağlanır = OLDUĞU GİBİ = garanti olmadan,
- ve hiçbir hak vermez.
- Dahil edilen komut dosyası örneklerinin kullanımı şartlara tabidir
- http://www.microsoft.com/info/cpyright.htm adresinde belirtilmiştir
- @num_samples, bekleme istatistiklerini yakalama sayısıdır,
- varsayılan 10 katıdır. varsayılan gecikme aralığı 1 dakikadır
- delaynum gecikme aralığıdır. gecikme türü olup olmadığını belirtir
- gecikme aralığı dakika veya saniyedir
- mevcut değilse waitstats tablosu oluşturun, aksi takdirde kısaltın
saymamak
yoksa (seçin 1
name = "bekleme istatistikleri") olan sistem nesnelerinden
tablo bekleme istatistikleri oluştur (varchar ( 80
),
sayısal istekler ( 20
,1
),
sayısal ( 20
,1
),
sayısal ( 20
,1
),
şimdi tarihsaat varsayılan getdate ())
başka tablo bekleme istatistiklerini kısalt
dbcc sqlperf (bekleme istatistikleri, temizle) - bekleme istatistiklerini temizle
@i int bildir
, @ gecikme varchar ( 8
)
, @ dt varchar ( 3
)
, @ şimdi tarihsaat
, @ totalwait sayısal ( 20
,1
)
, @ bitiş zamanı tarihsaat
, @ başlangıç zamanı tarihsaat
, @ saat int
, @ dk int
, @ sn int
@i'yi seçin = 1
@dt seçin = küçük harf (@delaytype)
"dakika" olduğunda "m"
"dakika" olduğunda "m"
"dk" olduğunda "m"
"mm" olduğunda "m"
"mi" olduğunda "m"
"m" olduğunda "m"
"saniye" olduğunda "s"
"saniye" olduğunda "s"
"sn" olduğunda "s"
ne zaman "ss" sonra "s"
"s" olduğunda "s"
başka @delaytype
son
@dt ("s", "m") içinde değilse
başlamak
Yazdır "lütfen gecikme türünü belirtin, örneğin saniye veya dakika"
dönüş
son
@dt = "s" ise
başlamak
@sec = @delaynum% öğesini seçin 60
@min seçin = yayın ((@delaynum / 60
) int olarak)
@hr = yayınla ((@min / 60
) int olarak)
@min = @min% öğesini seçin 60
son
@dt = "m" ise
başlamak
@sn seçin = 0
@min = @delaynum% öğesini seçin 60
@hr'yi seçin = yayınlayın ((@delaynum / 60
) int olarak)
son
@delay = sağ seçin ("0" + convert (varchar ( 2
), @ saat), 2
) + ":"
+
2
), @ dk), 2
) + ":"
+
+ sağ ("0" + convert (varchar ( 2
), @ sn), 2
)
@hr> ise 23
veya @min> 59
veya @sec> 59
başlamak
Seçme "ss: aa: ss gecikme süresi olamaz> 23:59:59"
"gecikme aralığını seçin ve şunu yazın:" + convert (varchar ( 10
)
, @ delaynum) + "," + @delaytype + "dönüştürür"
+ @gecikme
dönüş
son
süre (@i<= @num_samples)
başlamak
bekleme istatistiklerine ekle (, istekler,
,)
exec ("dbcc sqlperf (bekleme istatistikleri)")
@i = @i + seçin 1
bekleme gecikmesi @delay
Son
Bekleme istatistikleri raporu oluştur
get_waitstats'ı çalıştır
--//--//--//--//--//--//--//--//--//-//--//--//--//--//--//--//--//--/
CREATE proc get_waitstats
OLARAK
- Bu saklı yordam sağlanır = OLDUĞU GİBİ = hiçbir garanti olmadan ve
- hiçbir hak vermez.
- Dahil edilen komut dosyası örneklerinin kullanımı belirtilen şartlara tabidir.
- http://www.microsoft.com/info/cpyright.htm adresinde
--
- bu işlem, bekleme türlerini listeleyen bekleme istatistikleri raporu oluşturacaktır:
- yüzde
- track_waitstats yürütülürken çalıştırılabilir
saymamak
@now datetime bildir
, @ totalwait sayısal ( 20
,1
)
, @ bitiş zamanı tarihsaat
, @ başlangıç zamanı tarihsaat
, @ saat int
, @ dk int
, @ sn int
@ şimdi seçin = maks (şimdi), @ başlangıç zamanı = min (şimdi), @ bitiş zamanı = maks (şimdi)
waitstats'tan burada = "Toplam"
Toplamdan waitfor, sleep ve resource_queue'yu çıkarın
@totalwait = toplam () + öğesini seçin 1
bekleme istatistiklerinden
("WAITFOR", "SLEEP", "RESOURCE_QUEUE" içinde değil)
, "Toplam", "*** toplam ***") ve şimdi = @şimdi
Düzeltilmiş toplamları ekleyin, azalan yüzdeye göre sıralayın
bekleme istatistiklerini sil burada = "*** toplam ***" ve şimdi = @now
bekleme istatistiklerine ekleyin "*** toplam ***" öğesini seçin
,0
, @ totalwait
, @ totalwait
, @ şimdi
Seçme
,
, yüzde = döküm ( 100
* / @ sayısal olarak toplam bekleme ( 20
,1
))
bekleme istatistiklerinden
("WAITFOR", "SLEEP", "RESOURCE_QUEUE", "Toplam") içinde olmayan yerlerde
ve şimdi = @şimdi
yüzde azalmaya göre sırala
1C çalışmasının optimizasyonu. MS SQL Server'ı Yapılandırma
Veritabanı Anında Dosya Başlatmayı Etkinleştir
- Veritabanı oluşturma
- Mevcut bir veritabanına dosya, günlük veya veri ekleyin
- Mevcut bir dosyanın boyutunu büyütme (otomatik büyütme işlemleri dahil)
- Bir veritabanını veya dosya grubunu kurtarma
Ayarı etkinleştirmek için:
- Yedekleme dosyasının oluşturulacağı bilgisayarda Yerel Güvenlik İlkesi uygulamasını (secpol.msc) açın.
- Sol bölmedeki Yerel İlkeler düğümünü genişletin ve ardından Kullanıcı Hakları Ataması öğesine tıklayın.
- Sağ bölmede, Birim Bakım Görevlerini Gerçekleştir'e çift tıklayın.
- Bir kullanıcı veya grup için "Ekle" düğmesini tıklayın ve MS SQL Server'ın altında çalıştığı kullanıcıyı ekleyin.
- Uygula düğmesini tıklayın.
Sayfaları bellekte kilitle'yi açın
Bu ayar, sistemin veri sayfalarını diskteki sanal belleğe göndermemesi için hangi hesapların verileri RAM'e kaydedebileceğini belirler, bu da performansı artırabilir.
Ayarı etkinleştirmek için:
- Başlat menüsünden Çalıştır'ı seçin. Aç kutusuna gpedit.msc yazın.
- Yerel Grup İlkesi Düzenleyicisi konsolunda Bilgisayar Yapılandırması'nı ve ardından Windows Yapılandırması'nı genişletin.
- Güvenlik Ayarları ve Yerel İlkeler'i genişletin.
- Kullanıcı Hakları Atama klasörünü seçin.
- İlkeler ayrıntılar bölmesinde gösterilecektir.
- Bu panelde Sayfaları bellekte kilitle seçeneğine çift tıklayın.
- Yerel Güvenlik Seçeneği - Sayfaları Bellekte Kilitle iletişim kutusunda Kullanıcı veya grup ekle'yi seçin.
- Seç: Kullanıcılar, Hizmet Hesapları veya Gruplar iletişim kutusunda, MS SQL Server hizmetini çalıştırdığınız hesabı ekleyin.
- Değişikliklerin etkili olması için sunucuyu yeniden başlatın veya MS SQL Server'ı çalıştırdığınız kullanıcıda oturum açın.
Sürücüler için DFSS'yi devre dışı bırakın.
Dinamik Adil Paylaşım Planlaması, donanım kaynaklarının kullanıcılar arasında dengelenmesinden ve dağıtılmasından sorumludur. Bazen çalışmaları 1C'nin performansını olumsuz etkileyebilir. Yalnızca diskler için devre dışı bırakmak için yapmanız gerekenler:
- Kayıt defterinde HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Services \ TSFairShare \ Disk şubesini bulun
- EnableFairShare parametresinin değerini 0 olarak ayarlayın
Veritabanı dosyalarını içeren dizinler için veri sıkıştırmasını devre dışı bırakın.
Sıkıştırma etkinleştirildiğinde, işletim sistemi değişiklik sırasında dosyaları ek olarak işlemeye çalışır, bu da yazma işlemini yavaşlatır, ancak yerden tasarruf sağlar.
Bir dizindeki dosyaların sıkıştırılmasını devre dışı bırakmak için şunları yapmanız gerekir:
- Dizin özelliklerini aç
- Genel sekmesinde Diğer düğmesini tıklayın.
- Disk alanından tasarruf etmek için "Sıkıştır" bayrağının işaretini kaldırın.
Maksimum paralellik derecesini 1 olarak ayarlayın.
Bu parametre, bir isteğin kaç tane iş parçacığı üzerinde yürütülebileceğini belirler. Varsayılan olarak, parametre 0'a eşittir; bu, iş parçacığı sayısını sunucunun kendisinin seçtiği anlamına gelir. 1C yük karakteristiğine sahip bazlar için bu parametrenin 1 olarak ayarlanması önerilir, çünkü çoğu durumda, bunun sorguların performansı üzerinde olumlu bir etkisi olacaktır.
Parametreyi yapılandırmak için şunları yapmalısınız:
- Sunucu özelliklerini açın ve Gelişmiş sekmesini seçin
- Parametre değerini bire eşit olarak ayarlayın.
MS SQL Server'ın maksimum bellek boyutunu sınırlayın.
MS SQL Server için Bellek = Her şeyin belleği - İşletim Sistemi için bellek - 1C sunucusu için bellek
Örneğin sunucunun 64 GB RAM'i var, 1C sunucusunun yeterli olması için DBMS sunucusuna ne kadar bellek ayırmanız gerektiğini anlamanız gerekiyor.
İşletim sisteminin normal çalışması için çoğu durumda 4 GB, genellikle 2-3 GB olmak üzere fazlasıyla yeterlidir.
1C sunucusu için ne kadar bellek gerektiğini belirlemek için, bir iş gününün ortasında bir sunucu kümesinin süreçleri tarafından ne kadar bellek işgal edildiğini görmeniz gerekir. Bu işlemler ragent, rmngr ve rphost olup, bu işlemler sunucu kümesi ile ilgili bölümde detaylı olarak tartışılmaktadır. Veri tabanında maksimum sayıda kullanıcının çalıştığı en yoğun iş faaliyeti döneminde verileri tam olarak almak gerekir. Bu verileri aldıktan sonra, 1C'de "ağır" işlemlere başlanması durumunda bunlara 1 GB eklemek gerekir.
MS SQL Server tarafından kullanılan maksimum bellek miktarını ayarlamak için şunları yapmanız gerekir:
- Management Studio'yu başlatın ve istediğiniz sunucuya bağlanın
- Sunucu özelliklerini açın ve Bellek sekmesini seçin
- Maximum server memory size parametresi için bir değer belirleyin.
Boost SQL Server öncelik bayrağını etkinleştirin.
Bu bayrak, MS SQL Server işleminin diğer işlemlere göre önceliğini artırmanıza izin verir.
Bayrağı etkinleştirmek, yalnızca 1C sunucusu, DBMS sunucusunun bulunduğu bilgisayarda yüklü değilse mantıklıdır.
Bayrağı ayarlamak için ihtiyacınız olan:
- Management Studio'yu başlatın ve istediğiniz sunucuya bağlanın
- Sunucu özelliklerini açın ve İşlemciler sekmesini seçin
- "SQL Server önceliğini artır" bayrağını etkinleştirin ve Tamam'ı tıklayın.
Otomatik büyüyen veritabanı dosyalarının boyutunu ayarlayın.
Otomatik büyüme, dolduğunda veritabanı dosyasının boyutunun artacağı miktarı belirtmenize olanak tanır. Otomatik genişletme boyutunu çok küçük ayarlarsanız, dosya çok sık genişler ve bu da zaman alır. 512 MB ile 5 GB arasında bir değer ayarlanması önerilir.
- Management Studio'yu başlatın ve istediğiniz sunucuya bağlanın
- Otomatik Artış sütunundaki her dosyanın karşısına gerekli değeri girin
Bu ayar yalnızca seçilen baz istasyonu için geçerli olacaktır. Bu ayarın tüm bazlar için geçerli olmasını istiyorsanız, hizmet tabanı modeli için aynı adımları uygulamanız gerekir. Bundan sonra, yeni oluşturulan tüm tabanlar, model tabanı ile aynı ayarlara sahip olacaktır.
Mdf veri dosyalarını ve ldf günlük dosyalarını farklı fiziksel disklere yayın.
Bu durumda, dosyalarla çalışmak sırayla değil, pratik olarak paralel olarak gidebilir, bu da disk işlemlerinin hızını artırır. SSD'ler bu amaçlar için en uygunudur.
Dosyaları aktarmak için ihtiyacınız olan:
- Management Studio'yu başlatın ve istediğiniz sunucuya bağlanın
- Gerekli veritabanının özelliklerini açın ve Dosyalar sekmesini seçin
- Dosya adlarını ve konumlarını hatırla
- Bağlam menüsünden Görevler - Ayır'ı seçerek tabanı ayırın
- Bağlantıları sil bayrağını ayarlayın ve Tamam'ı tıklayın.
- Explorer'ı açın ve veri dosyasını ve günlük dosyasını istediğiniz ortama taşıyın
- Management Studio'da, sunucunun bağlam menüsünü açın ve Temel öğeyi ekle öğesini seçin.
- Ekle düğmesini tıklayın ve yeni diskten mdf dosyasını belirtin
- Veritabanı ile ilgili bilgilerin bulunduğu alt pencerede, günlük dosyası doğrultusunda, işlem günlüğü dosyasına yeni bir yol belirtmeniz ve Tamam'ı tıklamanız gerekir.
BU MADDENİN KAPSAMI: SQL Server (2008'den beri) Azure SQL Veritabanı Azure SQL Veri AmbarıParalel Veri Ambarı
Bu bölüm, sunucu yapılandırma seçeneğinin nasıl yapılandırılacağını açıklar. maksimum paralellik derecesi (MAXDOP) SQL Server 2016'da SQL Server Management Studio veya Transact-SQL kullanarak. Bir SQL Server örneği çok işlemcili bir bilgisayarda çalışırken, paralel yürütme planlarının her biri için tek bir ifadeyi yürütmek için kullanılan işlemci sayısı olan en uygun paralellik derecesini belirler. Paralel yürütme açısından işlemci sayısını sınırlamak için parametre kullanılabilir maksimum paralellik derecesi... SQL Server, sorgular, dizin DDL işlemleri, paralel ekler, çevrimiçi sütun güncellemeleri, paralel istatistik toplama ve statik ve anahtar kümesi imleçlerini doldurma için paralel yürütme planlarını dikkate alır.
Kısıtlamalar
- Varsayılan olmayan bir benzeşim maskesine ayarlandığında, simetrik çok işlemcili (SMP) sistemlerde SQL Server'ın kullanabileceği işlemci sayısını sınırlayabilir.
Bu ayar isteğe bağlıdır ve yalnızca deneyimli DBA'lar veya SQL Server Sertifikalı Teknisyenler tarafından değiştirilmelidir.
Sunucunun maksimum paralellik derecesini belirlemesine izin vermek için bu parametreyi varsayılan olan 0'a ayarlayın. Maksimum paralellik derecesinin 0 olarak ayarlanması, SQL Server'ın mevcut tüm işlemcileri (64 işlemciye kadar) kullanmasına izin verir. Paralel planların oluşturulmasını devre dışı bırakmak için parametreyi ayarlayın maksimum paralellik derecesi değer 1. Tek bir sorguda kullanılabilecek maksimum işlemci çekirdeği sayısını belirtmek için parametre için 1 ile 32.767 arasında bir değer belirtin. Kullanılabilir işlemci sayısını aşan bir değer belirtilirse, mevcut işlemcilerin gerçek sayısı kullanılır. Bilgisayarda yalnızca bir işlemci varsa, parametre değeri maksimum paralellik derecesi sayılmayacak.
Maksimum paralellik derecesi parametresi, ifadede bir MAXDOP sorgusu belirtilerek geçersiz kılınabilir. Daha fazla bilgi için, bkz.
Dizinler oluşturmak ve yeniden oluşturmak ve kümelenmiş bir dizini bırakmak kaynak yoğun olabilir. İfadede MAXDOP indeks parametresini belirterek indeks işlemleri için maksimum paralellik derecesi parametresini geçersiz kılabilirsiniz. MAXDOP değeri, çalışma zamanında ifadeye uygulanır ve dizin meta verilerinde depolanmaz. Daha fazla bilgi için makaleye bakın.
Bu parametre, sorgular ve dizin işlemlerine ek olarak, DBCC CHECKTABLE, DBCC CHECKDB ve DBCC CHECKFILEGROUP deyimleri yürütülürken paralellik derecesini de kontrol eder. Bu ifadeler için paralel yürütme planları 2528 izleme bayrağı kullanılarak devre dışı bırakılabilir. Daha fazla bilgi için bkz.
Emniyet
izinler
Saklı Yordam Yürütme İzinleri sp_configure parametresiz veya varsayılan olarak yalnızca ilk parametre ile tüm kullanıcılara sağlanır. Prosedürü tamamlamak için sp_configure her iki seçenekte de, bir yapılandırma seçeneğini değiştirmek veya bir RECONFIGURE ifadesi çalıştırmak için sunucu düzeyinde AYARLARI DEĞİŞTİR iznine sahip olmanız gerekir. ALTER SETTINGS izni, önceden tanımlanmış sunucu rollerine örtülü olarak verildi sistem yöneticisi ve sunucu yöneticisi .
V nesne gezgini sunucuya sağ tıklayın ve seçin Özellikler.
Bir düğümü tıklayın bunlara ek olarak .
alanında Maksimum paralellik derecesi paralel yürütme planında kullanılabilecek maksimum işlemci sayısını belirtin.
Maksimum paralellik parametresinin ayarlanması
Veritabanı Motoru ile bağlantı kurun.
Standart panelinde, öğesine tıklayın. İstek oluştur.
Aşağıdaki örneği sorgu penceresine kopyalayın ve düğmesine tıklayın Uygulamak... Bu örnek, maksimum paralellik parametresini 8'e ayarlamak için prosedürün nasıl kullanılacağını açıklar.
AdventureWorks2012'yi KULLANIN; GO EXEC sp_configure "gelişmiş seçenekleri göster", 1; GEÇERSİZ KILMA İLE YENİDEN YAPILANDIRIN; GO EXEC sp_configure "maksimum paralellik derecesi", 8; GEÇERSİZ KILMA İLE YENİDEN YAPILANDIRIN; Gitmek
Daha fazla bilgi için makaleye bakın
Hedef: SQL paralelliğinin 1C sorgularıyla çalışma üzerindeki etkisini inceleyin
Edebiyat:
Test ortamı:
Windows sunucusu 2008 R2 Kurumsal
MS SQL sunucusu 2008 R2
1C Kurumsal 8.2.19.90
Şekil 1. SQL özellikleri “Genel”

Şekil 2. SQL özellikleri “Gelişmiş”
Araçlar:
SQL sunucu profil oluşturucu
1C Sorgu Konsolu
Test İsteği:
SEÇME
AK Tanımı AS Tanımı
İTİBAREN
Bilgi Kaydı.AdresSınıflandırıcı AS AK
İÇ BAĞLANTI Bilgi Kaydı.AdresSınıflandırıcı AS AK1
Yazılım AK.code = AK1.code
Eğitim:
SQL server Profiler'ı başlatıyoruz, bağlantı kuruyoruz, olayları ve sütunları Şekil 3'te gösterildiği gibi işaretliyoruz.

Şekil 3. İz özellikleri
Veritabanımız için seçimi belirledik
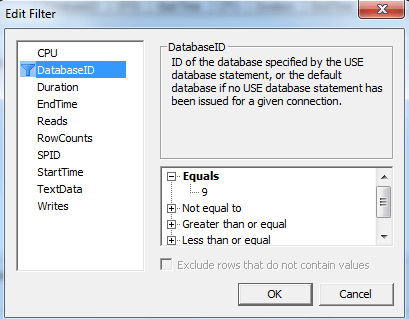
Şekil 4. Tabana göre filtreleme
Kısaltmalar:
Maksimum paralellik derecesi - MDOP
Paralellik için maliyet eşiği - maliyet
Sıralı sorgu planını test etme (MDOP = 1)

Şekil 5. Sorgu konsolu - yürütme süresi 20 sn.
SQL Server parametresi "Maks paralellik derecesi" 1'e ayarlanmıştır (paralellik yok). Sonucu profil oluşturucuda görün (Şekil 6)

Şekil 6. Sıralı sorgu planı
SQL sunucusu sıralı bir sorgu planı oluştururken: toplam CPU yükü = 6.750 (sn) ve sorguyu yürütme süresi = 7.097 (sn)
Paralel Sorgu Planını Test Etme (MDOP = 0, maliyet = 5)
SQL sunucusunu paralellik moduna alıyoruz (SQL Query'de):
KULLANIM ustası;
EXEC sp_configure "gelişmiş seçeneği göster", 1;
OVERRIDE İLE YENİDEN YAPILANDIR
KULLANIM ustası;
exec sp_configure "maksimum paralellik derecesi", 0;
OVERRIDE İLE YENİDEN YAPILANDIR
Aynı isteği yerine getiriyoruz (Şekil 7)

Şekil 7. Sorgu konsolu - yürütme süresi 16 sn.
Profil oluşturucuda sonucun kontrol edilmesi (Şekil 8)

Şekil 8. Paralel sorgulama planı
Bu sefer, SQL sunucusu, toplam CPU yükü = 7.905 saniye ve sorgu yürütme süresi = 3.458 saniye ile paralel bir sorgu planı oluşturdu.
Sıralı sorgu planını test etme (MDOP = 0, maliyet = 150)
Paralellik için maliyet eşiği parametresini kullanarak paralel plandan kurtulmaya çalışalım. Varsayılan olarak parametre 5'e ayarlanmıştır. Bizim durumumuzda 150 değerinde paralel bir plan oluşumundan kurtulmayı başardık (SQL Sorgusunda):
KULLANIM ustası;
exec sp_configure "paralellik için maliyet eşiği", 150 ;
Bu koşullarda isteğin yürütülmesini kontrol ediyoruz (Şekil 9)

Şekil 9. Sorgu konsolu - yürütme süresi 20 sn.
Profil oluşturucuda sonucun kontrol edilmesi (Şekil 10)

Şekil 10. Sıralı sorgu planı.
SQL Server sıralı bir sorgu planı oluşturdu. Toplam CPU yükü = 7.171 sn, sorgu yürütme süresi = 7.864 sn.
Sonuçlar:
1C Enterprise ortamında bir paralel sorgu planının SQL sunucusu kullanılarak bir test sorgusunun yürütülmesi, sıralı bir plana kıyasla önemli bir performans artışı sağlar (16 saniyeye karşı 20 saniye - 4 saniyelik bir kazanç)
· Bir paralel sorgu planı kullanılırken SQL sunucusunun kendisi tarafından bir test sorgusunun yürütülmesi, sıralı bir sorgu planı kullanıldığında iki kat daha hızlıdır (3,5 saniyeye karşı 7,1 saniye)
· SQL server paralelliği sadece MDOP parametresi kullanılarak değil, aynı zamanda "Paralellik için maliyet eşiği" parametresi kullanılarak da ayarlanabilir