Maximálny stupeň rovnobežnosti (DOP) je pokročilá možnosť konfigurácie servera SQL Server, ktorá má mnoho otázok a bola popísaná v mnohých publikáciách. V tomto blogovom príspevku autor dúfa, že poskytne jasnú predstavu o tom, čo táto možnosť robí a ako ju používať.
Po prvé, autor by chcel rozptýliť všetky pochybnosti, že vyššie uvedená možnosť určuje, koľko CPU môže server SQL Server použiť pri obsluhe viacerých pripojení (alebo používateľov) - nie je! Ak má server SQL Server prístup k štyrom neaktívnym procesorom a je nakonfigurovaný na používanie všetkých štyroch procesorov, použije všetky štyri procesory bez ohľadu na maximálny stupeň paralelnosti.
Čo teda robí táto možnosť? Táto možnosť nastavuje maximálny počet procesorov, ktoré môže server SQL Server použiť na jeden dotaz. Ak dotaz na server SQL Server musí vrátiť veľké množstvo údajov (veľa záznamov), niekedy má zmysel ich paralelizovať a rozdeliť na niekoľko malých dopytov, z ktorých každý vráti vlastnú podmnožinu riadkov. SQL Server teda môže používať viacero procesorov, a preto vo viacprocesorových systémoch je potenciálne možné vrátiť veľký počet celých záznamov dotazov rýchlejšie ako v systéme s jedným procesorom.
Existuje mnoho kritérií, ktoré musí byť splnených, kým SQL Server vyvolá „Intra Query Parallelism“, a nemá zmysel ich tu podrobne rozpisovať. V BOL ich nájdete vyhľadaním výrazu „stupeň rovnobežnosti“. Hovorí sa, že rozhodnutie o paralelizácii je založené na dostupnosti pamäte procesoru a najmä na dostupnosti samotných procesorov.
Prečo by sme teda mali zvažovať použitie tejto možnosti - pretože ponechanie predvolenej hodnoty (samotný server SQL Server sa rozhodne paralelizovať) môže niekedy mať nežiaduce účinky. Tieto efekty vyzerajú asi takto:
Paralelizované dopyty sú pomalšie.
Čas vykonania požiadaviek môže byť nedeterministický, čo môže používateľov obťažovať. Čas vykonania sa môže zmeniť, pretože:
Dopyt môže byť niekedy paralelizovaný a niekedy nie.
Žiadosť môže byť zablokovaná paralelnou požiadavkou, ak boli procesory predtým preťažené prácou.
Predtým, ako budeme pokračovať, by autor rád poukázal na to, že nie je potrebné konkrétne sa ponoriť do vnútorností paralelnosti. Ak vás to zaujíma, môžete si prečítať článok „Paralelné spracovanie dopytov“ v Books on Line, ktorý tieto informácie poskytuje podrobnejšie. Autor sa domnieva, že o vnútornej organizácii paralelizmu je potrebné vedieť iba dve dôležité veci:
Paralelné dopyty môžu vytvárať viac vlákien, ako je uvedené v možnosti „Maximálny stupeň rovnobežnosti“. DOP 4 môže vytvoriť viac ako dvanásť vlákien, štyri pre dotaz a ďalšie vlákna používané pre triedenia, vlákna, agregáty a zostavy atď.
Paralelizačné požiadavky môžu spôsobiť, že rôzne SPID budú čakať s typom čakania CXPACKET alebo 0X0200. To možno použiť na nájdenie tých SPID, ktoré čakajú na súbežné operácie a majú typ servera: CXPACKET v sysprocesoch. Na uľahčenie tejto úlohy autor navrhuje použiť uloženú procedúru na svojom blogu: track_waitstats.
A tak „Prečo môže dotaz bežať pomalšie, keď je paralelizovaný“ prečo?
Ak má systém veľmi nízku priepustnosť diskových subsystémov, potom pri analýze požiadavky môže jeho rozklad trvať dlhšie ako bez rovnobežnosti.
Možné skreslenie údajov alebo zablokovanie rozsahov údajov pre procesor, spôsobené iným paralelne použitým a neskôr spusteným procesom atď.
Ak pre predikát neexistuje žiadny index, čo má za následok skenovanie tabuľky. Paralelná prevádzka v rámci dotazu môže zakryť skutočnosť, že dotaz by bežal oveľa rýchlejšie s plánom sekvenčného vykonávania a so správnym indexom.
Z toho všetkého vyplýva odporúčanie skontrolovať vykonanie požiadavky bez rovnobežnosti (DOP = 1), čo pomôže identifikovať možné problémy.
Vyššie uvedené efekty rovnobežnosti by vás mali samy osebe priviesť k myšlienke, že vnútorná mechanika rovnobežných dotazov nie je vhodná na použitie v aplikáciách OLTP. Ide o aplikácie, pre ktoré môže byť zmena času vykonávania dotazov pre používateľov nepríjemná a u ktorých server obsluhujúci viacerých používateľov pravdepodobne nevyberie plán paralelného vykonávania kvôli vlastnému profilu pracovného zaťaženia procesora týchto aplikácií.
Ak teda budete používať paralelnosť, bude to s najväčšou pravdepodobnosťou potrebné pre úlohy extrakcie údajov (dátový sklad), podporu rozhodovania alebo systémy podávania správ, kde nie je veľa požiadaviek, ale sú dosť náročné a bežia na výkonnom serveri s veľkým množstvom operačnej pamäte.
Ak sa rozhodnete používať súbežnosť, akú hodnotu by ste mali nastaviť pre DOP? Pre tento mechanizmus je osvedčenou praxou, že ak máte 8 procesorov, nastavte DOP = 4 a toto je s najväčšou pravdepodobnosťou optimálne nastavenie. Neexistuje však žiadna záruka, že to bude fungovať týmto spôsobom. Jediným spôsobom, ako si to byť istý, je otestovať rôzne hodnoty DOP. Okrem toho chcel autor ponúknuť svoje empirické rady, aby nikdy tento počet nestanovoval viac ako polovicu počtu dostupných procesorov. Ak by mal autor menej ako šesť procesorov, nastavil by DOP na 1, čo jednoducho znemožňuje paralelizáciu. Výnimku by mohol urobiť, ak by mal databázu, ktorá podporuje iba jeden používateľský proces (niektoré technológie extrakcie údajov alebo úlohy hlásenia), v tomto prípade bude ako výnimku možné nastaviť DOP na 0 (predvolená hodnota), čo umožňuje Je na serveri SQL Server, aby rozhodol o potrebe paralelizácie dotazu.
Pred ukončením článku vás chcel autor upozorniť, že paralelné vytváranie indexov závisí od čísla, ktoré nastavíte pre DOP. To znamená, že ho možno budete chcieť zmeniť v čase vytvárania alebo opätovného vytvárania indexu, aby sa zlepšil výkon tejto operácie, a samozrejme môžete v dotaze použiť nápovedu MAXDOP, ktorá vám umožní ignorovať nastavenú hodnotu. v konfigurácii a môže byť použitý mimo prevádzkových hodín. ...
Nakoniec sa vaša požiadavka môže pri paralelizácii kvôli chybám spomaliť, preto sa uistite, že máte na serveri nainštalovaný najnovší balík service pack.
| VYTVORIŤ proc track_waitstats (@num_samples int = 10 , @ delaynum int = 1 , @ delaytype nvarchar ( 10 ) = "minúty") AS - T. Davidson - Táto uložená procedúra je poskytovaná = TAK AKO JE = bez akýchkoľvek záruk,- a nepreberá žiadne práva. - Použitie zahrnutých ukážok skriptu podlieha podmienkam - uvedené na stránke http://www.microsoft.com/info/cpyright.htm - @num_samples je počet zachytení štatistík čakania, - predvolené je 10 krát. predvolený interval oneskorenia je 1 minúta - delaynum je interval oneskorenia. delaytype určuje, či - interval oneskorenia je minúty alebo sekundy - vytvorte tabuľku waitstats, ak neexistuje, inak skráťte zapnúť nocount, ak neexistuje (vyberte 1 zo sysobjects kde name = "waitstats") vytvorte tabuľku waitstats (varchar ( 80 ), požaduje číselné ( 20 ,1 ), numerický ( 20 ,1 ), numerický ( 20 ,1 ), teraz datetime default getdate ()) else skrátiť tabuľku waitstats dbcc sqlperf (waitstats, vymazať) - vymazať waitstats deklarovať @i int, @ oneskorenie varchar ( 8 ), @ dt varchar ( 3 ), @ now datetime, @ totalwait numeric ( 20 ,1 ), @ endtime datetime, @ begintime datetime, @ hr int, @ min int, @ sec int select @i = 1 vyberte @dt = malé písmená ( @typ oneskorenia), keď „minúty“, potom „m“, keď „minúty“, potom „m“, keď „min“, potom „m“, keď „mm“, potom „m“, keď „mi“ potom „m“ keď „m“ potom „m“ keď „sekundy“ potom „s“ keď „sekunda“ potom „s“ keď „s“ potom „s“ keď „ss“ potom „s“ keď „s“ potom „s“ iné @ delaytype end, ak @dt nie je v ("s", "m") začne tlač „Zadajte typ oneskorenia, napr. sekundy alebo minúty“ vrátiť koniec, ak začne @dt = "s" vyberte @sec = @delaynum% 60 vyberte @min = cast ((@delaynum / 60 ) ako int) vyberte @hr = cast ((@min / 60 ) ako int) vyberte @min = @min% 60 end if @dt = "m" begin select @sec = 0 vyberte @min = @delaynum% 60 vyberte @hr = cast ((@delaynum / 60 ) ako int) end vyberte @delay = vpravo ("0" + previesť (varchar ( 2 ), @ hod), 2 2 ), @ min), 2 ) + ":" + + vpravo ("0" + previesť (varchar ( 2 ), @ s), 2 ) if @hr> 23 alebo @min> 59 alebo @s> 59 začať vyberať "hh: mm: ss čas oneskorenia nemôže> 23:59:59" vyberte „Interval oneskorenia a zadajte:“ + previesť (varchar ( 10 ), @delaynum) + "," + @delaytype + "sa zmení na" + @delay návratový koniec, kým (@i<= @num_samples) begin insert into waitstats (, requests, ,) exec ("dbcc sqlperf(waitstats)" ) select @i = @i + 1 čakať na oneskorenie @koniec oneskorenia --- vytvoriť správu o stave čakania, vykonať príkaz get_waitstats --//--//--//--//--//--//--//--//--//-//--//--//--//--//--//--//--//--/ VYTVORIŤ proc get_waitstats AS - Táto uložená procedúra je poskytovaná = AKO JE = bez akýchkoľvek záruk a- nepreberá žiadne práva. - Použitie zahrnutých ukážok skriptu podlieha stanoveným podmienkam - na stránke http://www.microsoft.com/info/cpyright.htm -- - tento postup vytvorí zostavu waitstats so zoznamom typov čakania podľa- percento - je možné spustiť, keď sa vykonáva track_waitstats nastaviť nocount na declare @ now datetime, @ totalwait numeric ( 20 ,1 ), @ endtime datetime, @ begintime datetime, @ hr int, @ min int, @ sec int select @ now = max (now), @ begintime = min (now), @ endtime = max (now) from waitstats where = " Celkom " --- odpočítajte čakanie, spánok a zdrojový rad od súčtu vyberte @totalwait = sum () + 1 z poradovníkov, kde nie sú („WAITFOR“, „SLEEP“, „RESOURCE_QUEUE“, „Total“, „*** total ***“) a teraz = @now - vložte upravené súčty, zostupne podľa percenta vymazať waitstats kde = "*** celkom ***" a teraz = @teraz vložiť do waitstats vybrať "*** celkom ***", 0 , @ totalwait, @ totalwait, @ teraz zvoľte ,, percento = cast ( 100 * / @ totalwait ako numerické ( 20 ,1 )) z poradovníka, kde nie je („WAITFOR“, „SLEEP“, „RESOURCE_QUEUE“, „Total“) a teraz = @teraz poradie podľa percentuálneho zostupu |
Maximálny stupeň rovnobežnosti (DOP) je pokročilá možnosť konfigurácie servera SQL Server, ktorá má mnoho otázok a bola popísaná v mnohých publikáciách. V tomto blogovom príspevku autor dúfa, že poskytne jasnú predstavu o tom, čo táto možnosť robí a ako ju používať.
Po prvé, autor by chcel rozptýliť všetky pochybnosti, že vyššie uvedená možnosť určuje, koľko CPU môže server SQL Server použiť pri obsluhe viacerých pripojení (alebo používateľov) - nie je! Ak má server SQL Server prístup k štyrom neaktívnym procesorom a je nakonfigurovaný na používanie všetkých štyroch procesorov, použije všetky štyri procesory bez ohľadu na maximálny stupeň paralelnosti.
Čo teda robí táto možnosť? Táto možnosť nastavuje maximálny počet procesorov, ktoré môže server SQL Server použiť na jeden dotaz. Ak dotaz na server SQL Server musí vrátiť veľké množstvo údajov (veľa záznamov), niekedy má zmysel ich paralelizovať a rozdeliť na niekoľko malých dopytov, z ktorých každý vráti vlastnú podmnožinu riadkov. Server SQL Server teda môže používať viacero procesorov, a preto vo viacprocesorových systémoch je potenciálne možné vrátiť veľký počet celých záznamov dotazov rýchlejšie ako v systéme s jedným procesorom.
Existuje mnoho kritérií, ktoré musí byť splnených, než SQL Server vyvolá „Intra Query Parallelism“, a nemá zmysel ich tu podrobne rozpisovať. V BOL ich nájdete vyhľadaním výrazu „stupeň rovnobežnosti“. Hovorí sa, že rozhodnutie o paralelizácii je založené na dostupnosti pamäte procesoru a najmä na dostupnosti samotných procesorov.
Prečo by sme teda mali zvažovať použitie tejto možnosti - pretože ponechanie predvolenej hodnoty (samotný server SQL Server sa rozhodne paralelizovať) môže niekedy mať nežiaduce účinky. Tieto efekty vyzerajú asi takto:
- Paralelizované dopyty sú pomalšie.
- Čas vykonania požiadaviek môže byť nedeterministický a to môže používateľov obťažovať. Čas vykonania sa môže zmeniť, pretože:
- Dopyt môže byť niekedy paralelizovaný a niekedy nie.
- Žiadosť môže byť zablokovaná paralelnou požiadavkou, ak boli procesory predtým preťažené prácou.
Predtým, ako budeme pokračovať, by autor rád poukázal na to, že nie je potrebné konkrétne sa ponoriť do vnútorností paralelnosti. Ak vás to zaujíma, môžete si prečítať článok „Paralelné spracovanie dopytov“ v Books on Line, ktorý tieto informácie poskytuje podrobnejšie. Autor sa domnieva, že o vnútornej organizácii paralelizmu je potrebné vedieť iba dve dôležité veci:
- Paralelné dopyty môžu vytvárať viac vlákien, ako je uvedené v možnosti „Maximálny stupeň rovnobežnosti“. DOP 4 môže vytvoriť viac ako dvanásť vlákien, štyri pre dotaz a ďalšie vlákna používané pre triedenia, vlákna, agregáty a zostavy atď.
- Paralelizačné požiadavky môžu spôsobiť, že rôzne SPID budú čakať s typom čakania CXPACKET alebo 0X0200. To možno použiť na nájdenie tých SPID, ktoré čakajú na súbežné operácie a majú typ servera: CXPACKET v sysprocesoch. Na uľahčenie tejto úlohy autor navrhuje použiť uloženú procedúru vo svojom blogu: track_waitstats.
A tak „Prečo môže dotaz bežať pomalšie, keď je paralelizovaný“ prečo?
- Ak má systém veľmi nízku priepustnosť diskových subsystémov, potom pri analýze požiadavky môže jeho rozklad trvať dlhšie ako bez rovnobežnosti.
- Možné skreslenie údajov alebo zablokovanie rozsahov údajov pre procesor, spôsobené iným paralelne použitým a neskôr spusteným procesom atď.
- Ak pre predikát neexistuje žiadny index, čo má za následok skenovanie tabuľky. Paralelná prevádzka v rámci dotazu môže zakryť skutočnosť, že dotaz by bežal oveľa rýchlejšie s plánom sekvenčného vykonávania a so správnym indexom.
Vyššie uvedené efekty rovnobežnosti by vás mali samy osebe priviesť k myšlienke, že vnútorná mechanika rovnobežných dotazov nie je vhodná na použitie v aplikáciách OLTP. Ide o aplikácie, pre ktoré môže byť zmena času vykonávania dotazov pre používateľov nepríjemná a pre ktoré server obsluhujúci viacerých používateľov pravdepodobne nezvolí plán paralelného vykonávania kvôli vlastnému profilu pracovného zaťaženia procesora týchto aplikácií.
Ak teda budete používať paralelnosť, bude to s najväčšou pravdepodobnosťou potrebné pre úlohy extrakcie údajov (dátový sklad), podporu rozhodovania alebo systémy podávania správ, kde nie je veľa požiadaviek, ale sú dosť náročné a bežia na výkonnom serveri s veľkým množstvom operačnej pamäte.
Ak sa rozhodnete používať súbežnosť, akú hodnotu by ste mali nastaviť pre DOP? Pre tento mechanizmus je osvedčenou praxou, že ak máte 8 procesorov, nastavte DOP = 4 a toto je s najväčšou pravdepodobnosťou optimálne nastavenie. Neexistuje však žiadna záruka, že to bude fungovať týmto spôsobom. Jediným spôsobom, ako si to byť istý, je otestovať rôzne hodnoty DOP. Okrem toho chcel autor ponúknuť svoje empirické rady, aby nikdy tento počet nestanovoval viac ako polovicu počtu dostupných procesorov. Ak by mal autor menej ako šesť procesorov, nastavil by DOP na 1, čo jednoducho znemožňuje paralelizáciu. Výnimku by mohol urobiť, ak by mal databázu, ktorá podporuje iba jeden používateľský proces (niektoré technológie extrakcie údajov alebo úlohy hlásenia), v tomto prípade bude ako výnimku možné nastaviť DOP na 0 (predvolená hodnota), čo umožňuje Je na serveri SQL Server, aby rozhodol o potrebe paralelizácie dotazu.
Pred ukončením článku vás chcel autor upozorniť, že paralelné vytváranie indexov závisí od čísla, ktoré nastavíte pre DOP. To znamená, že ho možno budete chcieť zmeniť v čase vytvárania alebo opätovného vytvárania indexu, aby sa zlepšil výkon tejto operácie, a samozrejme môžete v dotaze použiť nápovedu MAXDOP, ktorá vám umožní ignorovať nastavenú hodnotu. v konfigurácii a môže byť použitý mimo prevádzkových hodín. ...
Nakoniec sa vaša požiadavka môže pri paralelizácii kvôli chybám spomaliť, preto sa uistite, že máte na serveri nainštalovaný najnovší balík service pack.
REATE proc track_waitstats@num_samples int = 10
, @ delaynum int = 1
, @ delaytype nvarchar ( 10 ) = "minúty"
AS
- T. Davidson
- Táto uložená procedúra je poskytovaná = TAK AKO JE = bez akýchkoľvek záruk,
- a nepreberá žiadne práva.
- Použitie zahrnutých ukážok skriptu podlieha podmienkam
- uvedené na stránke http://www.microsoft.com/info/cpyright.htm
- @num_samples je počet zachytení štatistík čakania,
- predvolené je 10 krát. predvolený interval oneskorenia je 1 minúta
- delaynum je interval oneskorenia. delaytype určuje, či
- interval oneskorenia je minúty alebo sekundy
- vytvorte tabuľku waitstats, ak neexistuje, inak skráťte
nastaviť nezapočítanie
ak neexistuje (vyberte 1
zo sysobjects kde name = "waitstats")
vytvoriť tabuľku waitstats (varchar ( 80
),
požaduje číselné ( 20
,1
),
numerický ( 20
,1
),
numerický ( 20
,1
),
teraz predvolený dátum a čas getdate ())
inak skrátiť tabuľku čakacích štatistík
dbcc sqlperf (waitstats, clear) - vymazanie waitstats
vyhlásiť @i int
, @ delay varchar ( 8
)
, @ dt varchar ( 3
)
, @ teraz datetime
, @ totalwait numeric ( 20
,1
)
, @ endtime datetime
, @ počiatočný dátum
, @ hod int
, @ min int
, @ s int
vyberte @i = 1
vyberte @dt = malé písmená (@delaytype)
keď „minúty“, potom „m“
keď „minúta“, potom „m“
keď „min“, potom „m“
keď „mm“, potom „m“
keď „mi“, tak „m“
keď „m“, tak „m“
keď „sekundy“, potom „s“
keď „druhé“, potom „s“
keď „s“, potom „s“
keď „ss“, potom „s“
keď "s" potom "s"
inak @delaytype
koniec
ak @dt nie je v („s“, „m“)
začať
vytlačiť „Zadajte typ oneskorenia, napr. sekundy alebo minúty“
vrátiť sa
koniec
ak @dt = "s"
začať
vyberte @sec = @delaynum% 60
vyberte @min = cast ((@delaynum / 60
) ako int)
vyberte @hr = cast ((@min / 60
) ako int)
vyberte @min = @min% 60
koniec
ak @dt = "m"
začať
vyberte @sec = 0
vyberte @min = @delaynum% 60
vyberte @hr = cast ((@delaynum / 60
) ako int)
koniec
vyberte @delay = vpravo ("0" + previesť (varchar ( 2
), @ hod), 2
) + ":"
+
2
), @ min), 2
) + ":"
+
+ vpravo ("0" + previesť (varchar ( 2
), @ s), 2
)
ak @hr> 23
alebo @min> 59
alebo @s> 59
začať
vyberte "hh: mm: ss čas oneskorenia nemôže> 23:59:59"
vyberte „Interval oneskorenia a zadajte:“ + previesť (varchar ( 10
)
, @ delaynum) + "," + @delaytype + "previesť na"
+ @oneskorenie
vrátiť sa
koniec
kým<= @num_samples)
začať
vložiť do waitstats (, žiadosti,
,)
exec ("dbcc sqlperf (waitstats)")
vyberte @i = @i + 1
čakať na oneskorenie @oneskorenie
Koniec
Vytvorte prehľad čakacej doby
spustite príkaz get_waitstats
--//--//--//--//--//--//--//--//--//-//--//--//--//--//--//--//--//--/
VYTVORTE proc get_waitstats
AS
- Táto uložená procedúra je poskytovaná = AKO JE = bez akýchkoľvek záruk a
- nepreberá žiadne práva.
- Použitie zahrnutých ukážok skriptu podlieha stanoveným podmienkam
- na stránke http://www.microsoft.com/info/cpyright.htm
--
- tento postup vytvorí zostavu waitstats so zoznamom typov čakania podľa
- percento
- je možné spustiť, keď sa vykonáva track_waitstats
nastaviť nezapočítanie
vyhlásiť @teraz za dátum
, @ totalwait numeric ( 20
,1
)
, @ endtime datetime
, @ počiatočný dátum
, @ hod int
, @ min int
, @ s int
vyberte @ teraz = max (teraz), @ začiatok = min (teraz), @ koniec = = (teraz)
from waitstats where = "Total"
Od Total odpočítajte čakanie, spánok a zdrojový rad
vyberte @totalwait = sum () + 1
z poradovníka
kde nie je („WAITFOR“, „SLEEP“, „RESOURCE_QUEUE“
„Celkom“, „*** celkom ***“) a teraz = @teraz
Vložte upravené súčty, zostupne podľa percenta
vymažte waitstats, kde = "*** celkom ***" a teraz = @teraz
vložte do poradovníka zvoľte „*** celkom ***“
,0
, @ totalwait
, @ totalwait
, @ teraz
vyberte
,
, percento = obsadenie ( 100
* / @ totalwait ako numerické ( 20
,1
))
z poradovníka
kde nie je („WAITFOR“, „SLEEP“, „RESOURCE_QUEUE“, „Total“)
a teraz = @teraz
zoradenie podľa percentuálneho zostupu
Optimalizácia práce 1C. Konfigurácia MS SQL Server
Povoliť inicializáciu okamžitého súboru databázy
- Vytvorenie databázy
- Pridajte súbory, protokoly alebo údaje do existujúcej databázy
- Zväčšiť veľkosť existujúceho súboru (vrátane operácií automatického zväčšenia)
- Obnovenie databázy alebo skupiny súborov
Povolenie nastavenia:
- V počítači, kde sa vytvorí záložný súbor, otvorte aplikáciu Local Security Policy (secpol.msc).
- Rozbaľte uzol Miestne politiky na ľavom paneli a potom kliknite na položku Priradenie práv používateľa.
- Na pravom paneli dvakrát kliknite na položku Vykonať úlohy údržby hlasitosti.
- Kliknite na tlačidlo „Pridať“ pre používateľa alebo skupinu a pridajte sem používateľa, pod ktorým je spustený server MS SQL Server.
- Kliknite na tlačidlo Použiť.
Zapnite Uzamknúť stránky v pamäti
Toto nastavenie určuje, ktoré účty môžu ukladať údaje do pamäte RAM, aby systém neposielal dátové stránky do virtuálnej pamäte na disku, čo môže zlepšiť výkon.
Povolenie nastavenia:
- V ponuke Štart vyberte položku Spustiť. Do poľa Otvoriť zadajte gpedit.msc.
- V konzole editora miestnych zásad skupiny rozbaľte položku Konfigurácia počítača a potom Konfigurácia systému Windows.
- Rozbaľte Nastavenia zabezpečenia a Miestne zásady.
- Vyberte priečinok Priradenie práv používateľa.
- Politiky sa zobrazia na table s podrobnosťami.
- Na tomto paneli dvakrát kliknite na možnosť Uzamknúť stránky v pamäti.
- V dialógovom okne Local Security Option - Lock Pages In Memory vyberte položku Add a user or group.
- V dialógovom okne Vybrať: Používatelia, Účty služby alebo Skupiny pridajte konto, pod ktorým spustíte službu MS SQL Server.
- Aby sa zmeny prejavili, reštartujte server alebo sa prihláste k užívateľovi, pod ktorým máte spustený MS SQL Server.
Zakážte DFSS pre jednotky.
Dynamic Fair Share Scheduling je zodpovedný za vyváženie a distribúciu hardvérových zdrojov medzi používateľmi. Niekedy môže jeho práca negatívne ovplyvniť výkon 1C. Ak ho chcete zakázať iba pre disky, musíte:
- V registri vyhľadajte vetvu HKEY_LOCAL_MACHINE \ SYSTEM \ CurrentControlSet \ Services \ TSFairShare \ Disk
- Nastavte hodnotu parametra EnableFairShare na 0
Vypnite kompresiu údajov pre adresáre obsahujúce databázové súbory.
Keď je povolená kompresia, OS sa pokúsi spracovať ďalšie súbory počas úpravy, čo spomalí samotný proces napaľovania, ale ušetrí miesto.
Ak chcete zakázať kompresiu súborov v adresári, musíte:
- Vlastnosti otvoreného adresára
- Na karte Všeobecné kliknite na tlačidlo Iné
- Ak chcete ušetriť miesto na disku, zrušte začiarknutie políčka „Komprimovať“.
Nastavte maximálny stupeň rovnobežnosti na 1.
Tento parameter určuje, na koľkých vláknach je možné vykonať jednu požiadavku. Štandardne je parameter 0, čo znamená, že server sám vyberie počet vlákien. Pre bázy so záťažovou charakteristikou 1C sa odporúča nastaviť tento parameter na 1, pretože vo väčšine prípadov to bude mať pozitívny vplyv na výkon dotazov.
Na konfiguráciu parametra musíte:
- Otvorte vlastnosti servera a vyberte kartu Rozšírené
- Nastavte hodnotu parametra na jednu.
Obmedzte maximálnu veľkosť pamäte MS SQL Server.
Pamäť pre MS SQL Server = Pamäť všetkých - Pamäť pre OS - Pamäť pre 1C server
Server má napríklad 64 GB pamäte RAM, musíte pochopiť, koľko pamäte alokovať na server DBMS, aby stačil server 1C.
Na normálnu prevádzku OS sú vo väčšine prípadov 4 GB viac než dosť, zvyčajne 2 až 3 GB.
Ak chcete určiť, koľko pamäte je potrebné pre server 1C, musíte vidieť, koľko pamäte zaberajú procesy serverového klastra uprostred pracovného dňa. Tieto procesy sú ragent, rmngr a rphost, tieto procesy sú podrobne prediskutované v časti o serverovom klastri. Údaje je potrebné brať presne v období vrcholnej pracovnej aktivity, keď v databáze pracuje maximálny počet používateľov. Po prijatí týchto údajov je potrebné k nim pridať 1 GB - v prípade spustenia „ťažkých“ operácií v 1C.
Ak chcete nastaviť maximálne množstvo pamäte využívanej serverom MS SQL Server, musíte:
- Spustite Management Studio a pripojte sa k požadovanému serveru
- Otvorte vlastnosti servera a vyberte kartu Pamäť
- Zadajte hodnotu pre parameter Maximálna veľkosť pamäte servera.
Povoľte príznak priority servera Boost SQL Server.
Tento príznak vám umožňuje zvýšiť prioritu procesu MS SQL Server pred inými procesmi.
Povolenie príznaku má zmysel iba vtedy, ak server 1C nie je nainštalovaný v počítači so serverom DBMS.
Na nastavenie vlajky potrebujete:
- Spustite Management Studio a pripojte sa k požadovanému serveru
- Otvorte vlastnosti servera a vyberte kartu Procesory
- Povoľte príznak „Zvýšte prioritu servera SQL Server“ a kliknite na tlačidlo OK.
Nastavte veľkosť automaticky rastúcich databázových súborov.
Autogrowth vám umožňuje určiť množstvo, o ktoré sa veľkosť súboru databázy zvýši, keď je plný. Ak nastavíte príliš malú veľkosť automatického rozbalenia, súbor sa bude rozťahovať príliš často, čo bude nejaký čas trvať. Odporúča sa nastaviť hodnotu medzi 512 MB a 5 GB.
- Spustite Management Studio a pripojte sa k požadovanému serveru
- Naproti každému súboru v stĺpci Automatické zvýšenie zadajte požadovanú hodnotu
Toto nastavenie bude účinné iba pre vybranú základňu. Ak chcete, aby toto nastavenie bolo účinné pre všetky základne, musíte vykonať rovnaké kroky pre základný model služby. Potom budú mať všetky novovytvorené základne rovnaké nastavenia ako základňa modelu.
Rozbaľte súbory mdf a súbory denníka ldf na rôzne fyzické disky.
V tomto prípade môže práca so súbormi prebiehať nie postupne, ale prakticky paralelne, čo zvyšuje rýchlosť operácií na disku. Na tieto účely sú najvhodnejšie disky SSD.
Na prenos súborov potrebujete:
- Spustite Management Studio a pripojte sa k požadovanému serveru
- Otvorte vlastnosti požadovanej databázy a vyberte kartu Súbory
- Zapamätajte si názvy a umiestnenia súborov
- Odpojte základňu výberom položky Úlohy - Odpojiť z kontextového menu
- Nastavte príznak Odstrániť pripojenia a kliknite na tlačidlo OK
- Otvorte program Explorer a presuňte dátový súbor a súbor denníka na požadované médium
- V aplikácii Management Studio otvorte kontextovú ponuku servera a vyberte položku Pripojiť základnú položku
- Kliknite na tlačidlo Pridať a zadajte súbor mdf z nového disku
- V dolnom okne informácií o databáze v riadku so súborom denníka musíte zadať novú cestu k súboru denníka transakcií a kliknúť na tlačidlo OK.
ROZSAH TOHTO ČLÁNKU: SQL Server (od roku 2008) Azure SQL Database Azure SQL Data WarehouseParallel Data Warehouse
Táto časť popisuje konfiguráciu možnosti konfigurácie servera maximálny stupeň rovnobežnosti (MAXDOP) v SQL Server 2016 pomocou SQL Server Management Studio alebo Transact-SQL. Keď je inštancia servera SQL Server spustená na viacprocesorovom počítači, určuje optimálny stupeň paralelnosti, to znamená počet procesorov použitých na vykonanie jedného príkazu pre každý z plánov paralelného vykonávania. Na obmedzenie počtu procesorov z hľadiska paralelného vykonávania je možné použiť tento parameter maximálny stupeň rovnobežnosti... SQL Server zvažuje plány paralelného vykonávania pre dopyty, operácie DDL indexu, paralelné vloženia, online aktualizácie stĺpcov, zber paralelných štatistík a naplnenie statických kurzorov a kurzorov sady kľúčov.
Obmedzenia
- Keď je nastavená na inú ako predvolenú masku afinity, môže obmedziť počet procesorov dostupných pre server SQL Server na systémoch symetrického viacprocesora (SMP).
Toto nastavenie je voliteľné a mali by ho meniť iba skúsení technici DBA alebo certifikovaní technici SQL Servera.
Aby server mohol určiť maximálny stupeň rovnobežnosti, nastavte tento parameter na 0, čo je predvolené nastavenie. Nastavenie maximálneho stupňa rovnobežnosti na 0 umožňuje serveru SQL Server používať všetky dostupné procesory (až 64 procesorov). Ak chcete zakázať vytváranie paralelných plánov, nastavte parameter maximálny stupeň rovnobežnosti hodnota 1. Zadajte hodnotu pre parameter od 1 do 32 767, aby ste určili maximálny počet jadier procesora, ktoré je možné použiť v jednom dotaze. Ak je zadaná hodnota, ktorá presahuje počet dostupných procesorov, použije sa skutočný počet dostupných procesorov. Ak má počítač iba jeden procesor, potom hodnotu parametra maximálny stupeň rovnobežnosti nebudú započítané.
Parameter maximálneho stupňa rovnobežnosti je možné prepísať zadaním dotazu MAXDOP do príkazu. Ďalšie informácie nájdete v časti.
Vytváranie a prestavba indexov a zrušenie klastrovaného indexu môže byť náročné na zdroje. Parameter maximálneho stupňa rovnobežnosti pre indexové operácie môžete prepísať zadaním parametra indexu MAXDOP do príkazu. Hodnota MAXDOP je aplikovaná na príkaz za behu a nie je uložená v metaúdajoch indexu. Ďalšie informácie nájdete v článku.
Tento parameter okrem dotazov a indexových operácií riadi aj stupeň paralelnosti pri vykonávaní príkazov DBCC CHECKTABLE, DBCC CHECKDB a DBCC CHECKFILEGROUP. Plány paralelného vykonávania týchto príkazov je možné zakázať pomocou príznaku sledovania 2528. Ďalšie informácie nájdete v téme.
Zabezpečenie
Povolenia
Povolenia na spustenie uloženej procedúry sp_configure bez parametrov alebo iba s prvým parametrom v predvolenom nastavení sú k dispozícii všetkým používateľom. Na dokončenie postupu sp_configure pri oboch možnostiach musíte mať povolenie ALTER SETTINGS na úrovni servera, aby ste mohli zmeniť možnosť konfigurácie alebo spustiť príkaz RECONFIGURE. ALTER SETTINGS povolenie implicitne udelené preddefinovaným rolám servera sysadmin a správca servera .
V. objektový prehliadač kliknite pravým tlačidlom myši na server a zvoľte Vlastnosti.
Kliknite na uzol Navyše .
V poli Maximálny stupeň rovnobežnosti zadajte maximálny počet procesorov, ktoré je možné použiť v pláne paralelného vykonávania.
Nastavenie parametra maximálneho stupňa rovnobežnosti
Vytvorte spojenie s databázovým strojom.
Na paneli Štandardné kliknite na Vytvoriť žiadosť.
Skopírujte nasledujúci príklad do okna dotazu a kliknite na Vykonať... Tento príklad popisuje, ako použiť postup na nastavenie parametra maximálneho stupňa rovnobežnosti na 8.
USE AdventureWorks2012; GO EXEC sp_configure "zobraziť rozšírené možnosti", 1; PREJDETE KONFIGURÁCII S PREPISOM; GO EXEC sp_configure "maximálny stupeň rovnobežnosti", 8; PREJDETE KONFIGURÁCII S PREPISOM; Choď
Ďalšie informácie nájdete v článku
Cieľ: preštudujte si vplyv paralelizmu SQL na prácu s 1C dotazmi
Literatúra:
Testovacie prostredie:
Windows server 2008 R2 Enterprise
MS SQL server 2008 R2
1C Enterprise 8.2.19.90
Obrázok 1. Vlastnosti SQL „Všeobecné“

Obrázok 2. Vlastnosti SQL „pokročilé“
Nástroje:
Profilátor servera SQL
Konzola dotazu 1C
Žiadosť o test:
VYBERTE
Označenie AK Označenie AS
OD
Informácie Register.AddressClassifier AS AK
VNÚTORNÉ PRIPOJENIE Informácie Register.AddressClassifier AS AK1
Softvér AK.code = AK1.code
Príprava:
Spustíme SQL server Profiler, vytvoríme pripojenie, označíme udalosti a stĺpce, ako je znázornené na obrázku 3.

Obrázok 3. Vlastnosti stopy
Nastavili sme výber pre našu databázu
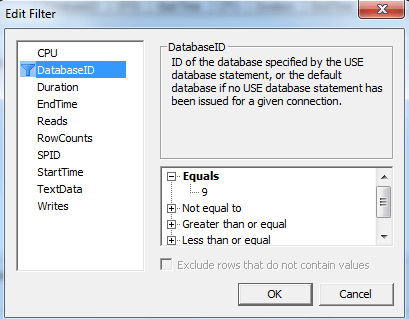
Obrázok 4. Filtrovať podľa základne
Skratky:
Maximálny stupeň rovnobežnosti - MDOP
Сost prah pre rovnobežnosť - náklady
Testovanie plánu sekvenčných dotazov (MDOP = 1)

Obrázok 5. Konzola dotazu - doba spustenia 20 sekúnd.
Parameter SQL Server „Maximálny stupeň rovnobežnosti“ je nastavený na 1 (bez rovnobežnosti). Výsledok si pozrite v profilovači (obr. 6)

Obrázok 6. Plán sekvenčných dotazov
Server SQL vygeneroval sekvenčný plán dotazov, pričom: celkové zaťaženie procesora = 6 750 (s) a čas na vykonanie dotazu = 7,097 (s)
Testovanie plánu paralelných dotazov (MDOP = 0, cena = 5)
Server SQL sme uviedli do režimu paralelnosti (v SQL Query):
POUŽIJTE majstra;
EXEC sp_configure "zobraziť rozšírenú možnosť", 1;
ZNOVUKONFIGURUJTE S PREPISOM
POUŽIJTE majstra;
exec sp_configure "maximálny stupeň rovnobežnosti", 0;
ZNOVUKONFIGURUJTE S PREPISOM
Vykonáme rovnakú požiadavku (obrázok 7)

Obrázok 7. Konzola dotazu - doba spustenia 16 s.
Kontrola výsledku v profilovači (obrázok 8)

Obrázok 8. Plán súbežných dotazov
Server SQL tentokrát vygeneroval paralelný plán dotazov s celkovým zaťažením procesora = 7,905 sekundy a trvaním vykonania dotazu = 3,458 sekundy
Testovanie plánu sekvenčných dotazov (MDOP = 0, cena = 150)
Skúsme sa zbaviť paralelného plánu pomocou parametra „Nákladová hranica pre rovnobežnosť“. Štandardne je parameter nastavený na 5. V našom prípade sa nám podarilo zbaviť sa vytvárania paralelného plánu na hodnote 150 (v SQL Query):
POUŽIJTE majstra;
exec sp_configure „prahová hodnota nákladov pre paralelnosť“, 150 ;
Za týchto podmienok kontrolujeme vybavenie žiadosti (obr. 9)

Obrázok 9. Konzola dotazu - doba spustenia 20 s.
Kontrola výsledku v profilovači (obr. 10)

Obrázok 10. Plán sekvenčných dotazov.
Server SQL Server vygeneroval plán sekvenčných dotazov. Celkové zaťaženie procesora = 7,171 s, doba vykonania dotazu = 7,864 s.
Závery:
Vykonanie testovacieho dotazu v prostredí 1C Enterprise pomocou servera SQL paralelného plánu dotazov prináša výrazné zvýšenie výkonu v porovnaní so sekvenčným plánom (16 sekúnd oproti 20 sekundám - nárast 4 sekundy)
· Vykonanie testovacieho dotazu samotným serverom SQL pri použití plánu paralelných dotazov je dvakrát rýchlejšie ako pri použití plánu sekvenčného dotazu (3,5 sekundy oproti 7,1 sekundy)
· Paralelizmus servera SQL je možné upraviť nielen pomocou parametra MDOP, ale aj parametra „Prahová hodnota pre paralelnosť“